 SHAOS
SHAOSFirst PDP-11 compatible chip in USSR named 1801VM1 was slow, so Soviet engineers decided to add instruction pipelining into next 1801VM2 to make it faster (microcode became so sophisticated that they left a few unnoticed holes in VM2 microcode which were patched only in later CMOS version 1806VM2). This is how I found out how VM2 pipelining works:

I wanted to know how many cycles this subroutine from Elektronika MK-85 will take (it's display clean procedure):
; clear screen
decimalnumbers
org 0
.word L0A34
.word 0
org 0A34h
; 0A34:
L0A34: mov #80h,r0
; 0A38:
L0A38: inc r0
; 0A3A:
L0A3A: clrb 07F80h(r0)
; 0A3E:
clrb (r0)+
; 0A40:
bit #7,r0
; 0A44:
bne L0A3A
; 0A46:
cmp r0,#0E0h
; 0A4A:
bcs L0A38
; 0A4C:
make_mk85_rom "clr.bin",32768
Program is compilable by PDP11ASM utility, but in my experiment I set every word manually by switches every time when new address is shown on address LEDs:
0003 0000 decimalnumbers
0005 0000 org 0
0007 0000 005064 .word L0A34
0008 0002 000000 .word 0
0010 0004 org 0A34h
0012 0A34 012700 000200 L0A34: mov #80h,r0
0014 0A38 005200 L0A38: inc r0
0016 0A3A 105060 077600 L0A3A: clrb 07F80h(r0)
0018 0A3E 105020 clrb (r0)+
0020 0A40 032700 000007 bit #7,r0
0022 0A44 001372 bne L0A3A
0024 0A46 020027 000340 cmp r0,#0E0h
0026 0A4A 103766 bcs L0A38
Below addresses are hexadecimal, but opcodes and arguments - octal (as usual for PDP-11):
0A34h 012700 mov #80h,r0 <<< 1st half (actual instruction opcode) took 8 cycles
0A36h 000200 <<< then 2nd half (argument 0x0080) took another 12, so it's 20 cycles total
0A38h 005200 inc r0 <<< increment of R0 took 8 cycles (now R0=0x0081)
this is beginning of the loop:
0A3Ah 105060 clrb 07F80h(r0) <<< then clear BYTE memory location with offset R0 - 1st half took 8 cycles
0A3Ch 077600 <<< 2nd half (argument 0x7F80) took another 28 cycles (because it then goes to address 0x8001 to read word and then write modified word back), so it's 36 cycles total
at this point everything is logical and as expected, but then I observed a chaos:
0A3Eh 105020 clrb (r0)+ <<< it should clean BYTE by address R0 with post-increment, so we should expect read-modify-write from/to 0x0081 (current R0 value) - reading of opcode took 8 cycles
BUT THEN IT DOESN'T GO TO READ-WRITE FROM MEMORY - it goes to fetch next opcode!
0A40h 032700 bit #7,r0 <<< read next opcode in 8 cycles
then we go to read argument 0x0007, right? WRONG! then it goes to finish previous command and perform READ-WRITE on address 0x0081! another 18 cycles
0A42h 000007 <<< and now we read argument 0x0007 - another 12 cycles
0A44h 001372 bne L0A3A <<< conditional branching opcode - 8 cycles to read
0A46h 020027 cmp r0,#0E0h <<< and then it reads NEXT OPCODE (just in case?) in 8 cycles, but this instruction will NOT be executed, because conditional branching was successful, so CPU doesn't bother to read argument 0x00E0 of that "just in case" instruction:
0A48h 000340 <<< ignored
and jump - address indication shows 0x0A3A now...
So one run through loop is taking 36+26+20+8+8=98 cycles of CLCI - it's clearing 2 bytes in different parts of memory with post-increment of R0 and test that 3 less significant bits of R0 are not 0 to decide if it needs to continue (loop is intended to run through 96 bytes with skipping every 8th one).
Per information from one knowledgeable person:
- 1801VM2 without dots on the package is capable of doing 12.5 MHz of CLCI
- 1801VM2 with 1 dot was tested on the factory with 10 MHz of CLCI
- 1801VM2 with 2 dots is worst from the series that was passed only 8 MHz test (but they recommend not go higher than 6 MHz for this kind)
Now you can estimate performance of your chip: 10-MHz one can do 1.25 million simple 8-cycle instructions per second and 12.5-MHz one - 1.5 million!
P.S. Actually my experiments with timings some sort of confirmed official VM2 documentation (in my case I didn't have delay between DIN/DOUT and RPLY at all, so it was 1st column):
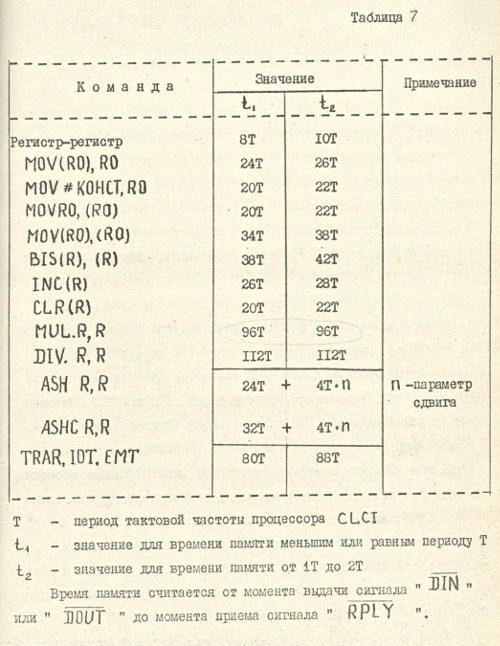
P.P.S. Actually it is strange that VM2 does READ-MODIFY-WRITE cycle for clrb - it is NOT required, because PDP-11 is able to write half of the word (with WTBT=0 and A0=0 means lower byte and A0=1 means higher byte) and when we clear something we don't need to know what it was there before put 0 there...
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.