0%
0%
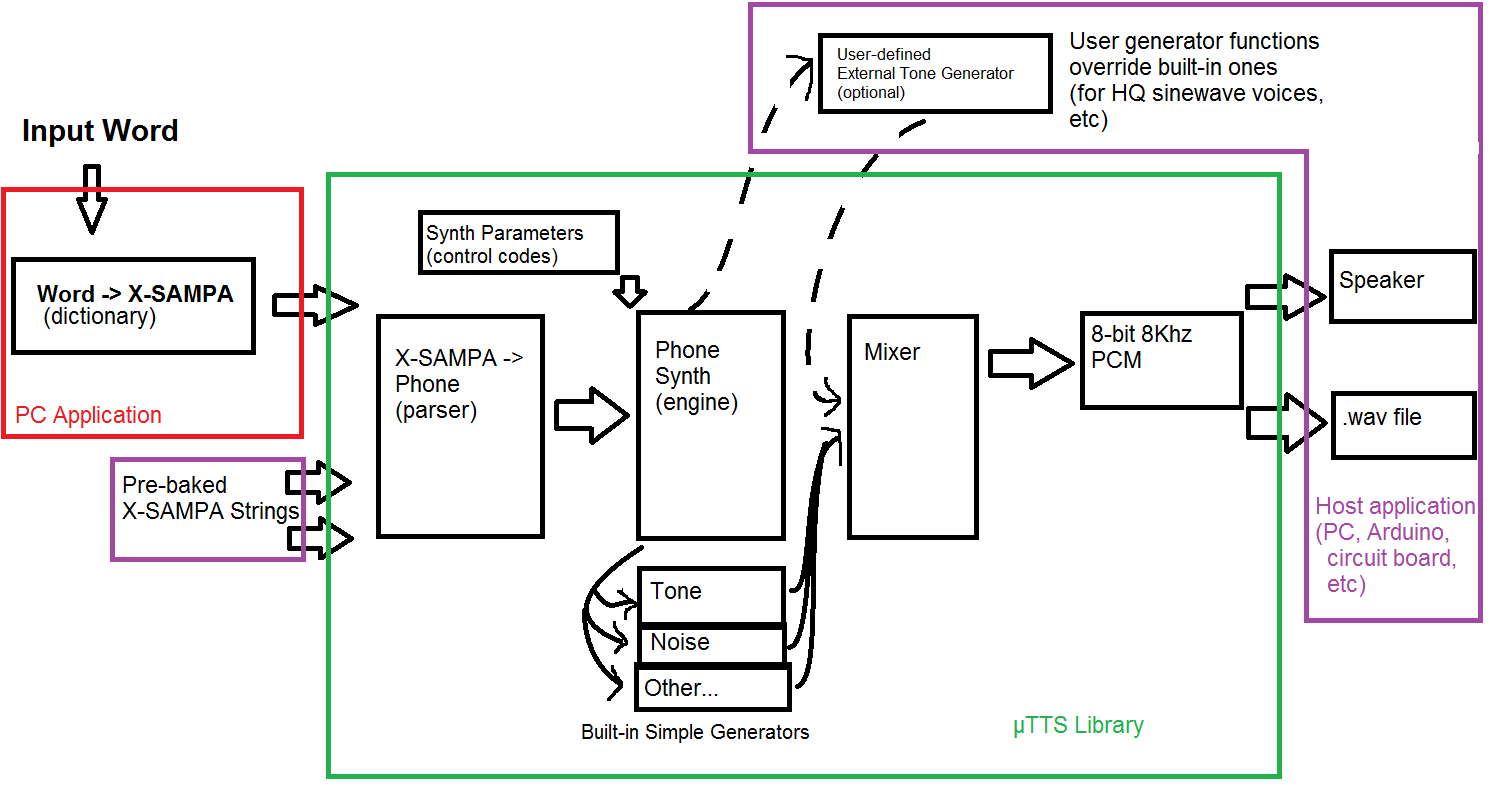
μTTS
Speech synthesis on a microcontroller. Talking projects, cheap as chips!
 Greg Kennedy
Greg KennedyBecome a Hackaday.io member
Already have an account? Log in.
Just one more thing
To make the experience fit your profile, pick a username and tell us what interests you.
Pick an awesome username
hackaday.io/
Your profile's URL: hackaday.io/username. Max 25 alphanumeric characters.
Pick a few interests
Projects that share your interests
People that share your interests
 Well, that's enough for now. Time to get coding!
Well, that's enough for now. Time to get coding!

 Christine
Christine

 rossumur
rossumur