 ThunderSqueak
ThunderSqueakwas thinking last night before I went to bed about voice recognition. I started keeping a notebook next to the bed years ago and woke up to find this scribbled down.
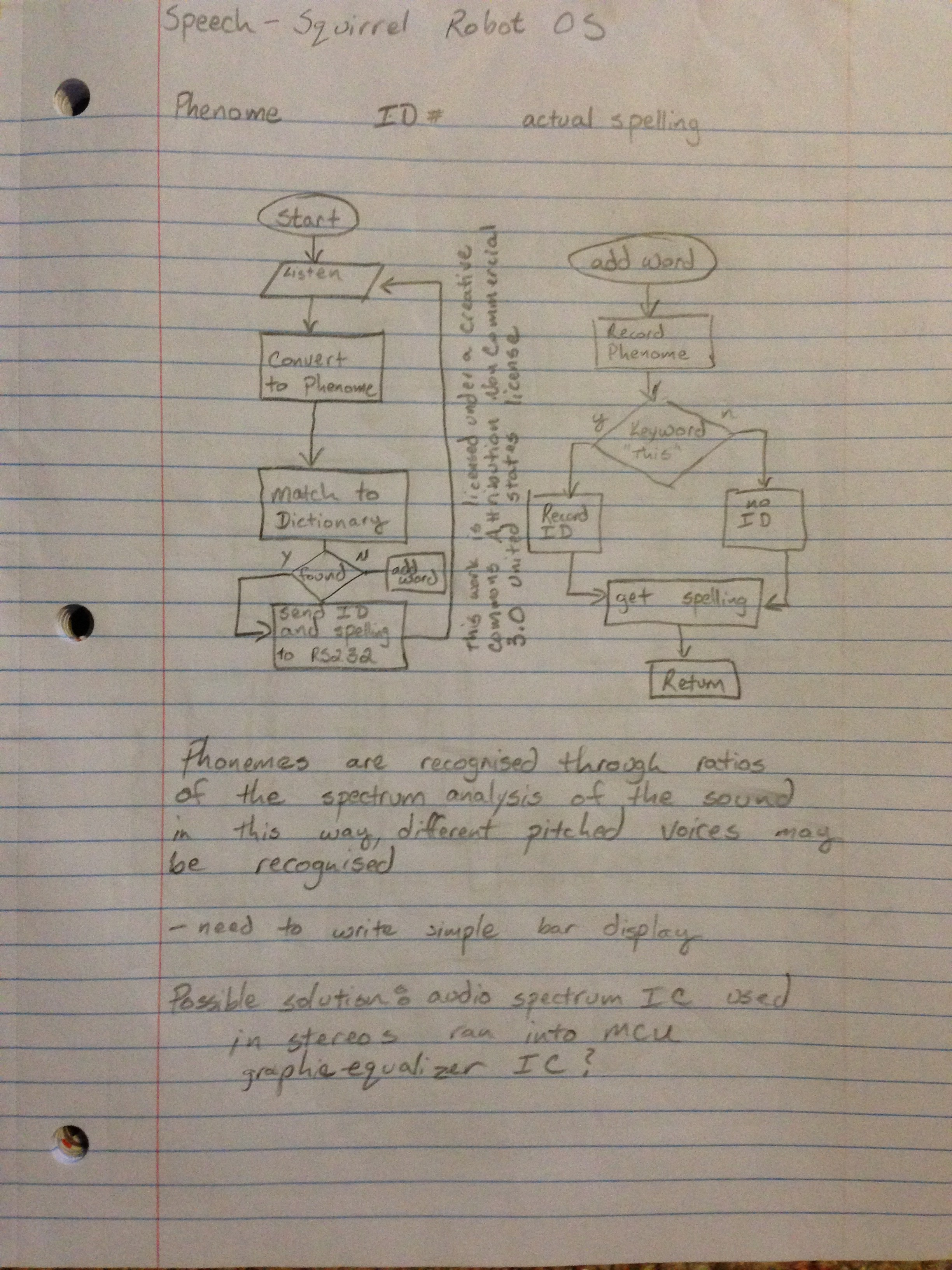
The part in this idea that interested me the most upon waking up is the thought of using a graphic equalizer IC to capture phonemes and other sounds. Every sound has its own spectrum signature, including human speech. The next step is to pick up a small graphic equalizer IC such as the MSGEQ7, which is a 7 band equalizer, and give it a try.
The thought is to capture the pattern roughly every 200ms and compare key point ratios to a table of known sounds. By using a ratio algorithm, the thought is that even if there is a change in pitch it should be able to identify certain audio signatures. After identifying these signatures, the micro-controller then shoots off a serial packet to the main board for use.
Initial testing by simply speaking into my spectrum analyzer with different phonemes shows that this idea, at least in general, works. :)
Now to see if those 7 bands are enough to identify different signatures.
I know I could simply run an open source speech to text program on the pi, and it may eventually come to that. I do however, wish to get as much of the lifting off the central control system as possible.
A link to the datasheet of the IC mentioned above. Other chips may work, this was just the first one I found with a quick search.
https://www.sparkfun.com/datasheets/Components/General/MSGEQ7.pdf
For the Microcontroller, I am considering the use of a pic 16F1459.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.
I will! Thanks! :)
Are you sure? yes | no
Have a look at http://arjo129.github.io/uSpeech/
Are you sure? yes | no