 Alastair Hewitt
Alastair HewittThere was a six month pause in software development, which wasn't such a good idea. It's taken a while to get back up to speed and get to grips with the remaining "minor" bugs/features. These are all hard problems like race conditions and the binary-mode serial interface. This log explains one such race condition.
The following eye charts show the context switch sequence and message flow for requesting a RAM-disk record (discussed in the Kernel section of this log). The sequence is basically kernel-cpm-kernel-disk and originally all the disk quadrants were sequenced together (show below). The advantage of this is the ability to complete a full disk operation with only 8 context switches.
[ 1 = Kernel, 2+3 = CP/M, 4+5+6+7 = Disk Quadrant ]
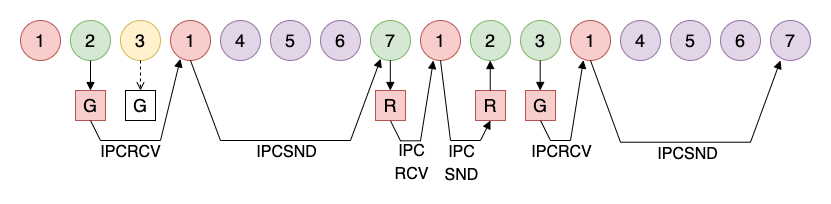
One disadvantage is that all kernel operations require an 8-cycle turn around. This means just printing a single character to the console will take 8 context switches... such is the life of a micro kernel. One way to improve this is to scan only one disk quadrant per sequence. This increases the maximum disk operation (cpm-kernel-disk-kernel-cpm) to 16 cycles, but reduces the console turn around (cpm-kernel-cpm) to just 4 cycles.
There is one issue with the approach and that's the possibility of dispatching multiple requests to the same disk quadrant before that quadrant is reached. This turns out to be quite likely when the machine is booting up. Both the TTY and CRT instances of CP/M boot up in lockstep. They both dispatch a request for the same disk quadrant around the same time and the second request gets dropped.
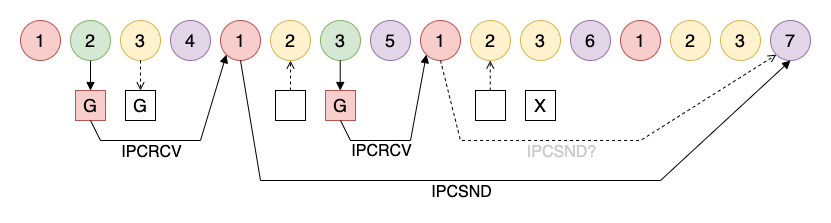
Apparently this was a know issue with the classic "TODO" comment in the code...
@@ -161,7 +163,7 @@ HANDHL: ADI BASEPG ;A=BASEPG+CPU#
;
SNDRET: DW IPCSND ;SEND MSG, EXPECT RETURN
ORA A ;A==0?
- JZ WAIT ;TODO: HANDLE ERR
+ JZ IPCERR ;HANDLE ERR
SETRET: CALL HANDHL ;HL=HANDLER
MOV M,C ;CMD=C
LDA SRCCPU
@@ -172,6 +174,12 @@ SETRET: CALL HANDHL ;HL=HANDLER
INX H
MOV M,D
JMP WAIT
+
+IPCERR: LDA SRCCPU
+ MVI B,0
+ DW IPCSND
+ JP WAIT
+
The IPCSND instruction returns zero in the accumulator if the destination CPU is not expecting a message**, e.g. if it just received one from another process. The error is now handled by clearing the sequence number in the originating command and returning a message in the same thread. The CP/M BIOS will retry the disk operation if this occurs.
** Update: "not expecting a message" was the CPU not in the wait state, but it has now been updated to include both not sleeping OR sending a command. This was causing another race condition that showed up after the previous one was fixed.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.