schuhumi
schuhumiTo give you an impression of how fast this thing is:
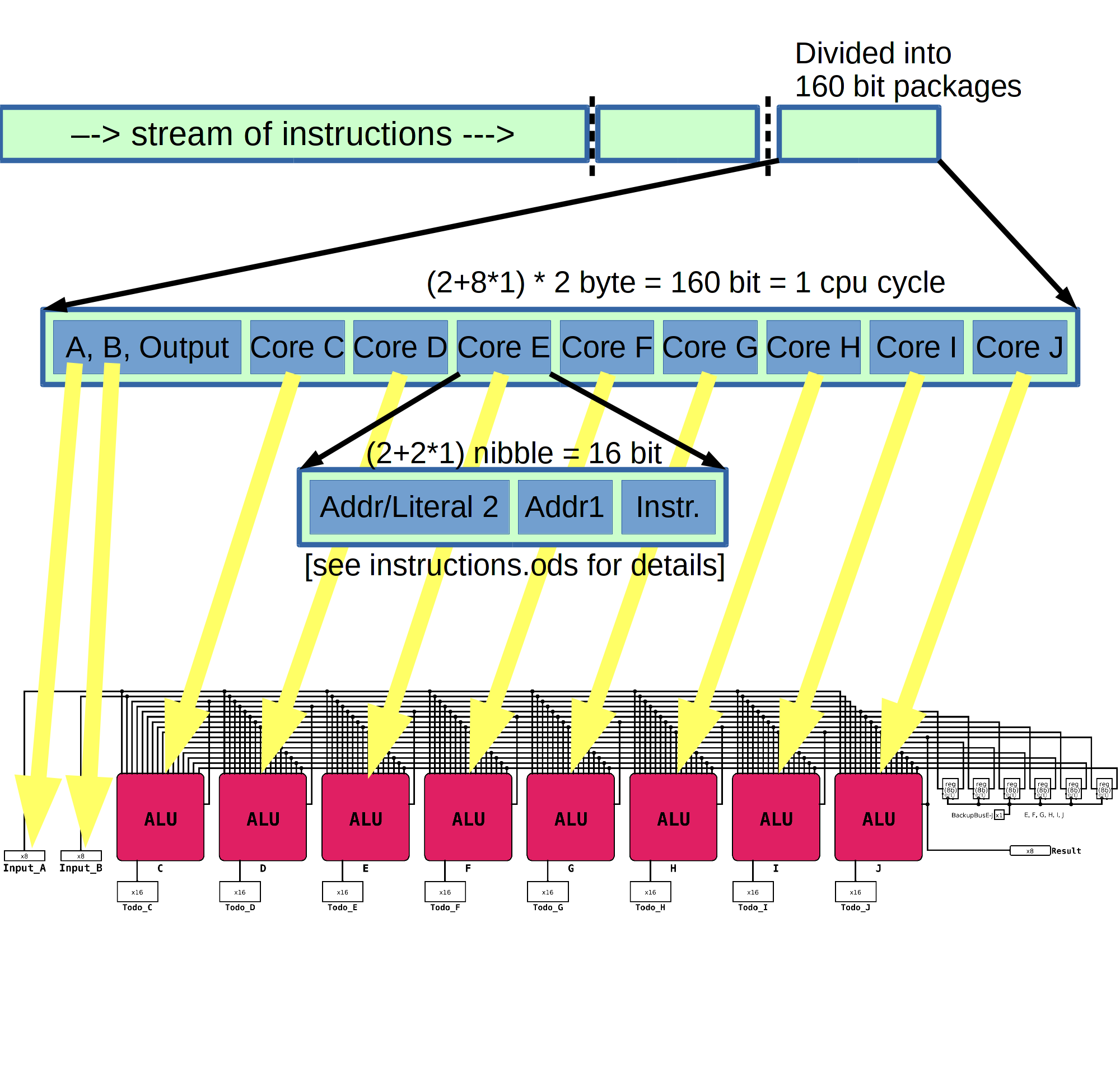
A = a0x01 # load content from address 1 into register A B = l1 # load register B with 1 (literal) C = A-B # simple math D = A>l2 # is A greater than 2? E = D?C:B # yes: E=C, else: E=B F = A*E G = C-B H = C>l2 I = H?G:B a0x80=F*I # simple math and copy result to address 0x80All this gets executed in one single cpu cycle! (which consists of 6 periods of square wave, just as the single core equivalent)
Some more detail (the code above is an example for one 160 bit package):

 Ed S
Ed S

 ErwinM
ErwinM