 biemster
biemsterThe dictation.config seems to be the file used by GBoard to make sense of the models in the zipfile. It defines streams, connections, resources and processes. I made a graph of the streams and connections:
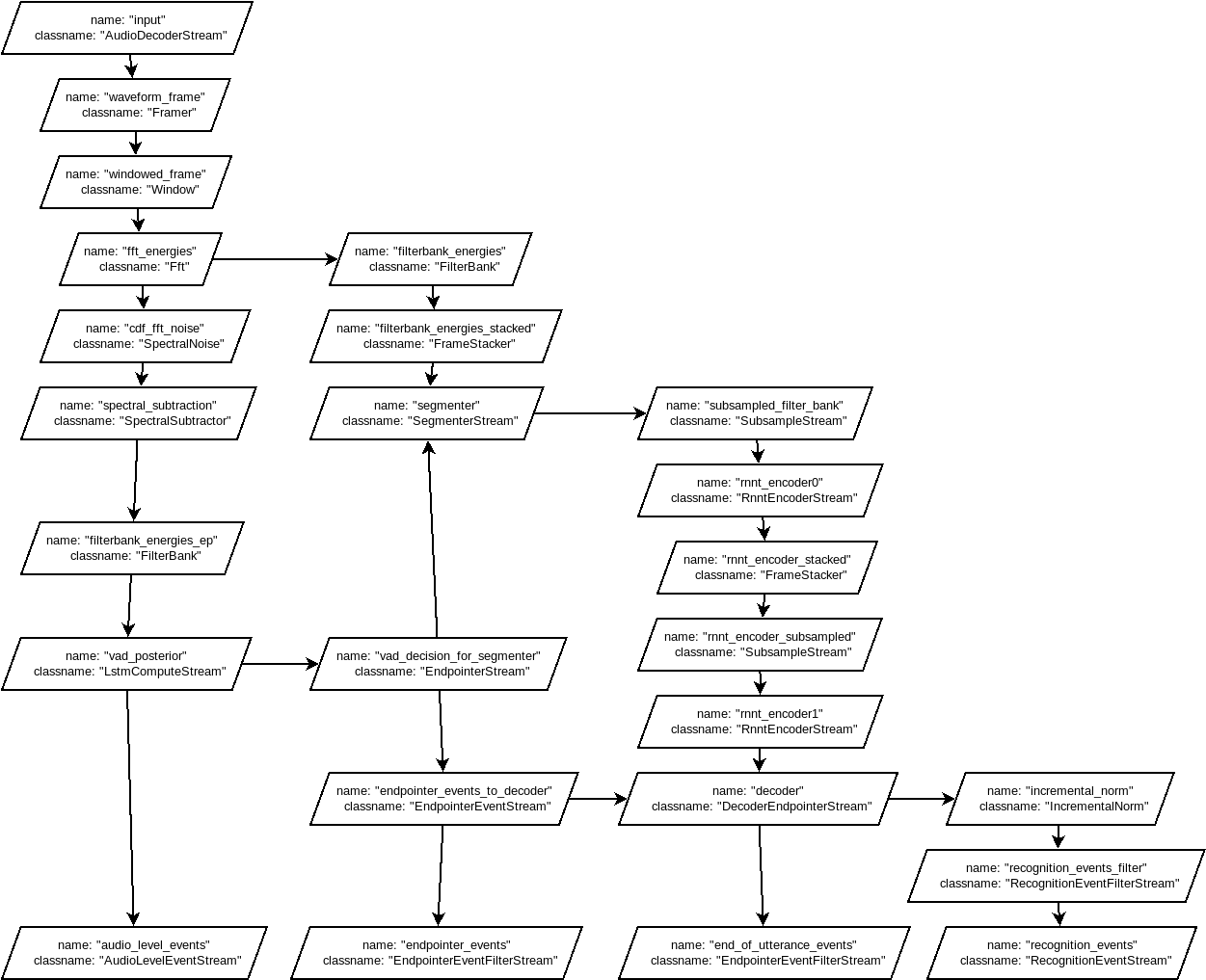
It starts with a single input, as expected the audio stream. There is some signal analysis done of course, before it is fed to the neural nets. If I compare this diagram with the one in the blog post, there are a couple things unclear to me at the moment:
- Where is the loop, that feeds the last character back into the predictor?
- Where does the joint network come in?
The complexity of the above graph worries me a bit, since there will be a lot of variables in the signal analysis I will have to guess. It does however seem to indicate that my initial analysis on the 'enc{0,1}' and 'dec' binaries was incorrect, since they are simply called in series in the above diagram.
This whole thing actually raises more questions than it answers, I will have to mull this over for a while. In the mean time I will focus on how to read the 3 binary nets I mention above.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.