 SHAOS
SHAOSYes, ternary FPGA could be used as binary FPGA :)
In case of TERNARO for this purpose every 3-input ternary multiplexer should be converted to 2-input binary multiplexer by setting XYY or XXY configuration bit - it turns every MUX to E12 or E21 respectively:
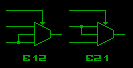
From binary point of view E12 is a multiplexer with lower threshold (about 2.1V for 5V power supply) and E21 is a multiplexer with higher threshold (about 3.5V for 5V power supply). So now we can build circuits with hysteresis (see this log for more info about actual thresholds):
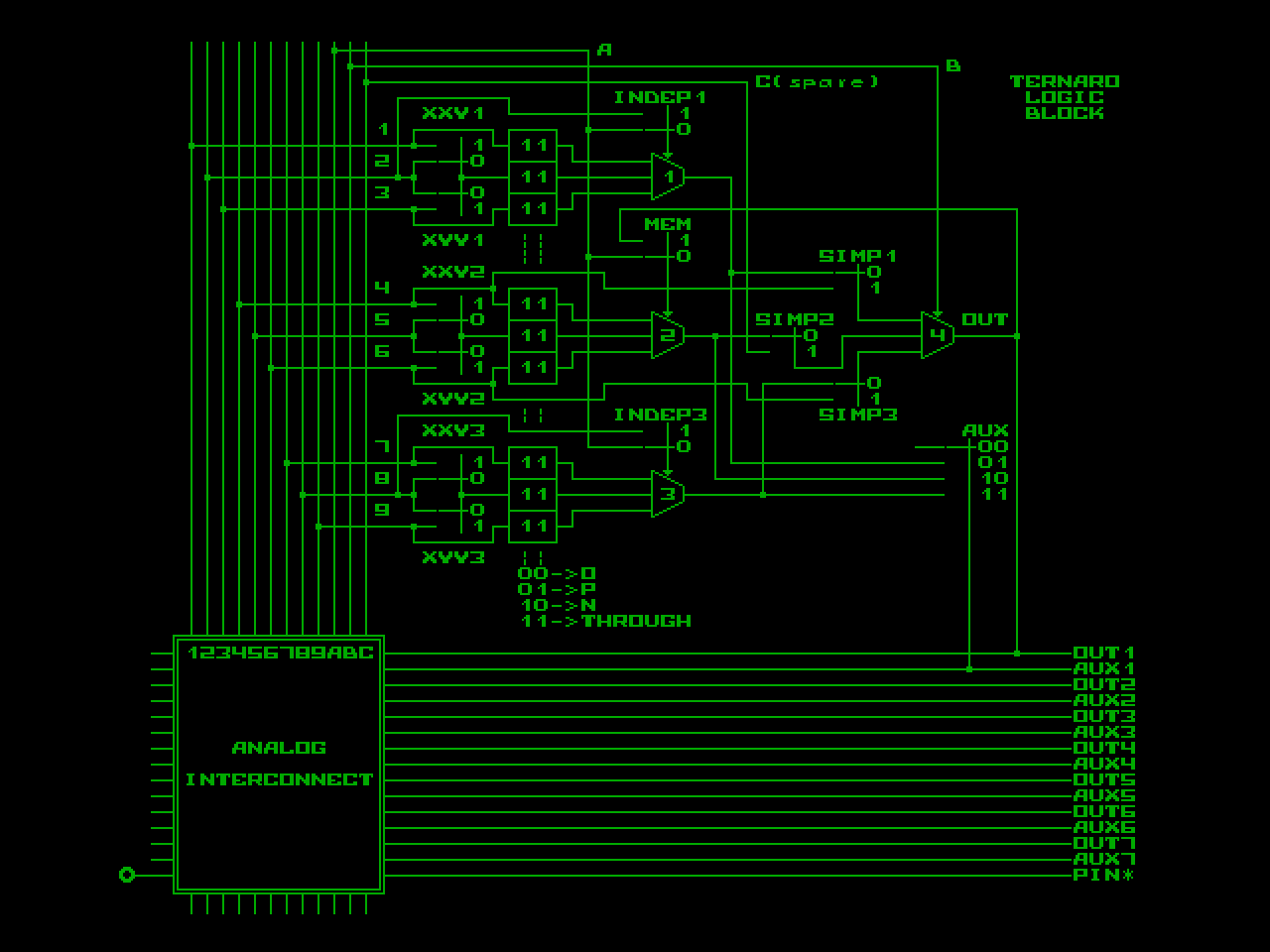
Also in case of "binary mode" multiplexer 2 will be used only to form MEM cell (and will be ignored if logic block is used as LUT), so vertical signals 4,5,6 will be always free to be used for interconnect.
Another interesting trick - in "ternary mode" every constant O (set by 00 pair) is actually direct connect to input Vref, so in "binary mode" we may re-name input Vref to I0, because effectively it becomes additional general purpose input for the circuit (input number zero). And constants N and P in "binary mode" becomes "0" and "1" respectively (as they stay to be direct connects to ground and positive power supply):
00 -> Vref input of the chip (I0)
01 -> Constant "1"
10 -> Constant "0"
11 -> Through connection to vertical line
Later we can add support of "binarized TERNARO" into Yosys for example and then people will be able to program TERNARO using standard Verilog :)
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.