 Yann Guidon / YGDES
Yann Guidon / YGDESThe PEAC started as a checksum algorithm and soon the corresponding generator had to be studied. As noted in one of the previous logs, there are also counterparts: the scrambler and its inverse, the descrambler.
Let's start with the generator:
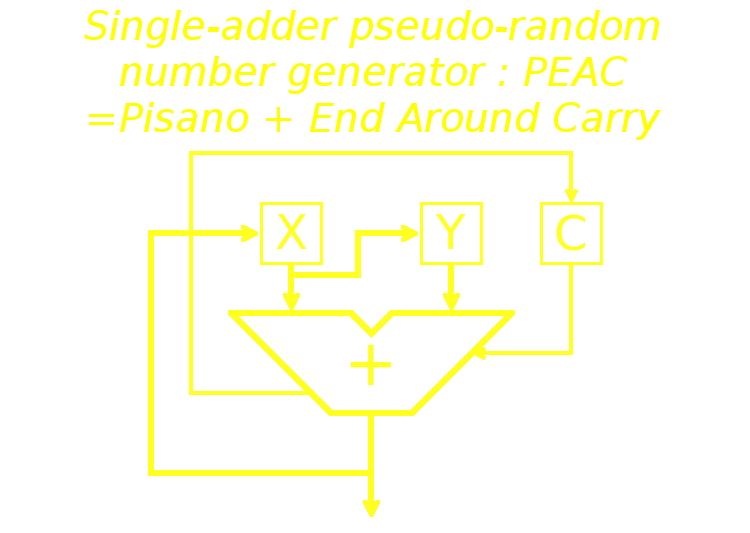
That's simple and it is already characterised. The code is easy and has already been covered:
uint16_t PRNGX,
PRNGY;
uint32_t PRNGC;
uint16_t PRNG() {
PRNGC += (uint32_t)PRNGX; // \_ actually a single adder
PRNGC += (uint32_t)PRNGY; // /
PRNGY = PRNGX;
PRNGX = (uint16_t) PRNGC;
PRNGC >>= 16;
return PRNGX;
}
Then, add an adder in parallel and you get a checksum: instead of outputting a data stream, it inputs a data stream.
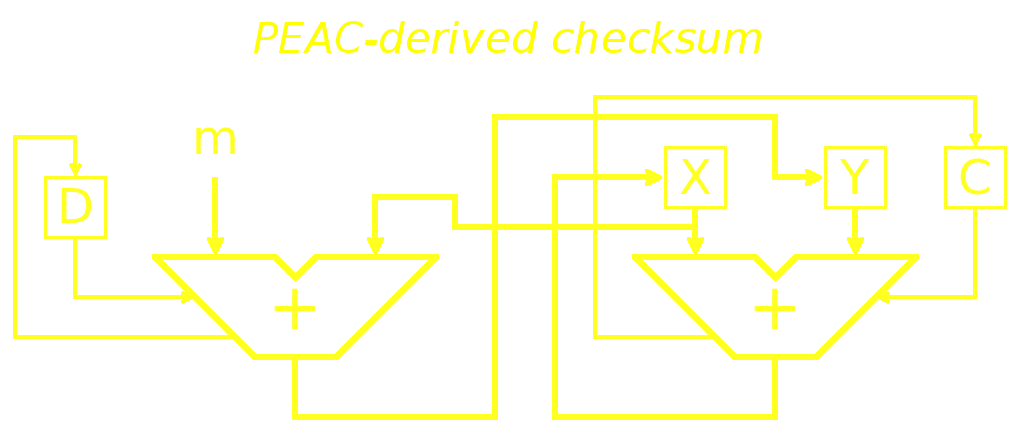
Then the checksum is contained in X and Y.
uint16_t CHKSX;
uint32_t CHKSY,
CHKSC;
void CHKS(uint16_t m) {
// extra caution with the extension of the sizes:
CHKSC += CHKSX; // 0..10001
CHKSC += CHKSY; // 0..2FFFF
CHKSY = CHKSX + m; // 0..1FFFE
CHKSX = CHKSC; // 0..FFFF
CHKSC >>= 16; // 0, 1 or 2
}
This version uses a clever trick to use only one carry with multiple values, which is better of SW and HW will use the above diagram.
But it is possible to do both, input and output! That's what the scrambler does. It receives a message word that is mixed with X and directly outputs the resulting sum.
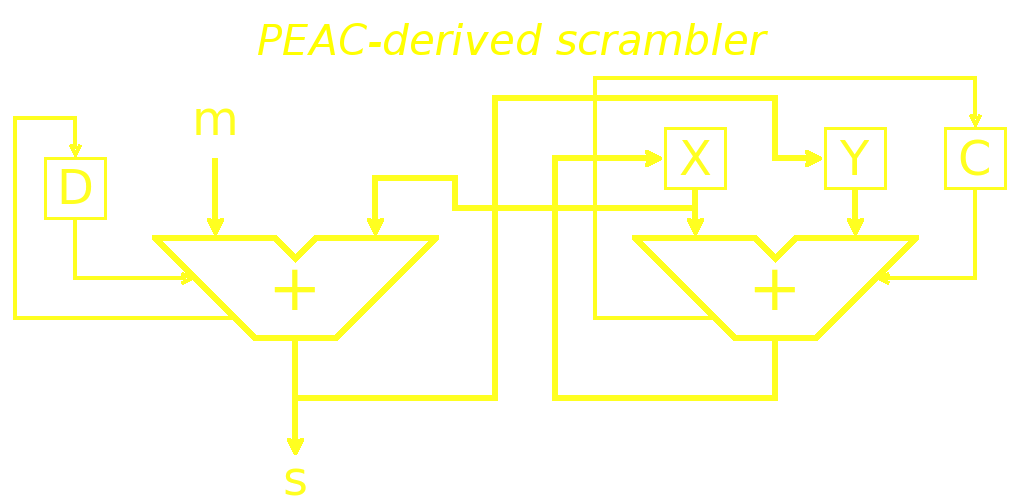
That's it: all you have to do is add an output, or read the Y variable.
To unscramble this, we have Y = s = m+X, so we recover m with m = s - X, and put s directly into Y.
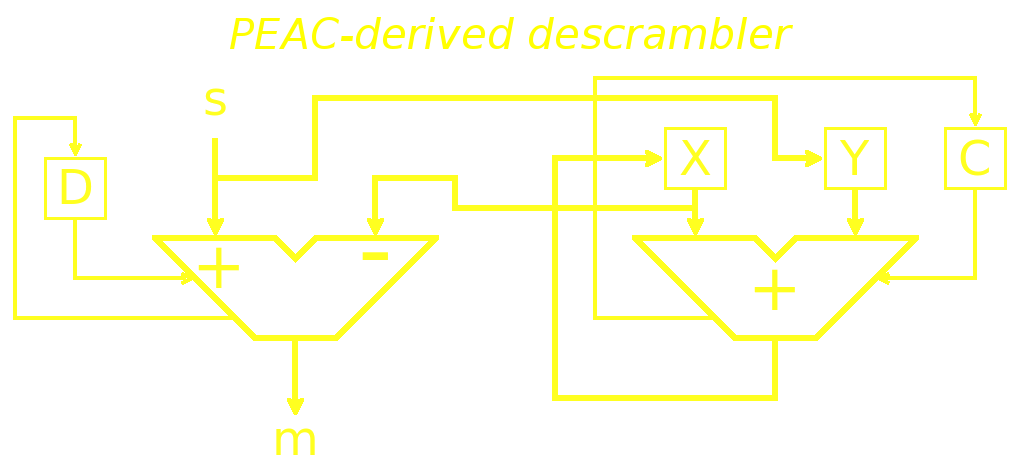
So here you have the 4 variations on the theme of PEAC and the code can be found at snippets_v3.c.
Note that there are 2 incompatible versions of the scrambler (and matching descrambler). One with no carry (the values are truncated and there is no D flag) and the other with the Carry / D flag.
///////////////////////////////////////////////////
///////// Scrambler sans carry:
uint16_t SCRX,
SCRY;
uint32_t SCRC;
uint16_t SCR(uint16_t m) {
SCRC += (uint32_t)SCRX; // \_ actually a single adder
SCRC += (uint32_t)SCRY; // /
SCRY = SCRX + m; // mod 65536
SCRX = SCRC; // mod 65536
SCRC >>= 16;
return SCRY;
}
///////// Descrambler :
uint16_t DSCRX,
DSCRY;
uint32_t DSCRC;
uint16_t DSCR(uint16_t s) {
DSCRC += (uint32_t)DSCRX; // \_ actually a single adder
DSCRC += (uint32_t)DSCRY; // /
uint16_t m = s - DSCRX; // mod 65536
DSCRY = s;
DSCRX = DSCRC; // mod 65536
DSCRC >>= 16;
return m;
}
///////////////////////////////////////////////
///////// Scrambler with carry :
uint16_t SCRBX,
SCRBY;
uint32_t SCRBC,
SCRBD;
uint16_t SCRB(uint16_t m) {
SCRBC += SCRBX + SCRBY; // 0..1FFFF
SCRBD += SCRBX + m; // 0..1FFFF
SCRBX = SCRBC; // 0..FFFF
SCRBY = SCRBD; // 0..FFFF
SCRBC >>= 16; // 0..1
SCRBD >>= 16; // 0..1
return SCRBY;
}
///////// Descrambler v2: borrow :
uint16_t DSCRBX,
DSCRBY;
uint32_t DSCRBC;
int32_t DSCRBD;
uint16_t DSCRB(uint16_t s) {
DSCRBC += DSCRBY + DSCRBX;
DSCRBD += s - DSCRBX;
DSCRBX = DSCRBC;
uint16_t m= DSCRBD;
DSCRBY = s;
DSCRBC >>= 16;
DSCRBD >>= 16; //signed shift !
return m;
}
The carry-less scrambler is alluring, being slightly shorter and potentially a tiny bit faster (in SW at least) but it suffers from poor avalanche behaviour. The carry-enable scrambler is more solid, and in HW the difference is too small to care. The double-carry scrambler is preferred though the single-carry one is kept for reference, as a necessary step to build the better one. I'll see if or how I can generate a better version that merges a variable.
Note that these scramblers process 16 bits at once, while LFSRs usually only process one bit per cycle. LFSRs are also susceptible to stalling, unlike these scramblers. The only thing LFSRs can claim at this point is better mixing/avalanche, though that could also be "fixed".
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.