 kasik
kasikI mentioned data augmentation already in a few logs, so I thought I will write about it briefly. Data augmentation is used to enhance the training set by creating additional training data based on existing data (in our case: images). It can be modifying the existing ones or even using generative AI to create new ones! I will mention the first technique as I didn't have yet the chance to dive into generative AI.
A few examples:
- adding noise
- geometric transformation - cropping, rotating, zooming
NOTE: The biases in the original dataset persist in the augmented data.
There are at least 2 ways readily available for data augmentation. One would be to use keras.Sequential() - yes, the same one used to build the model. It turns out that there are also augmentation layers that can be added. Moreover, the preprocessing layers can be part of the model (note: the data augmentation is inactive during the testing phase. Those layers will only work for Model.fit, not for Model.evaluate or Model.predict) or the preprocessing layers can be applied to the dataset. Another available method is to use tf.image - which gives you more control. Official simple and clear example for both.
Or, perhaps, just for fun you can create your own preprocessing. In my repository you can find data_augmentation.py - where I implemented some transformations of the images. It is a very simple script, which creates 8 extra images out of 1 - it flips, rotates and adds noise.
All of the nine images are saved in a new directory, in that case called 'output'.
A comparison of the training results with and without using augmentation:
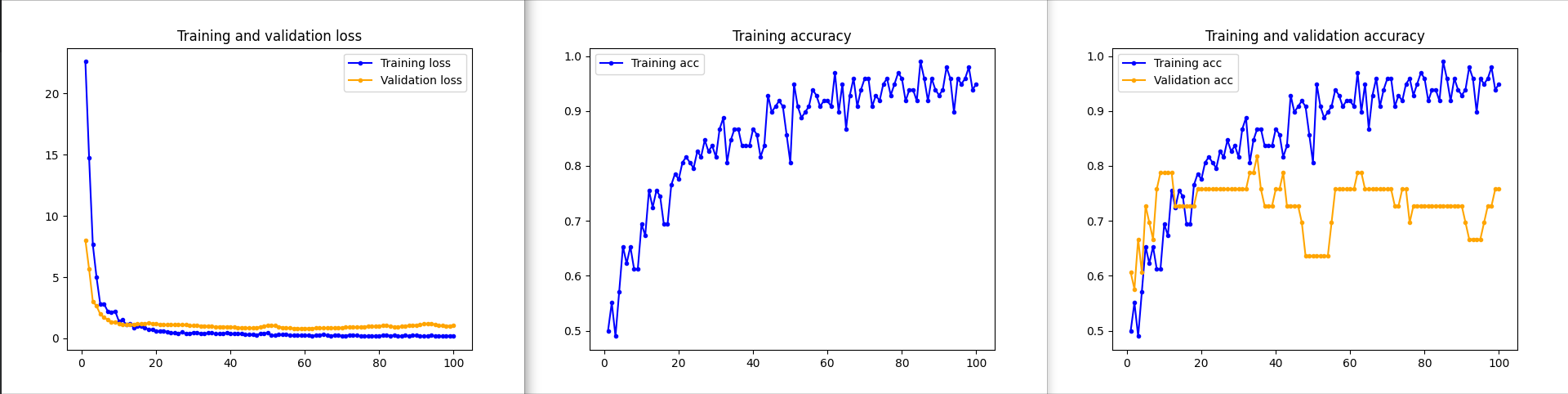
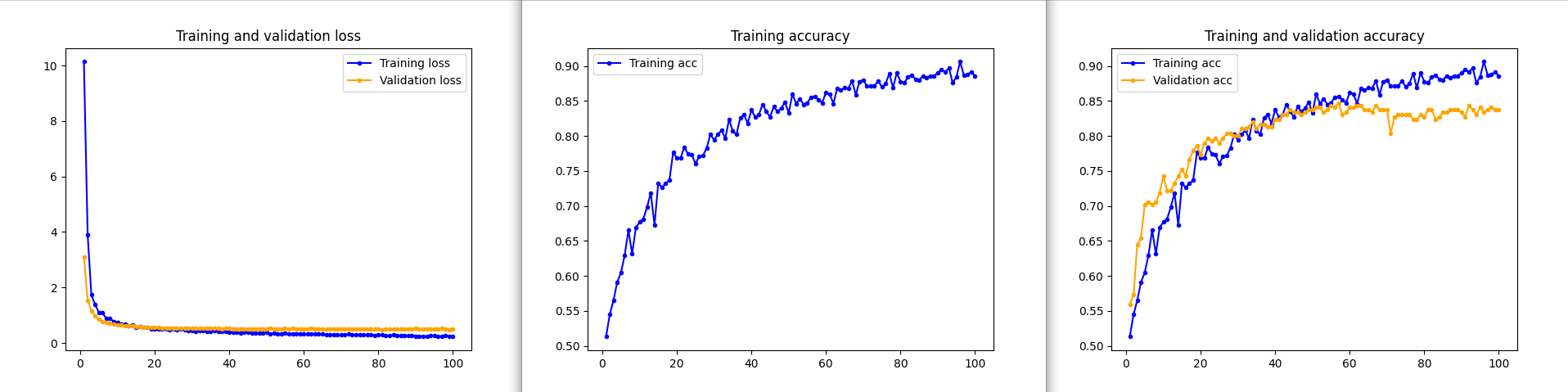
I had a chat recently about a medical device (SaMD - Software as a Medical Device) that was trained on the dataset of 7 images. Much to my surprise I understood that it was working quite well! Don't worry, it was only guiding the medical personnel ;) I would love to have a chat with the developers to understand whether they used transfer learning/ data augmentation or perhaps even a different algorithm?
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.