 BaumInventions
BaumInventionsEverything i mention here is in HEX.
The ROM has a storage volume of 80000 Bytes.
When i looked at the Raw data i could clearly see the different "sectors" of data.
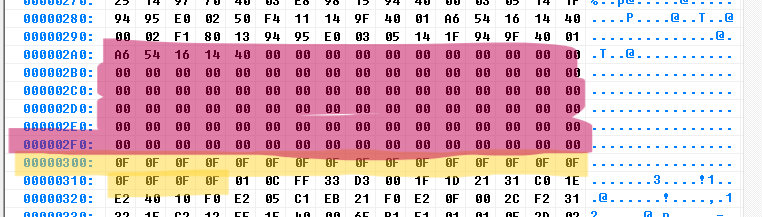
This is the first larger gap. The data from the first Block (starting at 00) ends at 02A4. The bytes till 02FF are padded with zeros. At 0300 some 0F start. These 0F are the squiggly lines we have seen in the audio analysis. My guess is the Audio starts at 0314. Now we know that all the rows of 0F are a clear indicator of where one sample ends and another one starts. and that 00 are used for padding.

Here is the gap we saw in the audio at the center of the data. The first block of data is padded with 00 till (presumingly) 03FFFF (thats the gap we saw). The new block of data starts at 040000. Thats exactly at half of the chip.

And like the first block we have another "00 padding | row of 0F" situation at exactly 040300. Again i think the audio starts at 040314. That totally makes sense because the audio is visible and audible after the squiggly line.

If i just search for "0F 0F 0F ..." i get 100 results. Now we know that there are around 100 audio samples.
The number of 0F in a row is not always the same. its around 10 to 1F long.
Now we know the voce data sarts at 0300 (040300). Because decoding the voice is a different beast lets start with the stuff that is not voice (everything before 0300).

This is the data from 00 to 0300.
While i was looking at that i noticed a smaller block wich starts at 00 and ends at 4F. When we ignore bytes 0 and 1 you can see some kind of "counter". Byte 2 and 3 are 0050, byte 4 and 5 are 006C... The highest numer is 0291 wich is located at byte 48 and 49. This block also seems padded with 00 towards the end.
In the data from 40 to 02FF i noticed a lot of 14 and 4000. And again padding with 00 towards the end of this block.
To visualise this a little bit more for myself i exported the data as HEX (not BIN) and loaded it into an text editor.
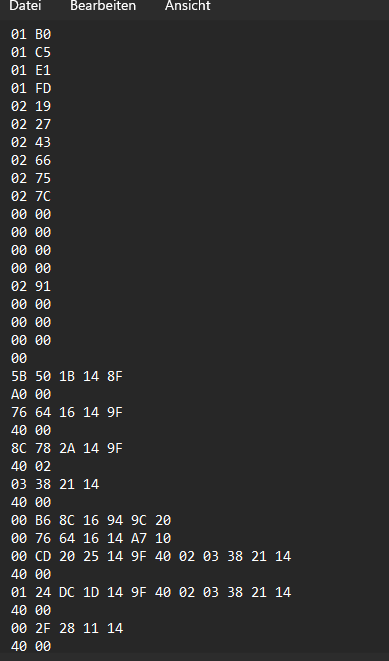
You start with a huge block of those numbers. And after every repetition or interesting number i saw i just pressed enter to get everything into what you see here. There is the "counter" we saw on top of the file and the "4000" . Some of the data between the 4000 was similar to the data before. And there are a lot of 14. Nearly every of those lines has at least one 14 and 4000 in it.
Because the first 4000 appeared after the first data it could indicate the end of a data block or the start of a new data block.
Now i needed more flexibility to handle the data and i loaded the block into open office calc.
And after "just" one day constantly looking at those numbers i noticed some things.
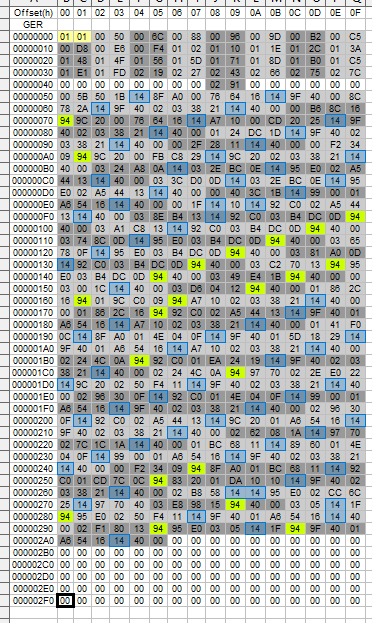
Remember the "counter"? When we take the first 0050 of the counter and have a look at the further code we will see the first block of data starts at exactly 0050 and ends at 006B with a 4000. Ohhh... Lets have a look at the counter again... The next number is 006C... Thats a thing! That is exactly after our 4000 from the first block of data... Lets call the "counter" a lookup table from now on.
You probably already have noticed that i have coloured all the 32 values of the lookup table and the corrosponding data. Also there are really a lot of 14 and 94.
Lets bring this into a new form.
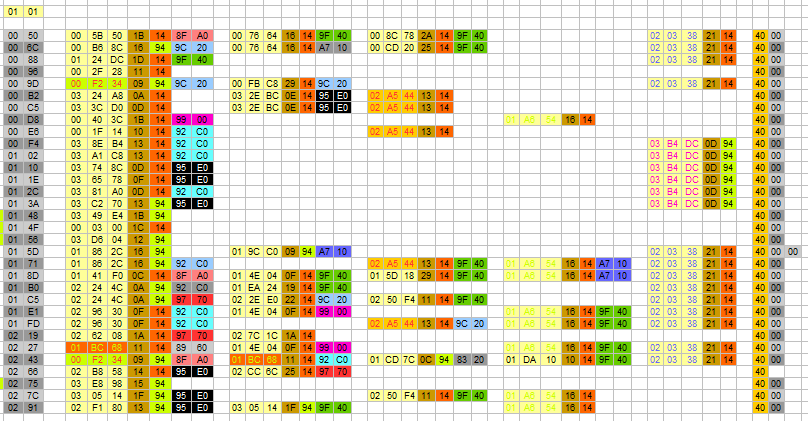
Thats looking better.
On the left side in grey i have the values of the lookup table. Each value from the lookup table is followed by the data that it sends us to.
This took me hours to find out. I will break it down for you.
Each set of 3 connected light yellow boxes is a 3 byte value pointing to the beginning of a squiggly line. The brown box after the light yellow box is the length. The length is around 0,05 0,06 s for an increase of 1 hex. The 4000 is the end of a data block.
From this table we can reconstruct the sentences that are formed from the samples.
Example:
Lookup table 00B2:
0324A8 : Left
03E2BC: brakelight
02A544: faulty
(i know wich hex value is wich sample because i have listened to the samples (in the expremely poor quality of the first tries) took notes wich sample came after the other and matched it up to the hex values)
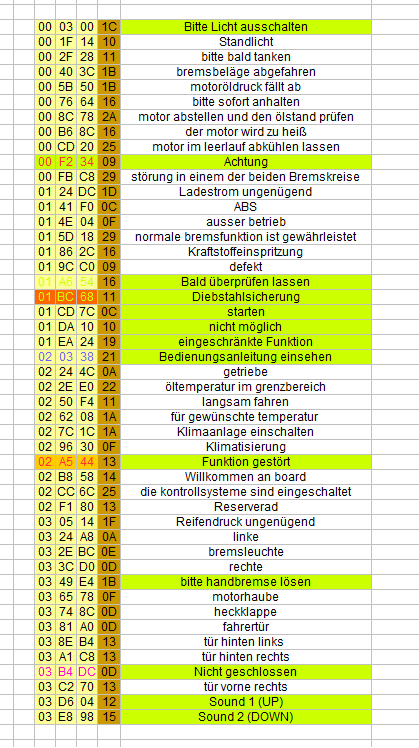
This is the stuff i know. Now the stuff i have to investigate further.
I still dont know what the 14/94 bytes are for. I can hear no change if i put different values ( 00 FF 55 etc.) here.
The second byte after the sample position is related to the pause between two samples. FF is a pause for around 4 seconds. I have to find the lower limit... at some point it just doesnt play the sample after it...
The third byte doesnt seem to affect anything like the 14/94 byte...
I have to edit the data and figure out what the bytes i dont know are doing . But writing roms is pretty slow and clearing them with uv light also takes its time for each try...
I think i should invest in a FLASH solution or an eprom emulator...
As a first try i have copied the data from 40000 - 402FF to 00000 - 002FF. That should result in the system using the italian lookup table and control data instead of the german ones... And indeed it does. Works perfectly fine... My german box is now speaking fluid italian...
Now i really want to understand how the samples are decoded and the unknown 3 bytes of control data work.
That would make it possible to create custom roms with own words / length and flow.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.