 Pavel
PavelName of homebrew computer
I am not good at coming up with names, but after some thinking I've came up with the name for this computer at last:
from now on it will be called ECM-16/TTL. This is itself a quite generic name, meaning Electronic Computing Machine, 16bit, based on TTL logic chips (of 74HC family). A quick search on Google haven't returned such name for any other homebrew computer/cpu, so I claiming this name for my machine in development.
Assembler development
On the assembler front, it is now a version 3, and becoming a treat to use, as now it supports labels and directives (though, no expressions yet). The constant reference for bit patterns of instructions and hand-calculation of jump and load/store addresses are no longer needed, all is done automatically.
During development of this assembler, several bugs were found in it, and also in the wiring of computer itself. Now, they are fixed.
There are some things that are yet to be added to the assembler -- I think, adding support for at least rudimentary expressions (like adding constant to label) will be handy. I also thinking about adding of PC-relative addressing for short jumps and load/stores, this way awkward situations on the page and block boundaries could be avoided. But this means adding another adder to machine, this time to addressing circuitry, the thing I've tried to avoid from the very beginning. Also, the assembler logic will have to be changed a bit.
Descriptions on some of the aspects of ECM-16/TTL:
Reason for 24-bit addresses
At first, I was content with having 64k words for this computer design.
But after a while, when designing memory access instructions, I faced the situation: the address must be somewhere. The 16 bits for addressing of 64k are comfortably fit in general purpose registers, and such size is comfortable for shuttling around on the main bus. But I wanted instructions which would have the address encoded into them. I already had instructions for ALU with a constant value encoded into them, like ADD aX 0xff, and this scheme can also be employed for addressing. Thus, there is an instruction like LD aX [0xff], and it is laid out in instruction word as [high byte][low byte] => [opcode][address]. But this only can address 256 words (what I call a single "page") of memory, which is far from desired 64k words. To have an instruction which have in itself the whole address, it itself will be longer than the word. Naturally, it would take up the two words, as this design does not support byte addressing. So, I had 32 bits to play with. One way could be done as [opcode][high8bit of address]:[low8bit of address][not used]; but it would be too awkward to implement in hardware. Another way could be [opcode][not used]:[high8bit of address][low8bit of address], which is much more natural in this design. Now, though, I have 8 bits more than I have to to address 64k locations, so why not use it? Let's define block of memory as 64k locations which can be addressed by one 16 bit word. Then if we use the byte right next to opcode, then it will be the block index, with up to 256 blocks possible to address, and therefore 16M memory locations that could be addressed by 24 bit address. In reality, I don't think the computer will ever have as much memory, mostly because it would be relatively expensive (SRAM chips are to be used for memory).
Memory space can be presented as hierarchical structure, with levels differing by ease of access (number of clock cycles needed):
Page -- 256 words, which can be accessed with shortest and fastest instructions;
--I am thinking about re-making in-page addressing into PC-relative one, so there close load/store or jump could be made to +-127 memory locations, independent on page/block boundary. This change will need addition of another adder, 24bits wide, so [base + offset] address of location is calculated on the fly. This may also add quite a lot of complexity to assembler.
Block -- 65536 words, addressed by value in one of the general purpose registers;
Global -- whole address space of 16777216 words, which can be addressed by two-word instruction, or compound value from two registers.
----------------------------------
Subroutine calls
Somehow I thought subroutine call is just pushing PC to stack; but this turned out not all there is to it. As I was thinking trying to devise a way to make the subroutine call as 2 instructions (push pc+1 to stack and jump), it seemed that this cannot be done: either return address was the address of jump instruction, so endless loop ensues, or the pushing of PC is done after return instruction... as the return address is still undefined, this obviously cannot work. After some reading, it occurred to me, that jump and pushing of PC should be done in one instruction. Luckily, I needn't come up with new distinct machine word for this instruction, as I already had a useless one lying around, from jump family: the unconditional skip, or NOP, the opposite of unconditional jump (This was a kind of conditional jump for which no condition can be true). All I had to do is use it and add PC pushing to Jump decode circuitry. As it was, I overhauled all memory access block, re-done it from scratch, so it became more regular in its wiring and easy to decipher. This overhaul haven't changed anything about its function, except adding the Jump to Subroutine instruction. All other operations are still executed the same way as before.
The JSR operation uses the same stack pointer as the regular stack operations, so return address is stored alongside data, and if one is not careful (like popping more or less data than was pushed), the return address may become undefined.
These subroutine calls can be done from anywhere in a program, and recursive algorithms can be implemented.
As of now, there is no provision to store stack pointer address to memory. Though this can be useful to have if one needs separate stacks for data and function calls.
----------------------------------
Assembly description:
General
The program takes in a plain text file with .asm extension, parses it finding opcodes, performs assembly and spits out another text file, with .hex extension, which is just a column of 4-digit hexadecimal values. These are directly mapped to machine code of simulated computer.
The assembled code is then uploaded to ROM via simulator tools:
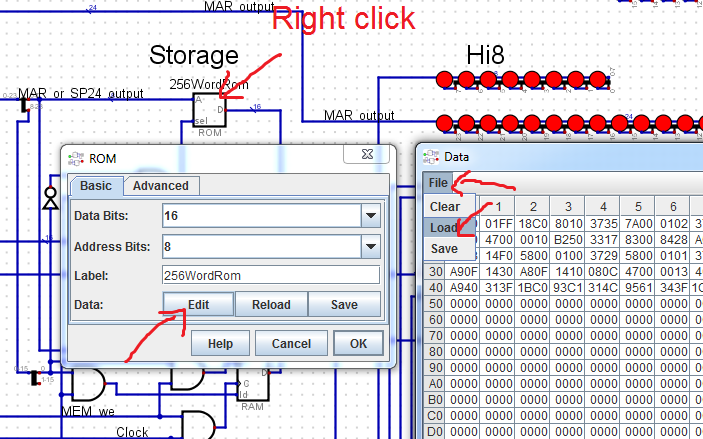
Each instruction should be on its own line of assembler program.
The (optional) label, instruction/directive and their operands should all be separated by at least one whitespace character.
Instructions
Single opcode can have different sets of operands; depending on particular set used, different operation is performed. The operations are closely related, hence the common opcode. For example, some ALU instructions can have either one register and a small constant, two registers or three registers as operands, which results in somewhat different outcomes. Use of such "overloading" cuts on total number of opcodes in set, which should make it easier to memorize.
Instructions with subscript ( "i" or "g" ) are using up 2 words in memory, all others are using only one.
i - immediate, a one-of the kind load instruction
g - global direct, used for fast and easy access to faraway memory location
In the following list, instructions are divided into categories by function, and inside categories by type, each type having similar operand lists
Following instructions are supported (46 total):
ALU instructions:
a) ADD SUB
ADDC SUBC
AND ANDN
OR ORN
XOR XNOR
b) CMP
c) SHL SHR
ASHL ASHR
ROLC RORC
d) ROT
e) INV
f) ZERO
Memory Access:
a) LDi STi
b) LD ST
c) LDg STg
Jumps:
a) b)
JMP JSR* JMPg JSRg*
JC JNC JCg JNCg
JN JNN JNg JNNg
JZ JNZ JZg JNZg
*Jump simultaneous with pushing PC to stack
Movs:
MOV
Stack operations:
a) PUSH POP
b) PUSHPC RET
Following Directives are supported:
.EQU
.ORG
.END
.BYTE .WORD .DWORD .QWORD .OWORD .HWORD
The mnemonics are heavily influenced by ones presented in book "The Definitive Guide to How Computers Do Math" by the authors of DIY Calculator.
The assembler program, version 3, can be found in "asm3.zip" file in "Files" section. The archive contains .cpp source file, pre-compiled Windows binary and a comprehensive description of assembler and all instructions/directives it supports; also included a small program in described assembly which performs multiplication of two 16-bit values, and displays result on 7-segment display.
There are a couple of unresolved issues with assembler program:
- If there are several whitespaces followed by comment on a line, assembler crashes - avoid such lines
- If the last variable is an array, assembler crashes; workaround -- add a dummy single variable.
The updated version of computer simulation is in archive "computer042.zip".
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.