 Jacob
JacobThe latest step on our quest for menstrual innovation has taken us into the exciting world of machine learning. Yes, it may be a big buzzword nowadays, but there’s a reason it’s getting so much attention: ML is an incredibly powerful tool for the right applications.
Dusting off my programming skills, I dove into some tutorials I found online, worked through the many resulting bugs (praise be to stackoverflow), and ended up with a pretty nice, if basic, machine learning script which combed through our data, extracted salient features, and ran them through an ML algorithm.
Now, here’s where it’s going to get a little vague; my apologies in advance. Because we’re still early stage, I can’t talk too much about the specifics of the data we’re gathering, but I can talk about the code itself, and the success we’ve had. So let’s get to that!
I started out using a neural net classifier, implemented through pybrain, as that was the extent of my knowledge of machine learning when I began this a few weeks ago. I achieved moderate success for my rookie status: usually scoring in the range of 75-80% accuracy. It did well enough to show that there was potential, but I wanted to see if it could do even better. So I switched gears to an SVM classifier, which fared even better, achieving an accuracy of 87.5%!

Heartened by this success, and on the advice of a friend who knows a lot more about machine learning than I do, I decided this was adequate proof of concept, and moved onto the real challenge: predicting percent saturation. So far I’ve had mixed results. The big issue is that our data, which play nicely with classification, are causing us more trouble with gradient detection. For an illustration of this, look at the plot below: a simple regression on a test set of our data (here, using only one feature to predict percentage).
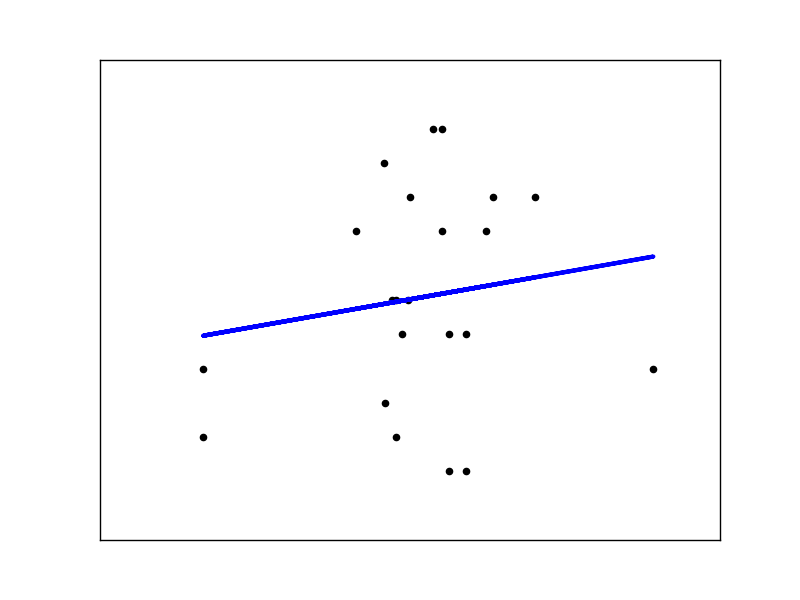
I’m confident that this is not an intractable problem, but it’s clear that this data isn’t going to play well with our algorithms. To fix this, I’ll have to step up my feature extraction game. Until now, I’ve been using some of the most obvious, surface-level features of the data for my analysis, and have not utilized any of sklearn’s various feature extraction functions. Once I get started on that, I’m very excited to see what sort of accuracy we can get.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.