i'm using Arduino IDE 1.8.9. my main focus is speed on the uno and nano but this also improves performance on any cpu.
i have broken down problems, created fast math optimizations and cached ares for better performance. now it is time to look at the engine closer:
these two areas eat all the cpu cycles on nano. higher clock rate on any processor will improve performance
sub_calc_irData 145,000
the first sub_calc_To calculation 500,000
i have troubleshoot_optimize set to true, it outputs some more stuff so i can make things work faster.
i tried moving one of the progmem tables to ram. it only reduce cycle counts by 5000 microseconds
this is caching the 1 /2^x table in ram and the 2^x table in ram only save about 5000 microseconds over 768 reads. this is below the variation of +/- 10,000 per frame 760,000 micro seconds on arduino nano so it could just be noise. moving on to next area. the progmem tables are fast enough. they are faster than the switch(x) {..} i had used earlier.
below is a sample frame using ram cached values. the process time goes up and down depending on pixel information.
set Replace_detailed_calc_with_image_data false will allow testing of detaled To mode output of pixels.
just for comparing here is with the image mode of sensor read
set Replace_detailed_calc_with_image_data true will allow testing of image mode

this tells me two things
1) the detailed calcs in the To eat up around 300000 microseconds on uno. teense-lc runs faster
2) that there is some other part of the system functions eating up a lot of cycles.
3) that there is something outside of the math calc of the temperature that is using a lot of cpu time
in the MLX90640_CalculateToRawPerPixel(uint16_t pixelNumber ) my own version of the routine that returns 1 pixel at a time to help save ram on processor and utilize storage on sensor, there are several areas of note for cpu cycles
also i moves some of the math values at the start down further so i could easily make sense of caching them.
what i did to look at areas of function where things slow down was
return 5; so it exited the function and returned something in this case 5. later on after some math functions are done i return some of those results. then time how long it takes to complete the function to that point.
my code in this function is really dirt right now. i'm trying to simplify and make redundant processes improve. so everything is being broken down
this is on nano. faster cpu will have different results.
running thru all of To function ~760,000 cycles +/- 10000
i took the line that reads the ram info and had the number replaced with 1.5
sub_calc_irData = 1.5;//RamGetStoredInLocal(pixelNumber) ;
this lowered the time per frame about 20,000 cycles. seems the read currently is not the culprit
i then had it again take values from ram and turned off my i2c cache reads. it took 840,000 cycles to complete. turning off the store of i2c cache slowed it down 80,000 cycles. so the cache is helping. currently i cache 64 i2c reads. and use about 128 bytes of ram for it.
the memory reads with cache enabled per cell is 20,000 cycles. this is acceptable and is not the main bottleneck
i then took out the serial write time, by disabling serial output but still loading its buffer. it only takes 690,00 cycles to complete a savings of ~60,000 microseconds. caching of serial is for output to update to screen faster. so it will be redone anyways but it is not the main bottleneck
then i did it without sending serial data except for time counts output and turned off doubleres
without double res and without serial send of text it is 640000 microseconds.
this is useful info it states that double resolution currently takes about 50,000 microseconds to complete and this is ok as it needs to pull ram values and store its own cache of ram. i'll see if i can make it work better, but 50,000 for 4 memory reads seems really good when 1 memory read is 20,000. this also means that the i2c data cache is working and that the buffer cache in the doubleres is improving performance.
so on average a full 768 cells penalty for the following currently takes
50,000 to 60,000 nonfloat vs float cycles for the double res and it outputs 3072 pixels spaces
serial output to screen takes 50,000 (when output 3072 pixels ascii text graphics
ok, so now i removed the To loop for testing its cpu time. this is useless other than testing its time
MLX90640_CalculateToRawPerPixel(uint16_t pixelNumber ) {
return 5;//just number i used.
... all other data not process }
total process time is about 90,000 microseconds....
so all my work should now focus in this function and its processes
the first half of the To functions are already cached and only updated at the first pixel read.
it is something like this if (pixelNumber == 0){//we only do this on start of page
i disabled this cache part to see what times would be if each pixel processed all the raw values
it takes 1300000 microseconds. about twice as long. so this caching of data is working.
timing of data to page cache is 95,000 microseconds. so 5000 more

so this top part is already really efficient. this entire part only takes 5000 microseconds for processing all 3072 interpolated pixels. (this part only processes the raw pixels.) the entire process from capture to processing and outputting to display takes 95,000. this will be a concern later but it is not what is eating up cycles. you'll notice i have some caching going on. although since this loop is run once per 768 it might not have been needed.
I found the first major slow down in the process it is here and it takes 210000-65,000 cycles to complete.
at this point of the function it takes 210,000 to complete. before the code i have below it takes only 65,000. it makes sense it is a math intensive area with multiplication.

it is this here: it takes 145000 microseconds to run on nano currently
sub_calc_irData = sub_calc_irData - ExtractOffsetParametersRawPerPixel(pixelNumber)*
(1 + ExtractKtaPixelParametersRawPerPixel(pixelNumber)*(sub_calc_ta_MINUS_25))*
(1 + ExtractKvPixelParametersRawPerPixel(pixelNumber)*(sub_calc_vdd - 3.3));
and now for the next large cycle time item: 500,000 microseconds
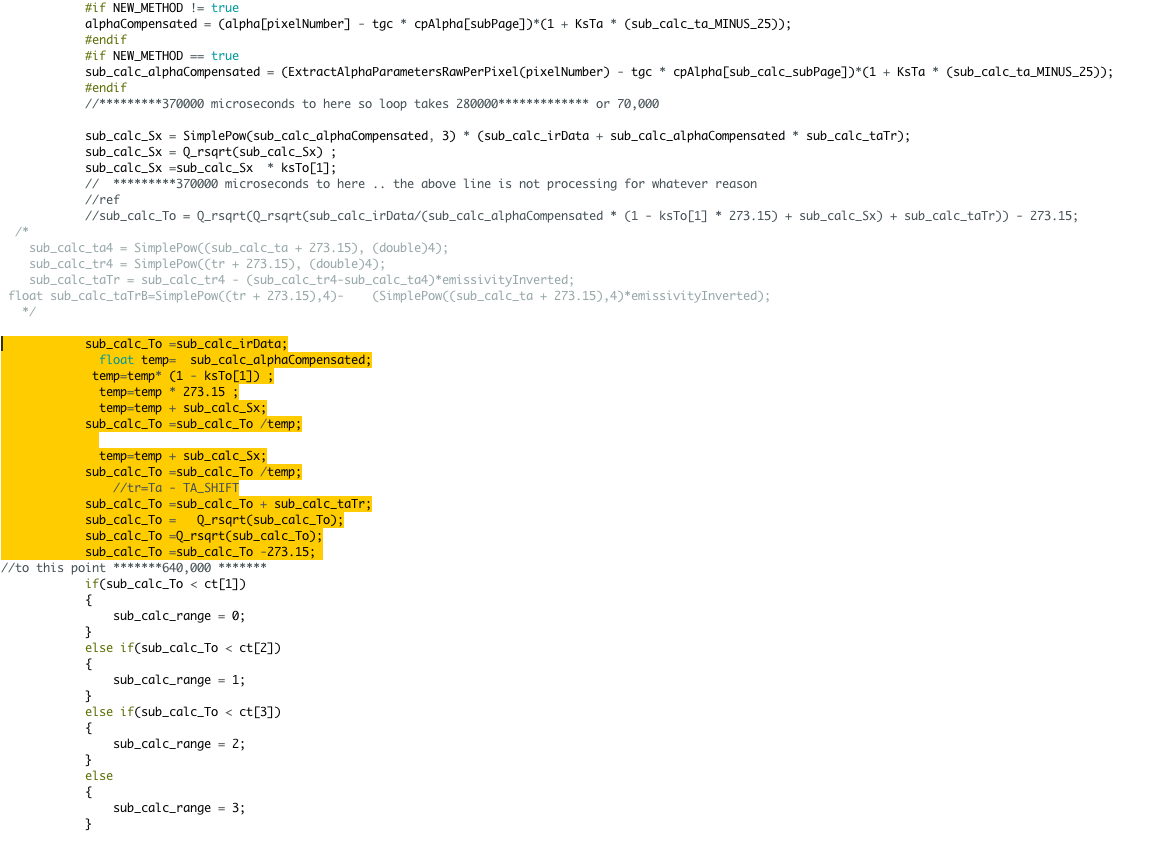
i was curious why this line didn't take any cycles:
sub_calc_irData = sub_calc_irData - tgc * sub_calc_irDataCP[sub_calc_subPage];
the answer is it is removed from compiler. tgc normally is set to 0. document melexis section 11.1.16.
wasn't sure why this wasn't taking time either
sub_calc_Sx = SimplePow(sub_calc_alphaCompensated, 3) * (sub_calc_irData sub_calc_alphaCompensated * sub_calc_taTr);
sub_calc_Sx = Q_rsqrt(sub_calc_Sx) ;
sub_calc_Sx =sub_calc_Sx * ksTo[1];
ill look into it but the big culprit of processing time is the following below.
i have broke it down into sections this entire process is the complex equation for To calc.
this section alone takes 500,000 cycles to complete
sub_calc_To =sub_calc_irData;
float temp= sub_calc_alphaCompensated;
temp=temp* (1 - ksTo[1]) ;
temp=temp * 273.15 ;
temp=temp + sub_calc_Sx;
sub_calc_To =sub_calc_To /temp;
temp=temp + sub_calc_Sx;
sub_calc_To =sub_calc_To /temp;
//tr=Ta - TA_SHIFT
sub_calc_To =sub_calc_To + sub_calc_taTr;
sub_calc_To = Q_rsqrt(sub_calc_To);
sub_calc_To =Q_rsqrt(sub_calc_To);
sub_calc_To =sub_calc_To -273.15;
so the two things i'll try to optimize further are
sub_calc_irData 145,000
the first sub_calc_To calculation 500,000
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.