Last weekend I thought quite a way ahead, in terms of where the architecture needs to end up, and wrote up the basic requirements I have for this project, which you can find in the project's Details section.
There are still a lot of open questions about the designs I sketched out last time - in some respects they don't fully achieve what I wanted, but they're already getting complex and I don't want to overthink them at this stage. Instead I want to plan some steps along the way to getting to a point where I can make better decisions about those designs from experience based on earlier prototypes.
Roadmap
So here's the initial roadmap. I'm only planning the first few stages - later stages are subject to change as I go through:
- Base computer - start from a working base and extend from there
- Prototype 0a - adding paging and cooperative multitasking, but without expanding to more RAM, and without memory protection yet
- Prototype 0b - adding pre-emptive multitasking (unless I decide to defer that)
- Prototype 1 - adding simple memory protection so processes can't interfere with the page table
- Take stock and make a better plan for the next steps
When I get to (5), it's likely that I'll have discovered some major architectural changes I'd like to make. But aside from that, I would expect to work through some higher-priority features, such as:
- Critical API refactoring
- Add more RAM - I have 512K on hand for this
- Move decoding to after the page table
- Use a PLD for the decoder if I haven't already
- Add R/W/X permissions, may need to expand the page table output width to 16 bits
There are also some lower priority features that I'd probably go on to after that:
- Non-critical API refactoring
- Software features - IPC, semaphores, etc
- Recovering from locked-up processes (e.g. illegal instructions)
- Multithreading
This is just a rough list though and again I'm not thinking too carefully about the order of things that far ahead.
1. Base computer
First and foremost, I don't really want to build a fresh computer from scratch. I'd rather extend one of my existing ones, and I have a plan for how to do that.
I'll use my main homebrew computer, which was my own design from the ground up, and incorporates in particular a video output subsystem as well as a 6522 providing multiplexed I/O to an SD card reader, an LCD and some buttons, a digital tone generator, and an addressable latch because you never know what you can never have too much addressable I/O. It also has a debug port that will come in handy here.
Those modules aren't exactly necessary for this, but the video output will be good to provide a convincing demonstration that it's all working - because it provides a clean way to see output from several processes in parallel without needing any software semaphores etc - and the rest of the I/O is useful because I also want to explore ways in which the processes can be given selective access to I/O devices without completely breaking the protection layer.
The basic architecture there is fairly standard, and I've uploaded a block diagram of it:
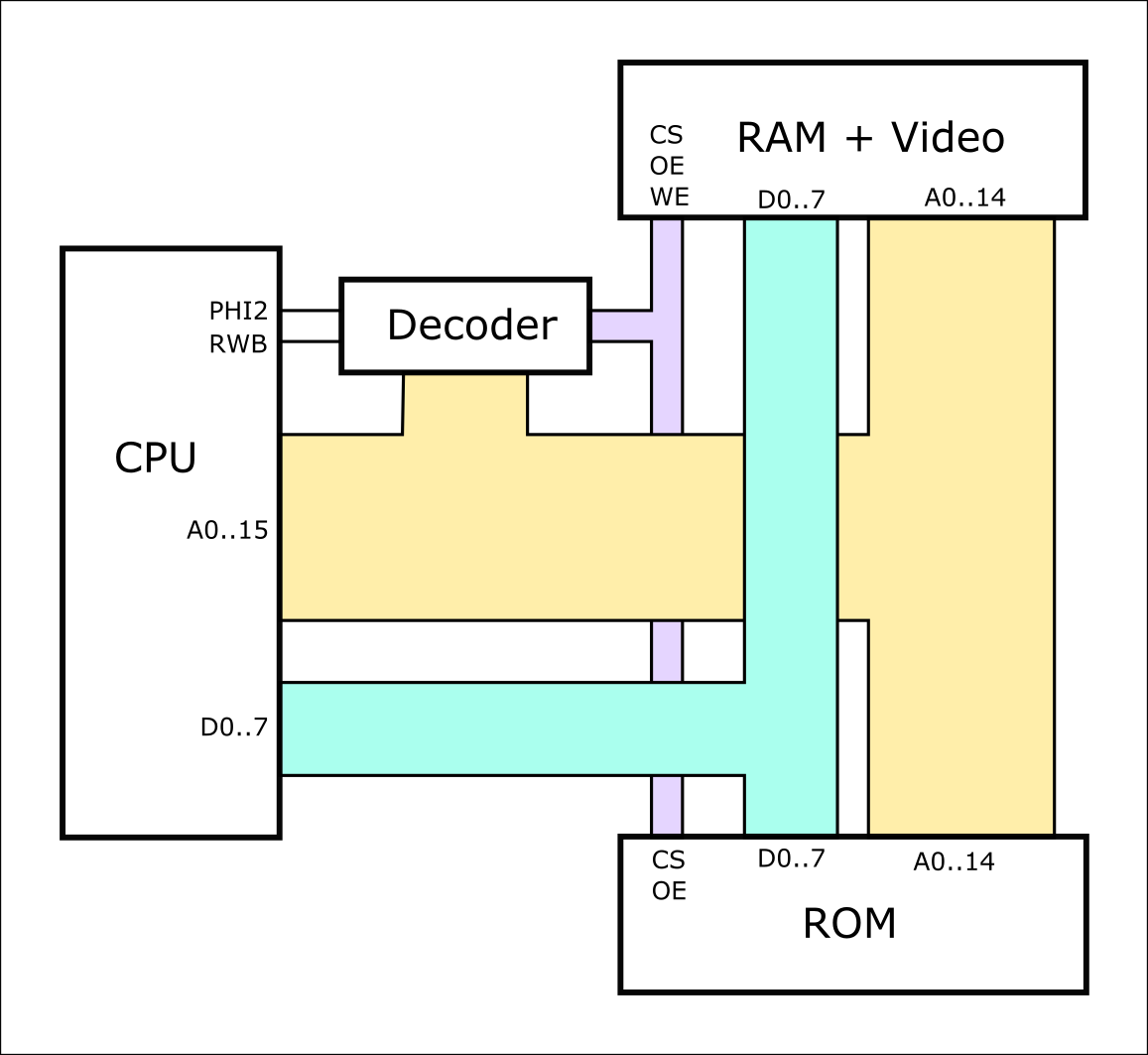
There's nothing unusual about this, except that I've lumped the video decoder into the "RAM" box, because the CPU's view of it is just like normal RAM - all the CPU's RAM is actually inside the video circuit. I didn't draw the I/O on here either, but it's just more of the same.
2. Prototype 0a
Next up, what's are the minimal changes I can make here, to achieve Prototype 0a? All I want to do for this is add process-based memory paging, so that two independent processes can coexist and run cooperatively without fighting for memory.
Two key components are a hardware notion of "process ID" or "PID", and a page table for tracking which physical RAM locations are used by which logical addresses, for each process. Initially I'm locating the page table in a separate RAM chip for reasons I'll explain below. Here's the updated block diagram:
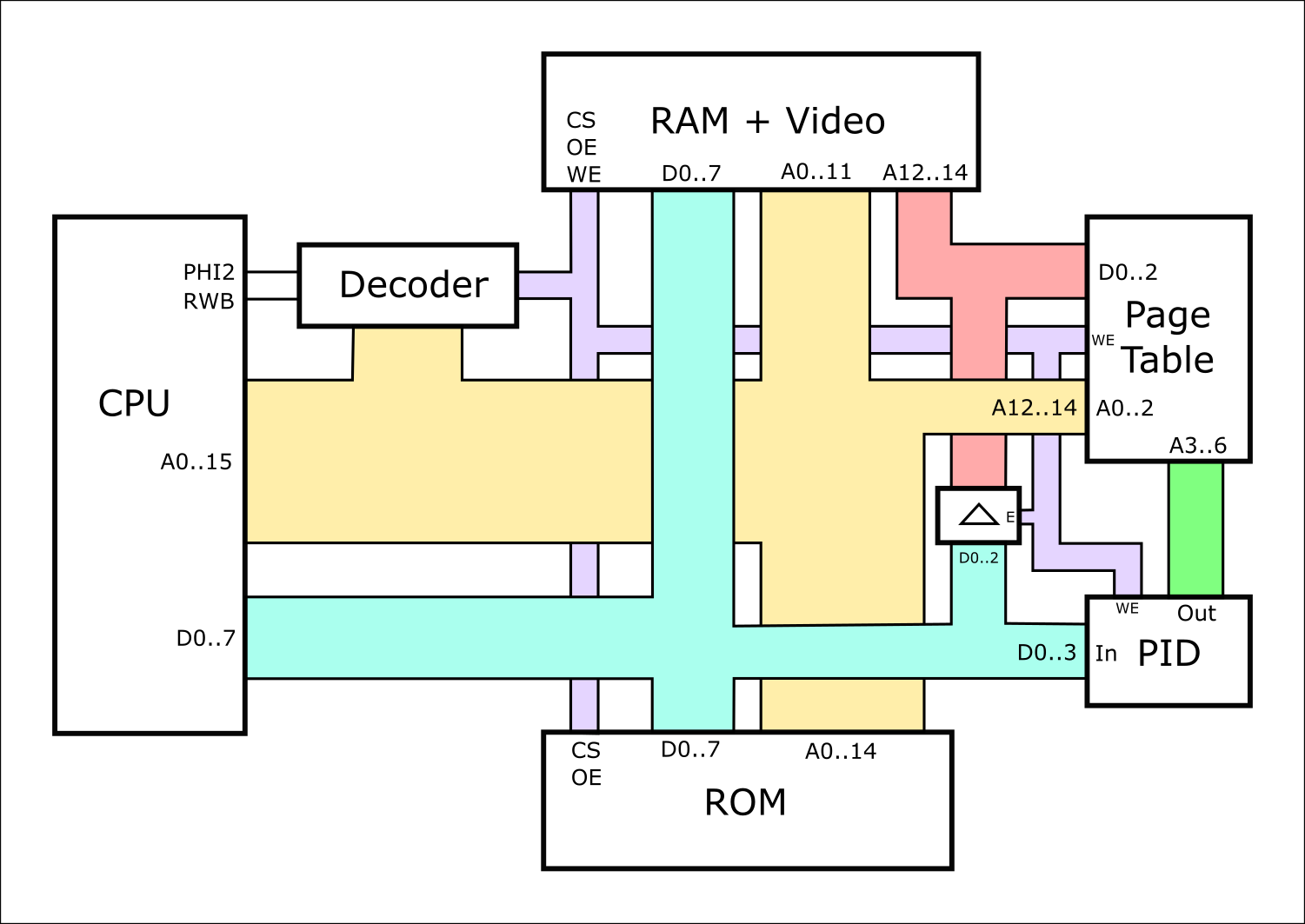
The changes are all on the right hand side. Instead of routing A12..14 through to the RAM, they go into the address pins on the Page Table (PT). Then the PT's data pins drive the RAM's A12..14 lines. So the actual physical RAM address is remapped by the PT.
In addition there's an 8-bit register to store the Process ID (PID). This also feeds into the address lines of the PT, meaning that each process has its own distinct mapping of A12..A14 values.
Writing to the PID and the PT
The PID can be written from the data bus, under control of an I/O enable line from the decoder; and the PT can also be written based on another decoder line which controls the PT's Write Enable pin and also the Enable pin of a bus buffer or transceiver, allowing the data bus to write through to the PT's data pins. I'm actually just using resistors for this at the moment, to save putting a transceiver in - so that the short bus from the PT to the RAM will be driven weakly by the data bus any time the PT itself isn't driving it - but that's very lazy of me.
This general mechanism of writing to the PT is simple in hardware, but complex in software for two reasons. Firstly, I normally use A12..14 as part of the decoding process - when A15 is set - to choose whether ROM or I/O is being accessed. But when writing to the PT, it requires A12..14 to choose which PT entry to write - so I need to use some other address bits to actually enable the PT write in the decoder. Ultimately I use A15 && A11, and the addresses I end up writing to are $8FFF, $9FFF, $AFFF, etc - to write entries for page 0, page 1, page 2, etc. Not very tidy! These writes conflict with ROM a lot of the time, and other I/O devices some of the time, so it's important that those devices that are conflicted with are themselves read-only. For now I'm OK with this but I'll need to update the decoder soon as it's not really sustainable like this.
The second complexity is that when we write to the PT for a user process, the actual write needs to occur with the PID set to the target process's ID. In this state, any RAM accesses will be mapped according to the user's memory map, not the supervisor's. This means that we can't access the supervisor's zero page, stack, etc. until the write is done. But writing to an arbitrary location spread across the high half of the memory map is only possible if you do it indirectly via an address stored in zero page. So we need to reserve a few bytes of zero page in the user's memory map for OS use. It's ugly because in general we don't need to do this - the supervisor has its own, separate zero page, and user processes don't need to reserve any.
In the long term I am going redesign the hardware to solve both these problems - it will probably involve some encoders on the PT's address inputs to allow the supervisor to inject any data it wants there, rather than having to rig the PID and A12..14 to the correct values. It can be triggered by the same signal as the (missing) data bus transceiver. But for now I can just about get away with not doing this yet, and the idea of this first prototype was to make the hardware changes as simple as possible, and make up for any issues in software.
Software
On the software side, I branched my regular 6502 code repo and hacked some new functionality into the OS code as a proof of concept. On startup it immediately sets the PID to zero and maps logical page zero to physical page one, by writing a 1 to $8FFF. This is to ensure that the supervisor has some RAM, and in particular a stack.
It then proceeds to create two processes, each with its own separate logical page zero, and with its logical page 4 mapped to different areas in video RAM. I picked page 4 because that's where the start of video RAM normally is on my computer, and so all the text output routines etc are happy to write there. But at the physical level, one maps to page 4 and the other to page 6, so the two processes end up writing to different parts of the screen.
The processes are then added to a "run queue" - a list of processes that can be executed - and a very basic scheduler hands over control to one of the processes, mostly by setting the PID register and executing an RTI.
The process runs until it issues a BRK instruction, at which point the OS interrupt handler executes. This is my usual code for handling interrupts - it determines that the interrupt came from a BRK and calls a BRK handler. This all runs within the context of the user process, because detecting BRK requires us to read from its stack - that's possible for the supervisor by changing its own memory map, but I didn't want to bother with it. Once the interrupt cause is identified, the BRK handler runs, and this saves the registers and stack pointer at $100-$103 and then reads the BRK data byte into the A register before entering supervisor mode.
Entering supervisor mode is achieved by setting the PID register to zero, setting the stack pointer to $FF, and clearing the X and Y registers. The A register still contains the command code from the byte after the BRK instruction. The supervisor doesn't have any important state to restore on returning from user mode, so clearing all these things to standard settings is good practice to remove potential for userspace to exploit any bugs due to them being unset.
At this stage the BRK command code is just ignored, as there aren't any functions provided by the OS yet. One day user processes will be able to request more memory pages, terminate, spawn other processes, perform I/O operations, and do inter-process communication. Right now though the command is a no-op, and just serves to yield to the supervisor.
The supervisor then returns to userspace by telling the schedule to pick a new runnable process and resume it. The procedure for that is exactly as before, ultimately executing an RTI in the processes context, which will resume from after its BRK command byte.
Prototype 0a status
So this is all working now, and I can run multiple processes, with each outputting to a different region of the screen, with their zero pages and stacks in separate banks of physical RAM. I might capture some video footage of it working and upload that. But then it'll be time for Prototype 0b!
3. Prototype 0b
This is planned to be just a small update to add pre-emptive multitasking. It shouldn't be a big deal, it just requires setting up an external timer source. I might pull an existing time signal from the video system (e.g. the hsync or vsync) or something like that. The 6522 is actually not plugged in at the moment; another option is to plug that back in and use one of its own timers.
The general idea will be driving NMI to cause an interrupt (which the process won't be able to block with SEI). This will then enter through the NMI vector and forcibly suspend the process in much the same way that I already do for the IRQ vector when BRK occurs. The NMI handler won't do anything fancy at this stage - just as with BRK, all it will do is save the process state so that it's able to be resumed later on, and then chain to the scheduler.
4. Prototype 1
The purpose of Prototype 1 is to finally add memory protection, and this is what qualifies it to have a version number of 1!
While the user processes in Prototype 0 have separate views of memory, by virtue of having different page table contents - and their page table entries don't map memory that the user process isn't meant to access - they still have full access to rewrite the PT and PID register in the same way the supervisor does, by writing to $8FFF, $8200, etc. A user process could very easily write a 1 to $BFFF, meaning that its own logical page 3 gets mapped to the physical page 1 - and that's the same physical page that the supervisor's logical page 0 is mapped to. Now it can corrupt the supervisor's memory, where it stores things like the list of active processes. Or it could map a different physical page, and access memory belonging to a different user process.
Clearly we need to prevent user processes from doing these things. As discussed in earlier log entries, one easy way to do this is by adding a hardware flip-flop that records whether the system is in user mode or supervisor mode. This needs certain logic to flip its state at the right times - again I discussed a lot of options there in an earlier log.
Another option was to gate supervisor mode based on the current PID value - this is appealing because it doesn't require adding any new hardware components, but it would break the existing prototype because the supervisor needs to set the PID before being able to configure the PT for a user process, and this would essentially take it out of supervisor mode into a state where it no longer has permission to write the PT.
I've also considered using the top bit of the PID register to indicate user status - so the supervisor can make sure not to set that bit until it's really ready to hand control to a user process. When setting up the PT, etc, it will leave that bit clear and just set the lower bits to control the PT address pins. It will still be necessary to have a controlled entry into supervisor mode, which could be achieved by simply clearing the PID register, if I use a register with a clear pin.
I'm still in the frame of mind to do the simplest thing that reasonably achieves my goal, and am avoiding adding a lot of hardware. But a further option here is to swap some existing hardware - the decoder is currently built from some logic gates and a 74HCT138, and I could replace it with a PLD and achieve the same logic functions plus storing a supervisor bit or whatever else I want to do, all in one chip. So it's adding one complexity while removing another.
I might want to explore the non-PLD options first, as the goal of this project is to experiment with different things, but I'm pretty certain I'll end up going with the PLD in the end, as it will resolve a lot of problems that I know I already have in Prototype 0a.
5. Beyond!
As I said, I don't want to speculate too much on what's beyond. But I will say that performing the decoding before the PT's address translation is not ideal. It means that user processes can't easily be given access to I/O devices (which may not be a bad thing), and it means user processes lose as much of their address space as the supervisor needs in order to manage the I/O devices, and access its ROM code.
Choosing a PT address based on the CPU's high address bits and the PID content is also not great.
It would be very appealing to move the address decoding to occur after the address translation - i.e. hook the PT up directly to the CPU, with the decoder being based on the remapped address it outputs. This would solve both the above problems.
The drawbacks are that it's critical that the PT actually has some sensible data in it on power-on reset, as the CPU won't be able to initialize it directly without it already being set up; and actually writing to the PT is going to be complex because the PT itself is "in the loop" during the write cycle. What I mean is, in order to write to the PT we'll need to write through some logical address that the PT itself will remap, before it hits the decoder, and the decoder then says "this is a write to the PT". Now we need to swap the PT from output mode into write mode, give it a totally different address, and connect its data bus to the CPU's data bus. In the meantime we need to latch the fact that this is what we're doing, as otherwise while we do this the decoder is going to stop saying "this is a write to the PT".
There are two main ways I can envision doing that, but I haven't thought them through yet. One is to write to some other latches, then arrange for those to have their values written into the PT after PHI2 goes low. It's important that the PT is back in output mode well before PHI2 goes high though, to meet address setup requirements on writes to RAM etc. But this could work.
The other way is to latch a flip flop when PHI2 rises based on whether it's a PT write cycle, and if it is, swap the state of some encoders so that the PT's address pins come from lower CPU address bits rather than the usual places. The data lines are already catered for in my current setup. This means the PT is going to see a shortened "write" signal, but I use very fast RAM as a matter of course, so this shouldn't be a problem (my video output circuit does the same thing).
But that's a decision I'm not going to make yet! One step at a time, simplest things first...
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.