 Stephanie Stoll
Stephanie StollThis log is introducing the development process and methods employed for creating a software control system for the hand prototype. The high-level control software’s aim is to make its own grasping choices, requiring only minimal human input. The grasp choice is then sent to the hand prototype’s previously discussed low-level API in order to be translated into motor commands. In later logs I will discuss the usage of Convolutional Neural Networks in the high-level control, as well as the data used to train the CNNs.
Design Considerations
One of the goals of this project is to significantly reduce the human input needed to operate the hand. Therefore, the control software should be able to operate on a minimal control signal of ‘open’ or ‘close hand’.
Given the low-cost nature of the hardware the sensory information is limited. The control software needs to make maximum use of this data, which I think can be achieved by employing deep learning strategies.
To make the control software reusable for other prosthetics it should be modular, adaptable and extendable. Given the training-based nature of neural networks in the high-level control, the system could be retrained with a different prosthetic hand, the number of fingers could be reduced or expanded, and the concept of using deep learning even be applied to different types of prosthetics.
System Overview
The figure below shows a simplified diagram of the hand’s software control system. The wrist-mounted camera continuously captures frames until interrupted by an external control signal, initiating the closing process of the hand. The frame captured by the camera at this moment is pushed through five convolutional neural networks (one for each finger). Each CNN has a two-class classification output. If the network returns 0, the respective finger is not used for the grasp, if it returns 1, it is used.
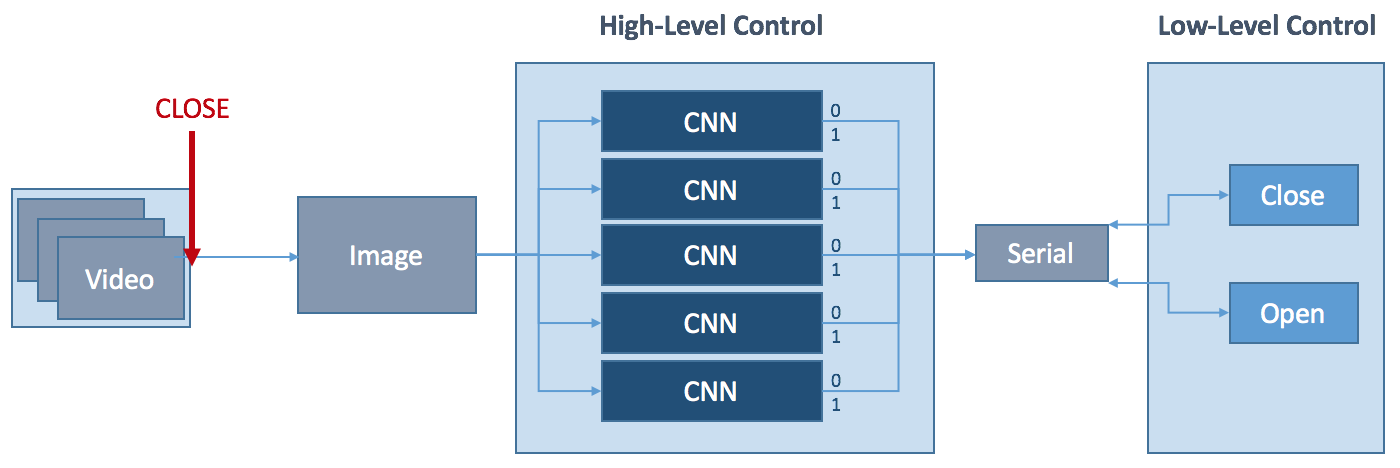
The resulting Boolean vector is passed on to the low-level control together with the closing command via serial connection. The hand then performs a grasp using the activated fingers. The opening of the hand can be initialised at any stage using an external opening control signal.
Something to change in the future is to replace the five individual CNNs with one CNN that can establish relationships between the different fingers, learning about which combination of fingers are favourable. It will be interesting to see how this changes the hand's performance.
Implementation Details
The high-level control software is written in Python and combines the CNNs, the camera feed, and the Arduino Mega 2560 into one application that can be run in the command line. A simplified overview of the complete high-level control system can be found here:
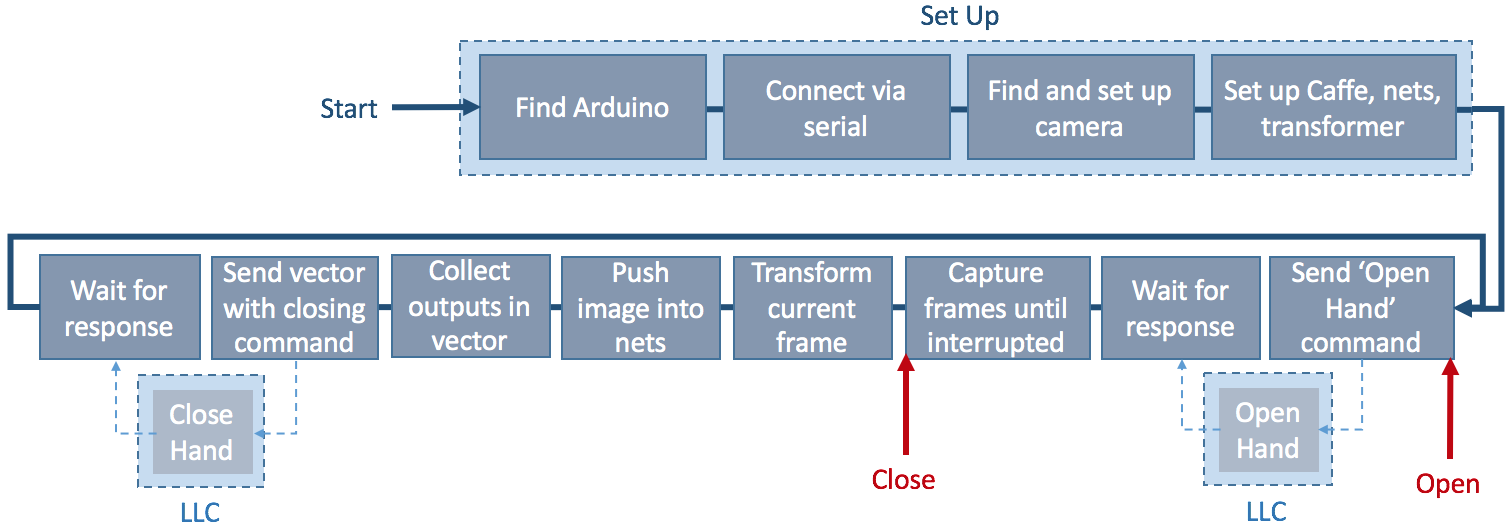
After setting up the Arduino, camera, and Caffe (a deep learning framework, more on that later), an ‘open hand’ command is sent to the low-level control of the hand. The low-level control sends a response back to the high-level control once the hand is opened. At this point the camera starts to stream frames to the computer screen. This allows for an object to be moved into the desired position before calling the ‘close hand’ command. This triggers for the current frame to be pushed into the five finger nets to determine whether a finger will be used for the following grasp attempt or not. The result of each network is collected in a vector and sent to the low-level control with the closing command. The closing command is executed with the appropriate fingers and a response is sent to the high-level control once the hand has closed.
In the next log I will attempt an explanation of what a CNN is, as well as introducing Caffe, the deep learning framework I used.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.