 Yann Guidon / YGDES
Yann Guidon / YGDESFor this system I have used and abused several allegories to guide the design: token ring, trains on a track, JTAG... And now I'm adding Tetris (with only one column) and 1D cellular automata, because the system reminds me of the "sandpile" 2D CA I used to play with 15 years ago.
The transition rule is probably the most basic you can find:
if node[n] has data and node[n+1] is empty, then node[n+1] copies node[n] then clear node[n]
In other words, huh, pixels:
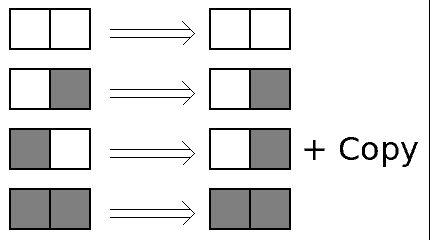
When applied to a whole row of nodes, the final effect is that all the grey/occupied nodes will shift to the right, toward the reading end of the chain.
Now, the insertion of new data adds a bit of complexity to this bare system but it's still manageable. The insertion part can be seen as added states to the CA and the trick is to modify them adequately. The nodes' state must also consider the need to send a message when a job is finished.
Update:
I write a simulator in JS to dynamically play with the early incomplete implementation: 1dcasim_5.html.txt
One notable limitation and characteristic is how the "bubbles" of free slots migrate to the start. The rule states that for one word to shift to the end, 2 nodes have to be considered, with a specific configuration (1,0). Hence, for a moving string of data, the only possible configuration is a repetition of (0,1,0,1,0,1,0,1,...)... Which has 2 consequences:
- The maximum bandwidth is clk/2 because half of the slots are empty. In this case, not a problem because the host is quite slow, so the bus could be even further reduced in width.
- More critically, the "insertion" of a string of words must consider more factors, in particular the state of more than one or two nodes, and/or the type of the node at the current position...
Simulations are precious and JS/HTML ones are great and flexible, I will refine the algorithm little by little and post new versions.
Now that is better than a laborious textual explanation :-)
Re-update:
I just uploaded 1dcasim_7.html.txt and it seems to work well! The key to this is a careful priority system where the precedence changes according to the state of a node: either idle, requesting to send, or sending.
- By default, nothing happens. The current word in the node is unchanged.
- If the node is in sending state (it has already sent its first world so the counter is 1 to 3) then it waits for its own word to have been copied, before writing a new one (and update the counters).
- If it is in "send request state" (counter is 4) then the node waits for its own state and the previous to be free. This ensures that no message already flowing will be interrupted. If this condition is filled, then the node sends its first word and decrements its state/counter.
- Otherwise, the node is in "pass-through" behaviour, letting other words pass and be written from the previous node to the current one.
Play with the HML sim and tell me what you think!
The priority mechanism is not too bad, it privileges the node near the start of the chain though it can also block others as well once started. As already noted, precedence is not critical in this application.
This algorithm is not "the fastest" in terms of pure absolute throughput but this is compensated by its raw speed through sheer simplicity and the very small amount of signals that are exchanged between the nodes (and their complexity). A simpler design will run faster, particularly at this level of granularity. Between two nodes, we find 3 signals :
- Data word (any width) (forward direction)
- Empty signal (derived from the above, needs a few bits of decoding)(forward direction)
- ACK/CLR signal (backward direction)
Fewer signals, faster decoding, shorter clock cycles overall. So, apart from the shared RESET and CLK global lines, each node only has these signals:
- Word_in
- Word_out
- CLR_in
- ACK_out
- Not really a signal but a constant/generic: the node's individual address.
The start and end nodes have only the appropriate signals.
Now I just have to implement the corresponding VHDL...
Re-re-update:
The JS simulator is still in development and I refine the addressing system. Refine and simplify, as there are now only 3 types of words:
- empty words
- address words
- data words
Encoding is straight-forward:
0xxxxxxx... : empty
10xxxxxx... : address
11xxxxxx... : dataIn the JS sim, I simply use 0 for empty, > 1 for data and < 1 for address (×-1)
The catch is that each address expects to receive and emit fixed-size messages: 2 for reception and 4 for emission. Each node has their simple FSM to manage this. This reduces the size of the words to transmit between nodes and simplifies the FSM a bit, as there is no sequence number to check : after the address is recognised, "just swallow" the next word (in the case of node reception).
.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.
I think that I would have understood it from the verbal description alone but the simulation made it very much easier to comprehend the effect of the design! It's surprising how little HTML, CSS and JavaScript is necessary for something that is this useful.
This said, this continues to be an excellent and inspiring insight into an exploratory engineering method that does education by example!
Are you sure? yes | no
Thank you !
The added bonus : it makes totally sure that the idea works.
If you look at the logo of #PDP - Processor Design Principles you will see that the inspiration feels good until you test it and realise there is no power source.
Without testing, I would have kept the first idea and made it more complex than necessary. Testing it made me understand the flaws so I can revise my assumptions.
And, before simulations, there are sketches, a lot of diagrams and drawings...
Are you sure? yes | no