 kutluhan_aktar
kutluhan_aktar- First of all, in that regard, it requires us to have some preliminary information about food ingredients to interpret their health stats.
- For some of us, it can be struggling to inspect packaging information on ingredients, for instance, elderly and children.
- And, most of the time, food packaging includes limited and constricted nutritional facts for us to decide whether it is a portion of healthy food or not.
Aside from the dearth of support worldwide, there are several well-developed approaches for categorizing foods using nutrient profiling, which directly present the health stats of a food product. As discussed by WHO, it is crucial to develop a nutrient profiling model for categorizing foods while considering the current objectives of nutrition policies: "A discussion on nutrient-profiling methods at a WHO forum and technical meeting on marketing in 2006 recognized the contextual nature of the task, namely that nutrient-profiling systems should aim 'to categorize foods according to their nutritional composition while taking into account current objectives of nutrition policies'. The objective in most cases is to increase the proportion of the population adhering to national food-based dietary guidelines.[1]"
Furthermore, as shown in most studies, having a well-developed and easy-to-understand nutrient profiling system can change our overall perspective when purchasing foods at food stores, restaurants, etc. "The development of nutrient-profiling schemes is clearly beneficial in a wide range of applications, both commercial and health-related. For instance, the use of nutrient profiling to support the European health claims regulations is under consideration by the European Commission. Similar measures can be suggested for catering outlets, where a profiling scheme such as traffic light signaling could help customers select healthier items from menus in advance of ordering their food[1]."
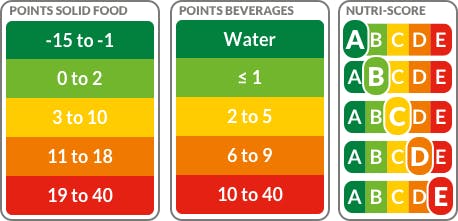
After doing some research on several nutrient profiling methods, I decided to build an artificial neural network (ANN) model based on the classification model to interpret nutrition facts and nutrient levels of various food products to predict the healthiness level of a product even with meager information in simple and easy-to-understand classes (labels). Due to its advanced scientific algorithm, I decided to utilize an improved version of the Nutri-Score system for my neural network model. The Nutri-Score, also known as the 5-Colour Nutrition Label or 5-CNL, is a nutritional rating system selected by the French government in March 2017 to be displayed on food products after compared against several labels proposed by industry or retailers. It relies on a nutrient profiling system computation derived from the United Kingdom Food Standards Agency nutrient profiling system (FSA score). For my neural network model, I improved the original scientific algorithm of Nutri-Score by adding some extra parameters:
- Calcium
- Carbon Footprint (CO2)
- Ecological Footprint (EF)
Before building and testing my neural network, I developed a web application in PHP to collate product characteristics (nutrition facts, nutrient levels, etc.) with product barcodes via the Open Food Facts JSON API. Since searching products with barcodes is the most effortless way possible to distinguish different products worldwide. Then, I created a data set of various handpicked products from the Open Food Facts database, presenting all the required information to train my neural network model.
After completing the data set, I built my artificial neural network (ANN) with TensorFlow to make predictions on the healthiness classes (labels) based on the Nutri-Score values. Theoretically, I assigned a healthiness class (label) for each product after applying my improved Nutri-Score algorithm to the data set:
- Nutritious
- Healthy
- Less Healthy
- Unhealthy
Then, after testing, I converted the TensorFlow Keras H5 model to a TensorFlow Lite model to execute it on Raspberry Pi. I decided to connect a barcode scanner to Raspberry Pi to elicit food product barcodes easily to run the neural network model with data transferred by the web application to predict products' healthiness classes (labels). In that regard, by merely scanning food product barcodes, Raspberry Pi makes predictions on the healthiness level of different foods without needing us to scrutinize packaging information.
So, this is my project in a nutshell 😃
In the following steps, you can find more detailed information on coding, data collection, building an artificial neural network model with TensorFlow, and running it on Raspberry Pi.
Huge thanks to DFRobot for sponsoring this project.
Sponsored products by DFRobot:
⭐ GM65 QR & Barcode Scanner Module | Inspect
⭐ 7'' HDMI Display with Capacitive Touchscreen | Inspect

Step 1: Developing a web application in PHP to collate data on product characteristics by barcodes
I developed this web application (Barcode Product Scanner) in PHP to collate the product characteristics (nutrition facts, nutrient levels, etc.) with a given product barcode from the Open Food Facts JSON API.
The web application includes one file (index.php) and requires only one parameter to collect information - the product barcode.
Open Food Facts is created by a non-profit association and provides a worldwide food products database. And, the Open Food Facts JSON API lets the user search a product by barcode.
💻 index.php
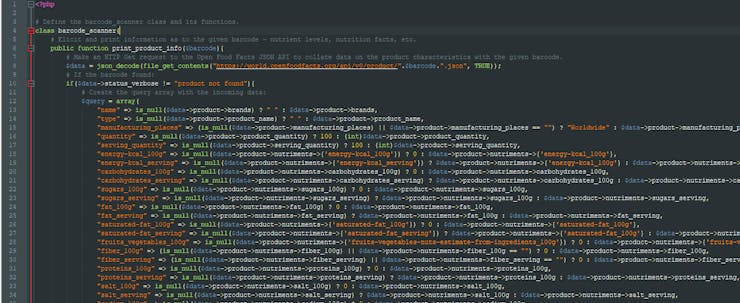
⭐ Define the barcode_scanner class and its functions.
⭐ In the print_product_info function, make an HTTP Get request to the Open Food Facts JSON API to collate data on the product characteristics with the given barcode.
⭐ Decode the incoming data, using json_decode and file_get_contents functions.
⭐ If the given product barcode is found in the database, create the query array with the incoming data after checking for null and empty variables.
⭐ Print the recent query array in JSON (json_encode) with the requested parameters:
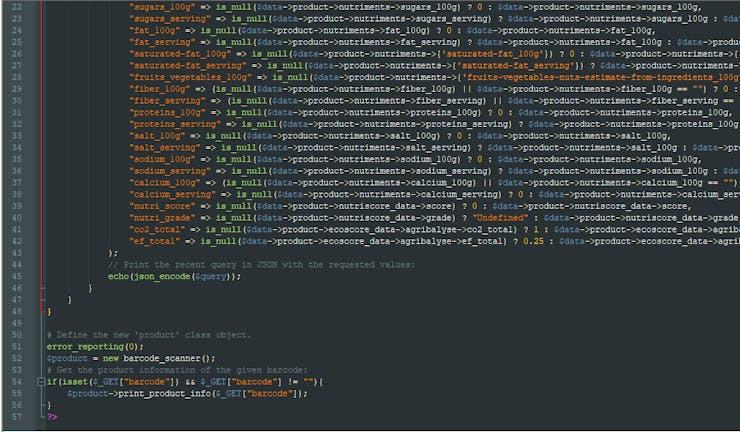
- name
- type
- manufacturing_places
- quantity
- serving_quantity
- energy-kcal_100g
- energy-kcal_serving
- carbohydrates_100g
- carbohydrates_serving
- sugars_100g
- sugars_serving
- fat_100g
- fat_serving
- saturated-fat_100g
- saturated-fat_serving
- fruits_vegetables_100
- fiber_100g
- fiber_serving
- proteins_100g
- proteins_serving
- salt_100g
- salt_serving
- sodium_100g
- sodium_serving
- calcium_100g
- calcium_serving
- nutri_score
- nutri_grade
- co2_total
- ef_total
# Elicit and print information as to the given barcode - nutrient levels, nutrition facts, etc. public function print_product_info($barcode){ # Make an HTTP Get request to the Open Food Facts JSON API to collate data on the product characteristics with the given barcode. $data = json_decode(file_get_contents("https://world.openfoodfacts.org/api/v0/product/".$barcode.".json", TRUE)); # If the barcode found: if($data->status_verbose != "product not found"){ # Create the query array with the incoming data: $query = array( "name" => is_null($data->product->brands) ? " " : $data->product->brands, "type" => is_null($data->product->product_name) ? " " : $data->product->product_name, "manufacturing_places" => (is_null($data->product->manufacturing_places) || $data->product->manufacturing_places == "") ? "Worldwide" : $data->product->manufacturing_places, "quantity" => is_null($data->product->product_quantity) ? 100 : (int)$data->product->product_quantity, "serving_quantity" => is_null($data->product->serving_quantity) ? 100 : (int)$data->product->serving_quantity, "energy-kcal_100g" => is_null($data->product->nutriments->{'energy-kcal_100g'}) ? 0 : $data->product->nutriments->{'energy-kcal_100g'}, "energy-kcal_serving" => is_null($data->product->nutriments->{'energy-kcal_serving'}) ? $data->product->nutriments->{'energy-kcal_100g'} : $data->product->nutriments->{'energy-kcal_serving'}, "carbohydrates_100g" => is_null($data->product->nutriments->carbohydrates_100g) ? 0 : $data->product->nutriments->carbohydrates_100g, "carbohydrates_serving" => is_null($data->product->nutriments->carbohydrates_serving) ? $data->product->nutriments->carbohydrates_100g : $data->product->nutriments->carbohydrates_serving, "sugars_100g" => is_null($data->product->nutriments->sugars_100g) ? 0 : $data->product->nutriments->sugars_100g, "sugars_serving" => is_null($data->product->nutriments->sugars_serving) ? $data->product->nutriments->sugars_100g : $data->product->nutriments->sugars_serving, "fat_100g" => is_null($data->product->nutriments->fat_100g) ? 0 : $data->product->nutriments->fat_100g, "fat_serving" => is_null($data->product->nutriments->fat_serving) ? $data->product->nutriments->fat_100g : $data->product->nutriments->fat_serving, "saturated-fat_100g" => is_null($data->product->nutriments->{'saturated-fat_100g'}) ? 0 : $data->product->nutriments->{'saturated-fat_100g'}, "saturated-fat_serving" => is_null($data->product->nutriments->{'saturated-fat_serving'}) ? $data->product->nutriments->{'saturated-fat_100g'} : $data->product->nutriments->{'saturated-fat_serving'}, "fruits_vegetables_100g" => is_null($data->product->nutriments->{'fruits-vegetables-nuts-estimate-from-ingredients_100g'}) ? 0 : $data->product->nutriments->{'fruits-vegetables-nuts-estimate-from-ingredients_100g'}, "fiber_100g" => (is_null($data->product->nutriments->fiber_100g) || $data->product->nutriments->fiber_100g == "") ? 0 : $data->product->nutriments->fiber_100g, "fiber_serving" => (is_null($data->product->nutriments->fiber_serving) || $data->product->nutriments->fiber_serving == "") ? 0 : $data->product->nutriments->fiber_serving, "proteins_100g" => is_null($data->product->nutriments->proteins_100g) ? 0 : $data->product->nutriments->proteins_100g, "proteins_serving" => is_null($data->product->nutriments->proteins_serving) ? $data->product->nutriments->proteins_100g : $data->product->nutriments->proteins_serving, "salt_100g" => is_null($data->product->nutriments->salt_100g) ? 0 : $data->product->nutriments->salt_100g, "salt_serving" => is_null($data->product->nutriments->salt_serving) ? $data->product->nutriments->salt_100g : $data->product->nutriments->salt_serving, "sodium_100g" => is_null($data->product->nutriments->sodium_100g) ? 0 : $data->product->nutriments->sodium_100g, "sodium_serving" => is_null($data->product->nutriments->sodium_serving) ? $data->product->nutriments->sodium_100g : $data->product->nutriments->sodium_serving, "calcium_100g" => (is_null($data->product->nutriments->calcium_100g) || $data->product->nutriments->calcium_100g == "") ? 0 : $data->product->nutriments->calcium_100g, "calcium_serving" => is_null($data->product->nutriments->calcium_serving) ? 0 : $data->product->nutriments->calcium_serving, "nutri_score" => is_null($data->product->nutriscore_data->score) ? 0 : $data->product->nutriscore_data->score, "nutri_grade" => is_null($data->product->nutriscore_data->grade) ? "Undefined" : $data->product->nutriscore_data->grade, "co2_total" => is_null($data->product->ecoscore_data->agribalyse->co2_total) ? 1 : $data->product->ecoscore_data->agribalyse->co2_total, "ef_total" => is_null($data->product->ecoscore_data->agribalyse->ef_total) ? 0.25 : $data->product->ecoscore_data->agribalyse->ef_total ); // Print the recent query in JSON with the requested values: echo(json_encode($query)); } }
⭐ If the barcode parameter is set, make a GET request to the Open Food Facts JSON API and print the food product information in JSON:

Step 1.1: Setting up the web application on Raspberry Pi
After creating the PHP web application, I decided to run it on my Raspberry Pi, but you can run the application on any server as long as it is a PHP server.
If you want to use Raspberry Pi but do not know how to set up a LAMP web server on Raspberry Pi, you can inspect this tutorial.
⭐ First of all, extract the Barcode_Product_Scanner.zip folder.
⭐ Then, move the application folder (Barcode_Product_Scanner) to the apache server (/var/www/html) by using the terminal since the apache server is a protected location.
sudo mv /home/pi/Downloads/Barcode_Product_Scanner /var/www/html/
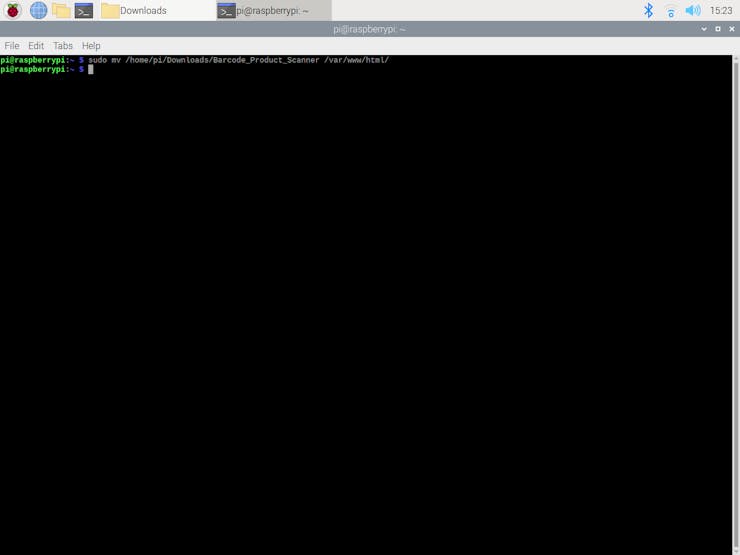
⭐ The web application prints nothing if the barcode parameter is not set nor found in the Open Food Facts database.
http://localhost/Barcode_Product_Scanner/
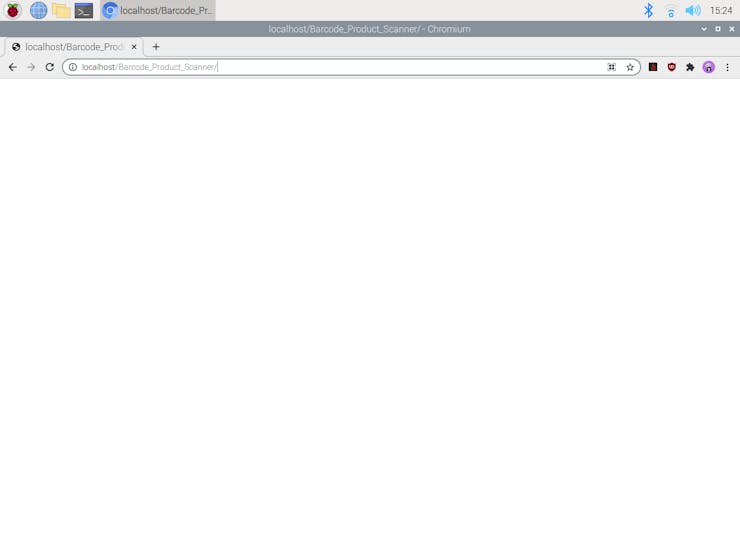
⭐ Otherwise, the web application prints the requested information of the given product barcode in JSON.
Barcode: 5053990101597 (EAN / EAN-13)
http://localhost/Barcode_Product_Scanner/?barcode=5053990101597
Step 2: Creating the nutrient profiling data set w/ nutrition facts and nutrient levels
To train my neural network model to make predictions on the healthiness class of a food product, I needed a data set of various products worldwide with eminent validity. However, as to why I created this project, most products do not have ample information, such as Nutri-Score values, to train a model. So, I handpicked some products providing the data I need for training my model to create a data set.
I selected products in different categories from Open Food Facts - in total, 2210 products - and saved their barcodes in the product_barcode_list.py file as the product_barcode_list array.


After creating the list of product barcodes with sufficient information, I developed a Python program (create_product_database.py) to get product characteristics for each product from the Open Food Facts JSON API via the PHP web application - explained in previous steps - in order to create the data set as a CSV file.
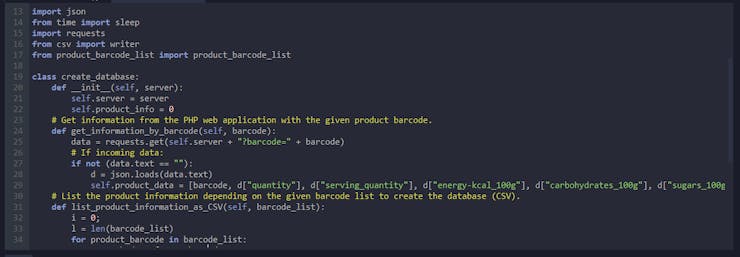
⭐ Define the create_database class and its functions.
⭐ In the get_information_by_barcode function, fetch information from the PHP web application with the given product barcode.
⭐ If there is incoming data in JSON (json.loads), get the required parameters to create the data set:
- barcode
- quantity
- serving_quantity
- energy-kcal_100g
- carbohydrates_100g
- sugars_100g
- fat_100g
- saturated-fat_100g
- fruits_vegetables_100g
- fiber_100g
- proteins_100g
- salt_100g
- sodium_100g
- calcium_100g
- nutri_score
- nutri_grade
- co2_total
- ef_total
class create_database: def __init__(self, server): self.server = server self.product_info = 0 # Get information from the PHP web application with the given product barcode. def get_information_by_barcode(self, barcode): data = requests.get(self.server + "?barcode=" + barcode) # If incoming data: if not (data.text == ""): d = json.loads(data.text) self.product_data = [barcode, d["quantity"], d["serving_quantity"], d["energy-kcal_100g"], d["carbohydrates_100g"], d["sugars_100g"], d["fat_100g"], d["saturated-fat_100g"], d["fruits_vegetables_100g"], d["fiber_100g"], d["proteins_100g"], d["salt_100g"], d["sodium_100g"], d["calcium_100g"], d["nutri_score"], d["nutri_grade"], d["co2_total"], d["ef_total"]]...
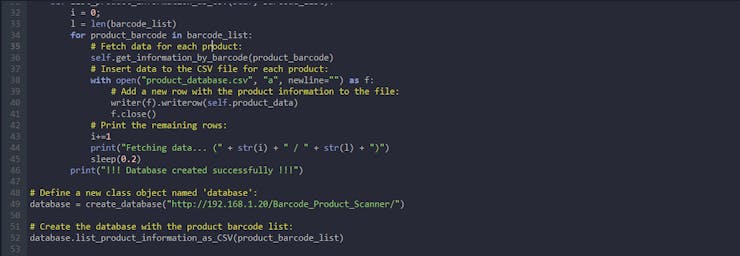
⭐ In the list_product_information_as_CSV function, fetch the required parameters for each product in the product_barcode_list array and insert them as a new row to the CSV file (product_database.csv) to create the data set.
... # List the product information depending on the given barcode list to create the database (CSV). def list_product_information_as_CSV(self, barcode_list): i = 0; l = len(barcode_list) for product_barcode in barcode_list: # Fetch data for each product: self.get_information_by_barcode(product_barcode) # Insert data to the CSV file for each product: with open("product_database.csv", "a", newline="") as f: # Add a new row with the product information to the file: writer(f).writerow(self.product_data) f.close() # Print the remaining rows: i+=1 print("Fetching data... (" + str(i) + " / " + str(l) + ")") sleep(0.2) print("!!! Database created successfully !!!")...
⭐ Rows after inserted into the CSV file:
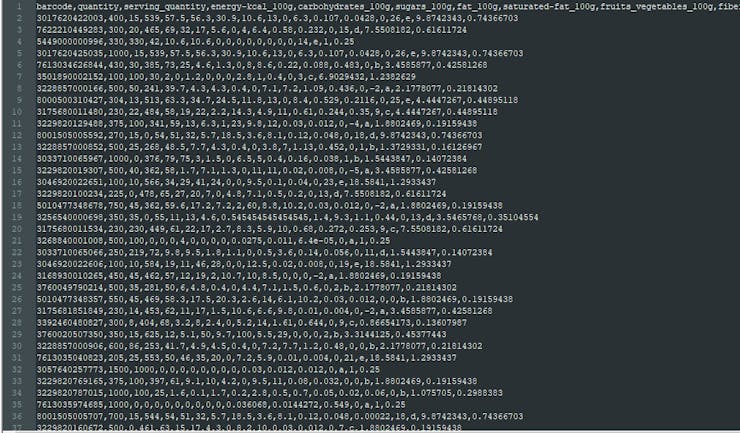
- 3175680011534, 230, 230, 449, 61, 22, 17, 2.7, 8.3, 5.9, 10, 0.68, 0.272, 0.253, 9, c, 7.5508182, 0.61611724
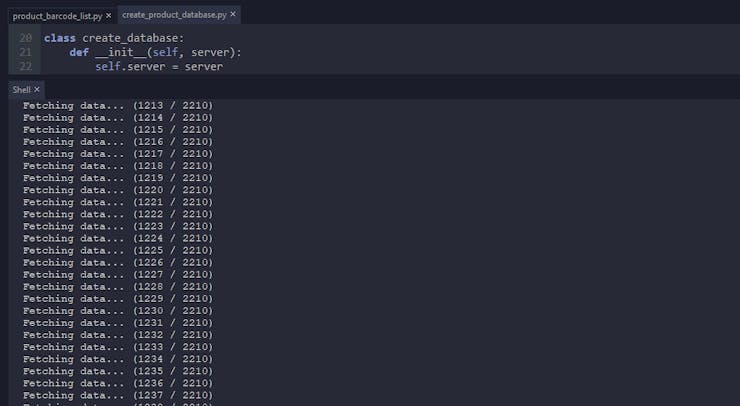
⭐ While adding a new row for each product to the CSV file to create the data set, the program shows the data obtaining progress. Also, it notifies when all information is inserted into the data set.

⭐ After running the program, the data set (product_database.csv) should look like this:
Step 3: Improving the Nutri-Score (nutritional rating system) algorithm
While creating the data set, I elicited Nutri-Score values for each product in the list to train my neural network model according to Nutri-Score labels. However, the original Nutri-Score scientific algorithm works with limited parameters to avoid or not avoid. Thus, I decided to improve the original algorithm by updating preceding Nutri-Score values for each product with extra parameters.
The Nutri-Score is a nutrition label that converts the nutritional value of food products into a simple code consisting of 5 letters, each with its color[2]:

The Nutri-Score scientific algorithm provides a single score for any given food product, based on calculating the number of points for negative nutrients that can be offset by points for positive nutrients. Points are allocated based on the nutritional content in 100 g of a food product.
For each negative ingredients, a maximum of 10 points can be awarded:
- energy,
- saturated fat,
- sugar,
- sodium.
Total negative points = [points for energy] + [points for saturated fat] + [points for sugars] + [points for sodium].
For each positive ingredients, a maximum of 5 points can be awarded:
- fruit, vegetables, and nuts,
- fiber,
- protein.
Total positive points = [points for fruit, vegetables, and nut content] + [points for fiber] + [points for protein].
The overall Nutri-Score is calculated as follows:
Overall score = [total negative points] - [total positive points].
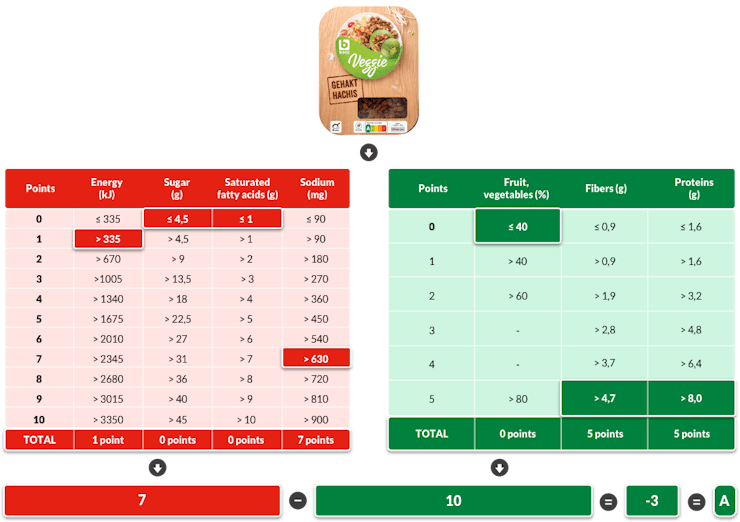
After calculating the overall score, a color-coded label (class) - A, B, C, D, E - is assigned for the evaluated product.
#️⃣ To improve the original Nutri-Score scientific algorithm, I added two negative parameters and one positive parameter to alter preceding Nutri-Score values for each product in my data set:
- calcium (positive),
- carbon footprint (negative),
- ecological footprint (negative).
#️⃣ I added calcium as a positive parameter since our body needs calcium to build and maintain strong bones. Also, some studies suggest that calcium, along with vitamin D, may have benefits beyond bone health: perhaps protecting against cancer, diabetes, and high blood pressure.
#️⃣ If calcium is higher than 110 mg per 100 g of a food product:
#️⃣ Nutri-Score = Nutri-Score - 1
#️⃣ If calcium is higher than 300 mg per 100 g of a food product:
#️⃣ Nutri-Score = Nutri-Score - 2

#️⃣ Estimating the overall health and benefit of a food product cannot be separated from its environmental impact while manufacturing processes. Therefore, I added carbon footprint (CO2) and ecological footprint (EF) values as negative parameters.
#️⃣ A food product's carbon footprint, or foodprint, is the greenhouse gas emissions produced by growing, rearing, farming, processing, transporting, storing, cooking, and disposing of it.
#️⃣ If the estimated carbon footprint is between 1 and 3 for a food product:
#️⃣ Nutri-Score = Nutri-Score + 1
#️⃣ If the estimated carbon footprint is between 3 and 5 for a food product:
#️⃣ Nutri-Score = Nutri-Score + 2
#️⃣ If the estimated carbon footprint is higher than 5 for a food product:
#️⃣ Nutri-Score = Nutri-Score + 3
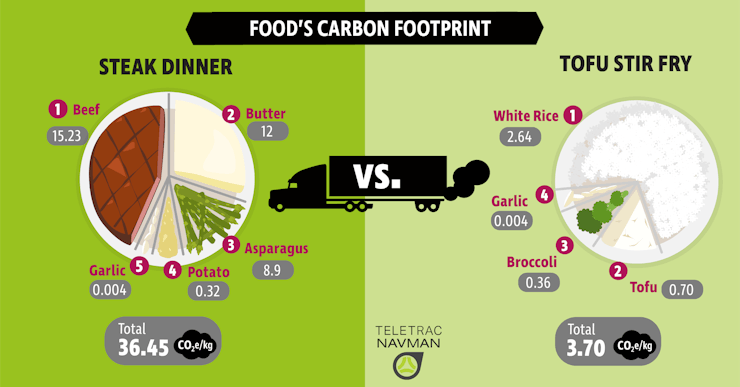
#️⃣ The ecological footprint measures the ecological assets that a given population or product requires to produce the natural resources it consumes (including plant-based food and fiber products, livestock and fish products, timber and other forest products, space for urban infrastructure) and absorb its waste, especially carbon emissions.
#️⃣ If the estimated ecological footprint is between 0.2 and 0.4 for a food product:
#️⃣ Nutri-Score = Nutri-Score + 1
#️⃣ If the estimated ecological footprint is between 0.4 and 0.9 for a food product:
#️⃣ Nutri-Score = Nutri-Score + 2
#️⃣ If the estimated ecological footprint is higher than 0.9 for a food product:
#️⃣ Nutri-Score = Nutri-Score + 3

#️⃣ After applying my improved algorithm to preceding Nutri-Score values, I assigned healthiness classes as labels for each product in my data set before training my neural network model.
- <= 3 ➡ Nutritious
- 3 to 11 ➡ Healthy
- 11 to 21 ➡ Less Healthy
- > 21 ➡ Unhealthy
Step 4: Building an Artificial Neural Network (ANN) with TensorFlow
When I completed collating my handpicked nutrient profiling data set and improving the Nutri-Score scientific algorithm, I started to work on my artificial neural network (ANN) model to make predictions on the healthiness class of a given food product.
I decided to create my neural network model with TensorFlow in Python. So, first of all, I followed the steps below to grasp a better understanding of my data set:
- Data Visualization
- Data Scaling (Normalizing)
- Data Preprocessing
- Data Splitting
As explained in the previous step, I applied my improved Nutri-Score algorithm with extra parameters to determine and assign healthiness classes for each food product in my data set depending on their nutrient profiling.
The following healthiness classes (labels) are used to classify the health and benefit of food products by their improved Nutri-Score ratings according to my algorithm:
- Nutritious — when the estimated Nutri-Score value is smaller than 3
- Healthy — when the estimated Nutri-Score value is between 3 and 11
- Less Healthy — when the estimated Nutri-Score value is between 11 and 21
- Unhealthy — when the estimated Nutri-Score value is greater than 21
Then, I preprocessed my nutrient profiling data set to assign one of these four classes for each food product in the data set (input) as its label:
- 0 (Nutritious)
- 1 (Healthy)
- 2 (Less Healthy)
- 3 (Unhealthy)
After scaling (normalizing) and preprocessing my nutrient profiling data set, I elicited nine input variables and one label for each food product, classified with the four mentioned classes. Then, I built an artificial neural network model with TensorFlow and trained it with my data set to obtain the best possible results and predictions.
Layers:
- 9 [Input]
- 256 [Hidden]
- 512 [Hidden]
- 1024 [Hidden]
- 2048 [Hidden]
- 4 [Output]

To execute all steps above, I created a class named Nutrient_Profiling in Python after including the required libraries:
import tensorflow as tffrom tensorflow import kerasimport matplotlib.pyplot as pltimport numpy as npimport pandas as pd
Subsequently, I will discuss coding in Python for each step I mentioned above.
Also, you can download build_neural_network_model.py to inspect coding.
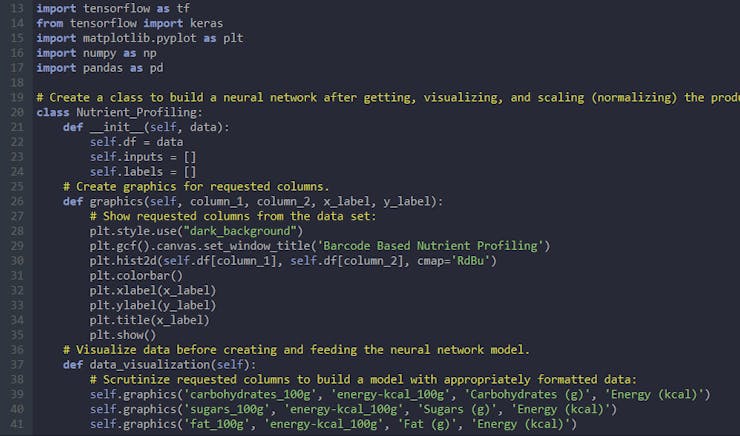
Step 4.1: Visualizing the nutrient profiling data set
Before diving into building a model, it is crucial to understand the data set to pass the model appropriately formatted data.
So, in this step, I will show you how to visualize the nutrient profiling data set and scale (normalize) it in Python.
⭐ First of all, read the nutrient profiling data set from product_database.csv.
csv_path = "E:\PYTHON\Barcode_Based_Nutrient_Profiling\product_database.csv"df = pd.read_csv(csv_path)
⭐ In the graphics function, visualize the requested columns from the nutrient profiling data set by using the Matplotlib library.
def graphics(self, column_1, column_2, x_label, y_label): # Show requested columns from the data set: plt.style.use("dark_background") plt.gcf().canvas.set_window_title('Barcode Based Nutrient Profiling') plt.hist2d(self.df[column_1], self.df[column_2], cmap='RdBu') plt.colorbar() plt.xlabel(x_label) plt.ylabel(y_label) plt.title(x_label) plt.show()
⭐ In the data_visualization function, scrutinize all columns before scaling and preprocessing nutrient profiling data to build a model with appropriately formatted data.
def data_visualization(self): # Scrutinize requested columns to build a model with appropriately formatted data: self.graphics('carbohydrates_100g', 'energy-kcal_100g', 'Carbohydrates (g)', 'Energy (kcal)') self.graphics('sugars_100g', 'energy-kcal_100g', 'Sugars (g)', 'Energy (kcal)') self.graphics('fat_100g', 'energy-kcal_100g', 'Fat (g)', 'Energy (kcal)') self.graphics('saturated-fat_100g', 'energy-kcal_100g', 'Saturated fat (g)', 'Energy (kcal)') self.graphics('fruits_vegetables_100g', 'energy-kcal_100g', 'Fruits vegetables nuts estimate (%)', 'Energy (kcal)') self.graphics('fiber_100g', 'energy-kcal_100g', 'Fiber (g)', 'Energy (kcal)') self.graphics('proteins_100g', 'energy-kcal_100g', 'Proteins (g)', 'Energy (kcal)') self.graphics('salt_100g', 'energy-kcal_100g', 'Salt (g)', 'Energy (kcal)') self.graphics('sodium_100g', 'energy-kcal_100g', 'Sodium (g)', 'Energy (kcal)')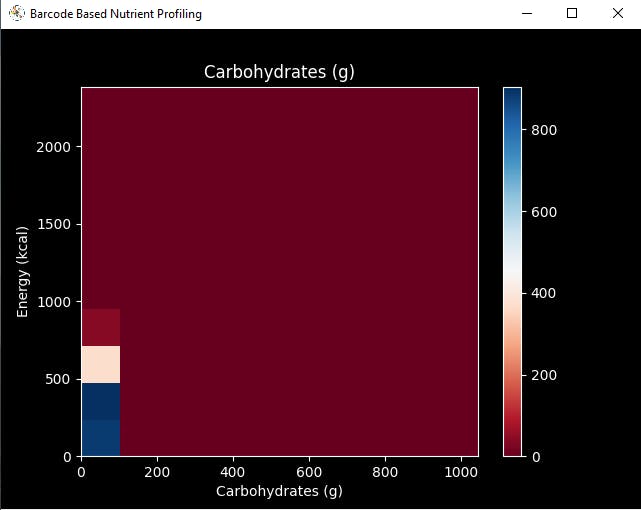
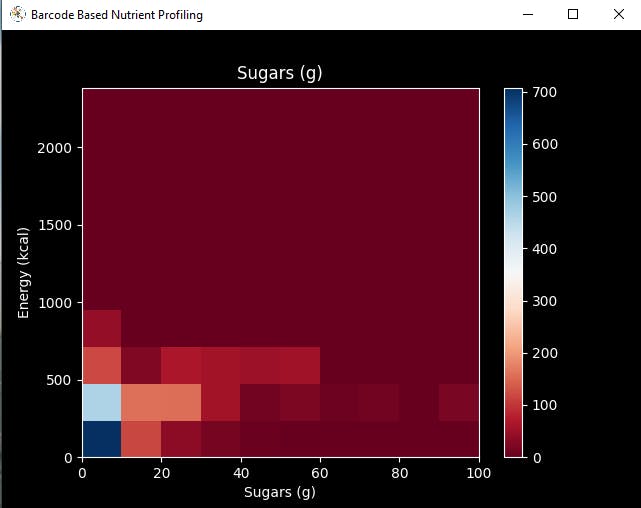

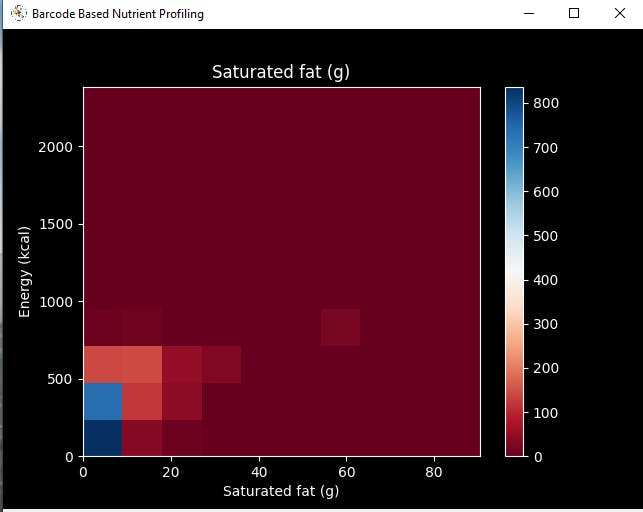
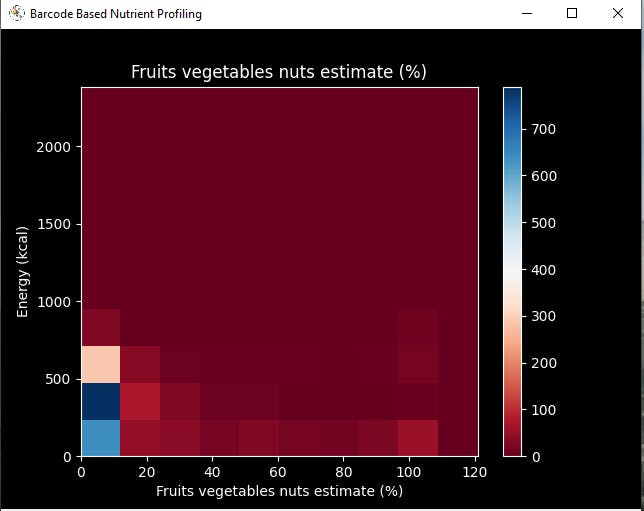

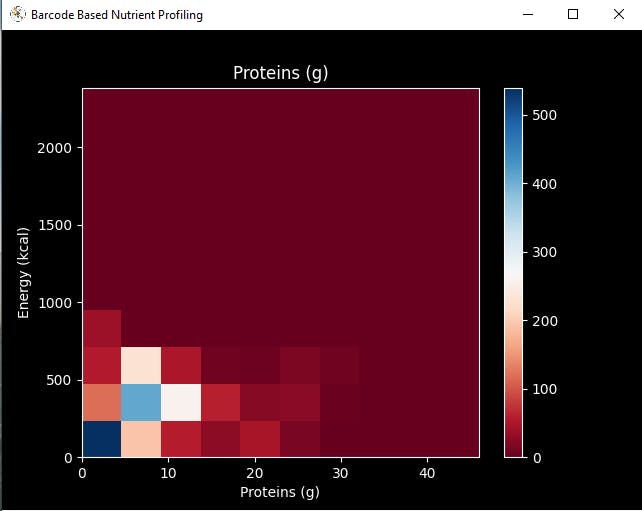


Step 4.2: Assigning labels (healthiness classes based on Nutri-Score) and scaling (normalizing) the input data
Before building and training my neural network model, I preprocessed the nutrient profiling data set to apply my improved Nutri-Score algorithm in order to assign labels (healthiness classes) for each food product as explained in the previous step.
From the data set for each food product, I used these parameters to apply the improved algorithm and assign classes:
- nutri_score
- calcium_100g
- co2_total
- ef_total
⭐ In the define_and_assign_labels function, evaluate the altered Nutri-Score values according to the improved algorithm for each food product in the data set as shown in Step 3.
⭐ Then, assign healthiness classes (labels) [0 - 3] for each product depending on their altered Nutri-Score values, append them to the labels array, and convert this array to a NumPy array by using the asarray() function.
def define_and_assign_labels(self): l = len(self.df) for i in range(l): # Calculate the Nutri-Score value (altered). nutri_score = df["nutri_score"][i] calcium = df["calcium_100g"][i] * 1000 co2 = df["co2_total"][i] ef = df["ef_total"][i] # Calcium: if(calcium > 110): nutri_score-=1 elif(calcium > 300): nutri_score-=2 # CO2 (Environmental impact): if(co2 > 1 and co2 <= 3): nutri_score+=1 elif(co2 > 3 and co2 <= 5): nutri_score+=2 elif(co2 > 5): nutri_score+=3 # EF (Ecological footprint): if(ef > 0.2 and ef <= 0.4): nutri_score+=1 elif(ef > 0.4 and ef <= 0.9): nutri_score+=2 elif(ef > 0.9): nutri_score+=3 # Assign classes (labels) depending on the Nutri-Score value: _class = 0 if(nutri_score <= 3): _class = 0 elif(nutri_score > 3 and nutri_score <= 11): _class = 1 elif(nutri_score > 11 and nutri_score <= 21): _class = 2 elif(nutri_score > 21): _class = 3 self.labels.append(_class) self.labels = np.asarray(self.labels)
After assigning labels, I needed to create inputs to train my neural network model. From the data set for each food product, I decided to use these nine parameters to create inputs since they are essential and presented for nearly every product in the Open Food Facts database:
- energy-kcal_100g
- carbohydrates_100g
- sugars_100g
- fat_100g
- saturated-fat_100g
- fiber_100g
- proteins_100g
- salt_100g
- sodium_100g
After selecting nine parameters for inputs and visualizing the data set, I scaled (normalized) each parameter column to format them properly.
Normally, each input for a food product in the data set looked like this before scaling:
- 449, 61, 22, 17, 2.7, 5.9, 10, 0.68, 0.272
After completing scaling (normalizing), I extracted these scaled parameter columns from the nutrient profiling data set for each food product:
- scaled_energy
- scaled_carbohydrates
- scaled_sugars
- scaled_fat
- scaled_saturated
- scaled_fiber
- scaled_proteins
- scaled_salt
- scaled_sodium
Input with the scaled parameters:
- [0.449 0.61 0.22 0.17 0.027 0.59 0.1 0.068 0.0272]
⭐ In the scale_data_and_define_inputs function, divide every parameter column into their required values to make them smaller than 1.
⭐ Then, create inputs for each food product with the scaled parameters, append them to the inputs array, and convert this array to a NumPy array by using the asarray() function.
⭐ Each input includes nine parameters [shape=(9, )]:
- [scaled_energy, scaled_carbohydrates, scaled_sugars, scaled_fat, scaled_saturated, scaled_fiber, scaled_proteins, scaled_salt, scaled_sodium]
def scale_data_and_define_inputs(self): self.df["scaled_energy"] = self.df.pop("energy-kcal_100g") / 1000 self.df["scaled_carbohydrates"] = self.df.pop("carbohydrates_100g") / 100 self.df["scaled_sugars"] = self.df.pop("sugars_100g") / 100 self.df["scaled_fat"] = self.df.pop("fat_100g") / 100 self.df["scaled_saturated"] = self.df.pop("saturated-fat_100g") / 100 self.df["scaled_fiber"] = self.df.pop("fiber_100g") / 10 self.df["scaled_proteins"] = self.df.pop("proteins_100g") / 100 self.df["scaled_salt"] = self.df.pop("salt_100g") / 10 self.df["scaled_sodium"] = self.df.pop("sodium_100g") / 10 # Create the inputs array using the scaled variables: for i in range(len(self.df)): self.inputs.append(np.array([self.df["scaled_energy"][i], self.df["scaled_carbohydrates"][i], self.df["scaled_sugars"][i], self.df["scaled_fat"][i], self.df["scaled_saturated"][i], self.df["scaled_fiber"][i], self.df["scaled_proteins"][i], self.df["scaled_salt"][i], self.df["scaled_sodium"][i]])) self.inputs = np.asarray(self.inputs)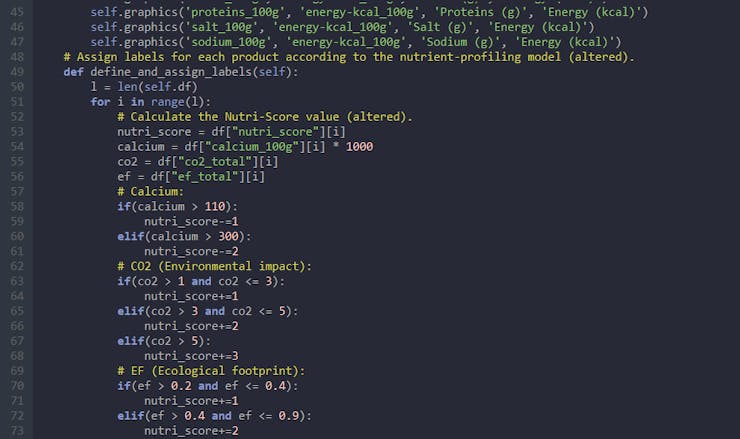
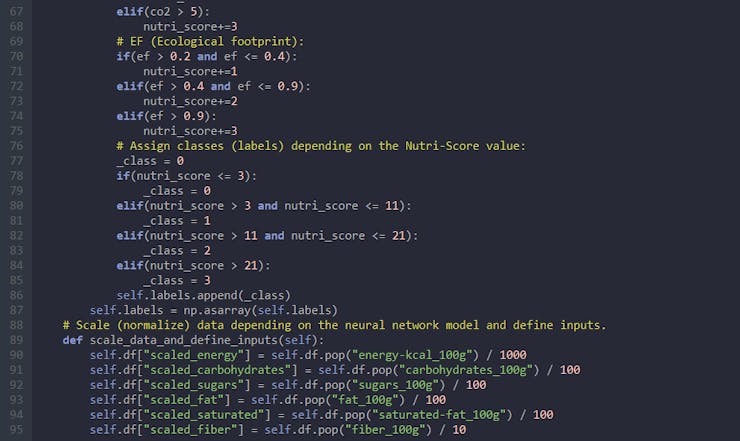
Step 4.3: Training the model (ANN) on the healthiness classes based on Nutri-Score
After preprocessing and scaling (normalizing) the nutrient profiling data set to create inputs and labels, I split them as training (90%) and test (10%) sets:
def split_data(self): l = len(self.df) # (90%, 10%) - (training, test) self.train_inputs = self.inputs[0:int(l*0.9)] self.test_inputs = self.inputs[int(l*0.9):] self.train_labels = self.labels[0:int(l*0.9)] self.test_labels = self.labels[int(l*0.9):]
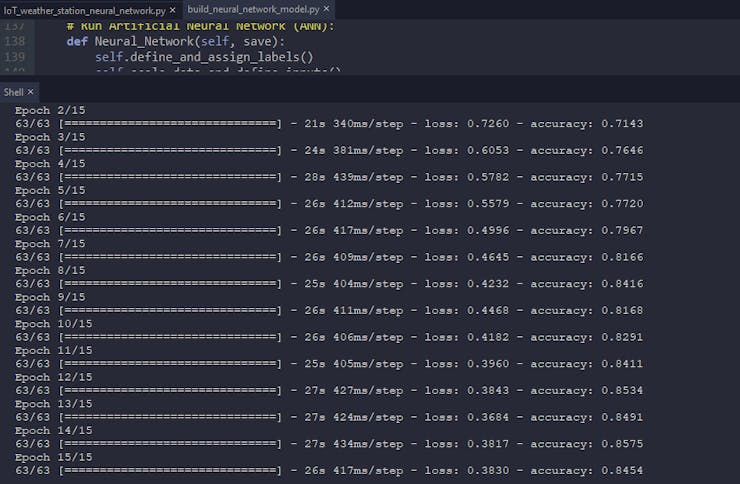
Then, I built my artificial neural network (ANN) model by using Keras and trained it with the training set for fifteen epochs.
You can inspect these tutorials to learn about activation functions, loss functions, epochs, etc.
def build_and_train_model(self): # Build the neural network: self.model = keras.Sequential([ keras.Input(shape=(9,)), keras.layers.Dense(256, activation='relu'), keras.layers.Dense(512, activation='relu'), keras.layers.Dense(1024, activation='relu'), keras.layers.Dense(2048, activation='relu'), keras.layers.Dense(4, activation='softmax') ]) # Compile: self.model.compile(optimizer='adam', loss="sparse_categorical_crossentropy", metrics=['accuracy']) # Train: self.model.fit(self.train_inputs, self.train_labels, epochs=15) ...

After training with the training set (inputs and labels), the accuracy of my neural network model is between 0.85 and 0.87.
Step 4.4: Evaluating the model and converting it to a TensorFlow Lite model (.tflite)
After building and training my artificial neural network model, I tested its accuracy and validity by utilizing the testing set (inputs and labels).
The evaluated accuracy of the model is 0.8552.
... # Test the accuracy: print("\n\nModel Evaluation:") test_loss, test_acc = self.model.evaluate(self.test_inputs, self.test_labels) print("Evaluated Accuracy: ", test_acc)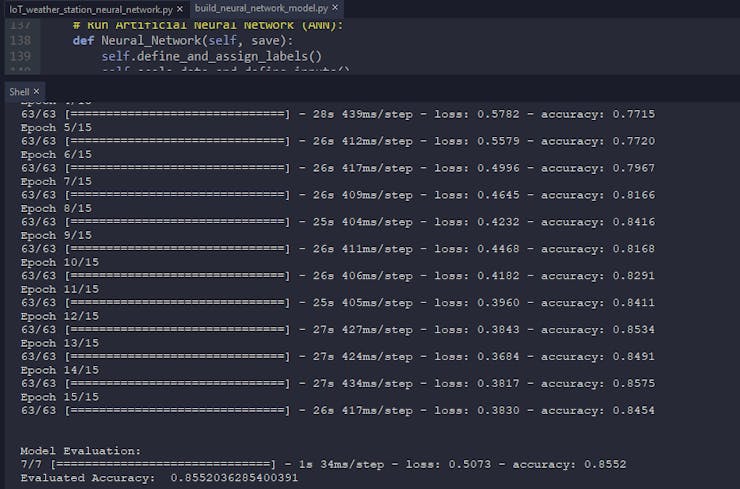
After evaluating my neural network model, I saved it as a TensorFlow Keras H5 model (ANN_Nutrient_Profiling.h5).
... def save_model(self): self.model.save("E:\PYTHON\Barcode_Based_Nutrient_Profiling\ANN_Nutrient_Profiling.h5")
However, running a TensorFlow Keras H5 model on Raspberry Pi to make predictions is not eligible and efficient considering size, latency, and power consumption.
Thus, I converted my neural network model from a TensorFlow Keras H5 model (.h5) to a TensorFlow Lite model (.tflite) to run it on Raspberry Pi.
⭐ In the convert_TF_model function, load the saved model (tf.keras.models.load_model) and convert it to a TensorFlow Lite model by using the TensorFlow Lite converter (tf.lite.TFLiteConverter.from_keras_model).
⭐ Then, save the converted TensorFlow Lite model (ANN_Nutrient_Profiling.tflite).
def convert_TF_model(self, path): model = tf.keras.models.load_model(path + ".h5") converter = tf.lite.TFLiteConverter.from_keras_model(model) tflite_model = converter.convert() # Save the TensorFlow Lite model. with open(path + '.tflite', 'wb') as f: f.write(tflite_model) print("\r\nTensorFlow Keras H5 model converted to a TensorFlow Lite model...\r\n")
Step 5: Installing TensorFlow on Raspberry Pi
After converting my neural network model to a TensorFlow Lite model, I installed TensorFlow on my Raspberry Pi 4 to run it.
By following the instructions below, it is effortless to install TensorFlow on Raspberry Pi.
⭐ Open a Terminal window and enter:
sudo apt install libatlas-base-dev
pip3 install tensorflow
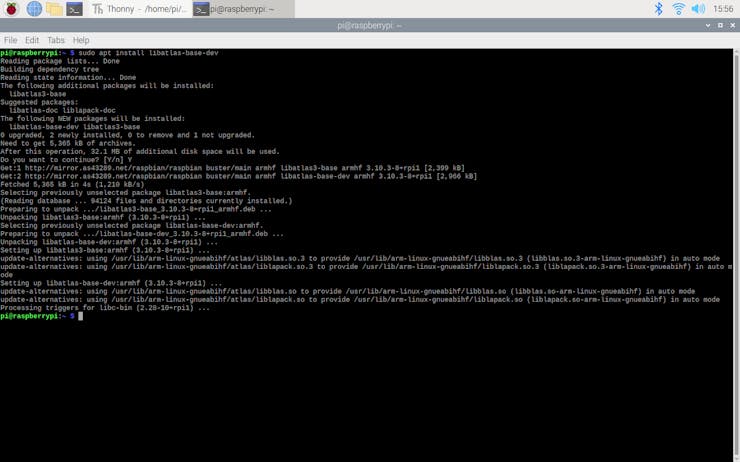
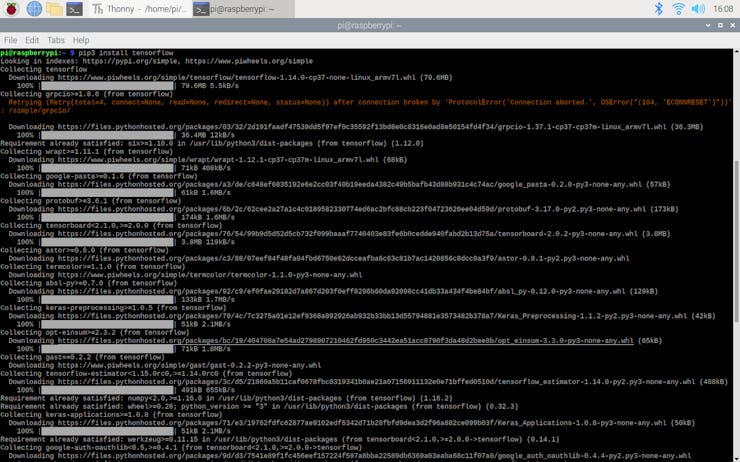
With this method, the version of TensorFlow installed is the pre-built 1.14. If you try to specify a higher version, the Raspberry Pi throws an error. But, do not worry: the 1.14 version is suitable and more than enough for running a TensorFlow Lite model on Raspberry Pi, so I utilized this version for running my model.
Nevertheless, if you want to install TensorFlow 2.x, there are three different ways:
- Build TensorFlow from official TensorFlow wheels
- Build TensorFlow from community-built wheels
- Build from the source code
Step 6: Getting product characteristics by barcodes and running the TensorFlow Lite model on Raspberry Pi to predict healthiness classes
Since I used food product barcodes to collect product characteristics from the Open Food Facts database with my PHP web application (Step 1), I decided to connect a barcode scanner to my Raspberry Pi to obtain barcodes easily to get information from the database to make predictions on the healthiness classes based on Nutri-Score with my neural network model (TensorFlow Lite).
Then, I developed a Python program (barcode_food_labelling_tf_lite.py) on Raspberry Pi to elicit information transferred by my PHP web application on a given product barcode and run my TensorFlow Lite model with that data.
⭐ First of all, save the Python program (barcode_food_labelling_tf_lite.py) and the TensorFlow Lite model (ANN_Nutrient_Profiling.tflite) under the same folder.
⭐ Define the barcode_food_labelling class and its functions.
⭐ In the __init__ function, define class names for each healthiness class based on improved Nutri-Score (Step 4.2).
class barcode_food_labelling: def __init__(self, server): self.server = server self.product_data = 0 # Define class names for each Nutri-Score (food health category) classes based on nutrient profiling. self.nutri_score_class_names = ["Nutritious", "Healthy", "Less Healthy", "Unhealthy"]
⭐ In the get_information_by_barcode function, fetch information from the PHP web application with the given product barcode.
⭐ If there is incoming data in JSON (json.loads), get the required parameters and return true.
⭐ Otherwise, return false.
def get_information_by_barcode(self, barcode): data = requests.get(self.server + "?barcode=" + barcode) # If incoming data: if not (data.text == ""): self.product_data = json.loads(data.text) return True else: print("\r\nBarcode Not Found!!!") return False
After obtaining information successfully for a given barcode from the PHP web application, I formatted its required parameters to make a prediction on its healthiness class, depending on how I scaled (normalized) them while training my neural network model (Step 4.3).
⭐ In the format_incoming_data function, if there is data in JSON (product_data), extract information of the given product barcode and format the required parameters to make a prediction:
- energy-kcal_100g
- carbohydrates_100g
- sugars_100g
- fat_100g
- saturated-fat_100g
- fiber_100g
- proteins_100g
- salt_100g
- sodium_100g
⭐ Also, get the short product description for the given product barcode:
- name (brand)
- type
- quantity
- serving_quantity
def format_incoming_data(self): if not(self.product_data == 0): # Information: self.name = self.product_data["name"] self.type = self.product_data["type"] self.quantity = str(self.product_data["quantity"]) + " / " + str(self.product_data["serving_quantity"]) # Data: self.energy = self.product_data["energy-kcal_100g"] / 1000 self.carbohydrates = self.product_data["carbohydrates_100g"] / 100 self.sugars = self.product_data["sugars_100g"] / 100 self.fat = self.product_data["fat_100g"] / 100 self.saturated = self.product_data["saturated-fat_100g"] / 100 self.fiber = self.product_data["fiber_100g"] / 10 self.proteins = self.product_data["proteins_100g"] / 100 self.salt = self.product_data["salt_100g"] / 10 self.sodium = self.product_data["sodium_100g"] / 10
Then, I created an input array consisting of the formatted parameters to make a prediction on the healthiness class (based on Nutri-Score) of the given product barcode with my neural network model (TensorFlow Lite).
The model predicts possibilities of labels (healthiness classes) for each input as an array of 4 numbers. They represent the model's "confidence" that the given input array corresponds to each of the four different healthiness classes based on Nutri-Score values [0 - 3], as shown in Step 4.
- 0 (Nutritious)
- 1 (Healthy)
- 2 (Less Healthy)
- 3 (Unhealthy)
⭐ In the run_TensorFlow_Lite_model function, to execute the TensorFlow Lite model (ANN_Nutrient_Profiling.tflite):
⭐ Load the model into memory.
⭐ Build an Interpreter (tf.lite.Interpreter) based on the existing model and allocate tensors.
⭐ Get input and output tensors' details.
⭐ Set the input tensor values with the formatted input data as a NumPy array by using the asarray() function.
⭐ Invoke inference (Run).
⭐ Read output tensor values.
⭐ Then, display the most accurate label (healthiness class) predicted by the model by using the argmax() function.
⭐ Finally, print the short product description and the prediction.
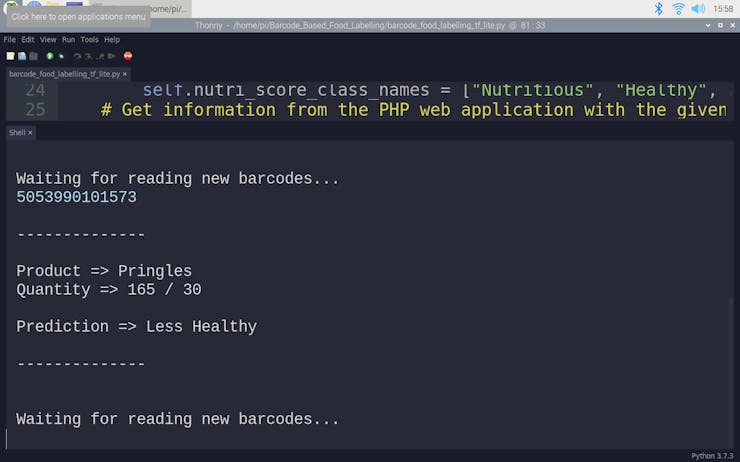
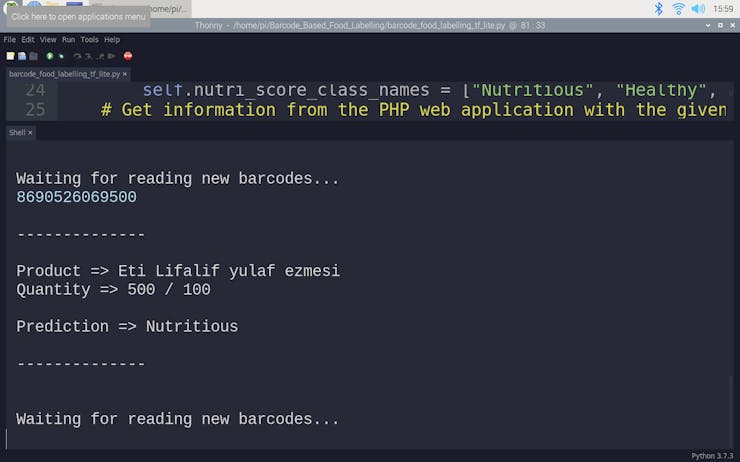
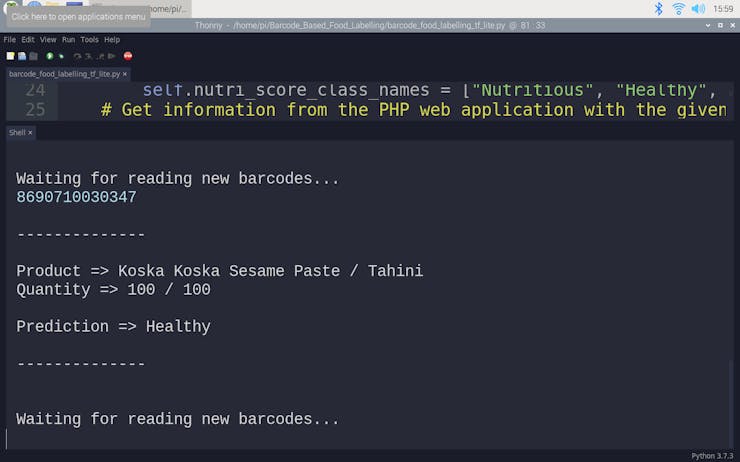
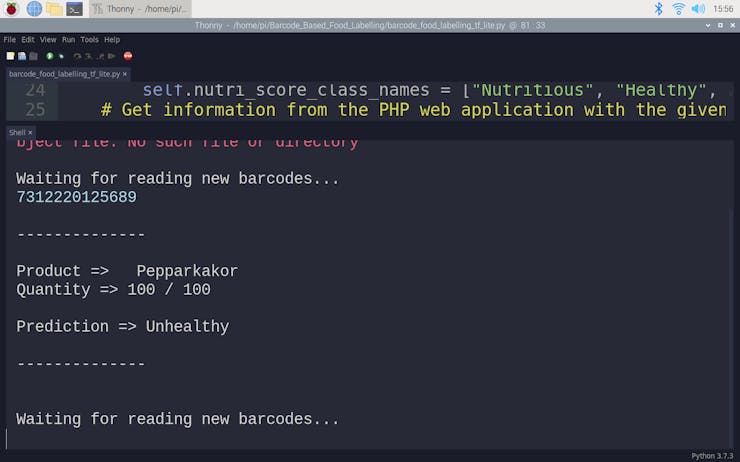
def run_TensorFlow_Lite_model(self, path): # Load the TFLite model and allocate tensors. interpreter = tf.lite.Interpreter(model_path=path) interpreter.allocate_tensors() # Get input and output tensors. input_details = interpreter.get_input_details() output_details = interpreter.get_output_details() # Run the model with the formatted input data: input_data = np.array([[self.energy, self.carbohydrates, self.sugars, self.fat, self.saturated, self.fiber, self.proteins, self.salt, self.sodium]], dtype=np.float32) interpreter.set_tensor(input_details[0]['index'], input_data) interpreter.invoke() # Get output data (label): output_data = interpreter.get_tensor(output_details[0]['index']) prediction = self.nutri_score_class_names[np.argmax(output_data)] print("\r\n--------------\r\n") print("Product => " + self.name + " " + self.type) print("Quantity => " + self.quantity) print() print("Prediction => " + prediction) print("\r\n--------------\r\n")
I used a GM65 barcode scanner module to scan barcodes of food products accurately. This module is a laser-based scanner and can be directly plugged into any computer (or microcomputer) through the onboard USB interface. It shows up as an HID keyboard, so when a barcode is scanned, the raw data is decoded, parity-checked, and spit out as if they were typed on a keyboard.
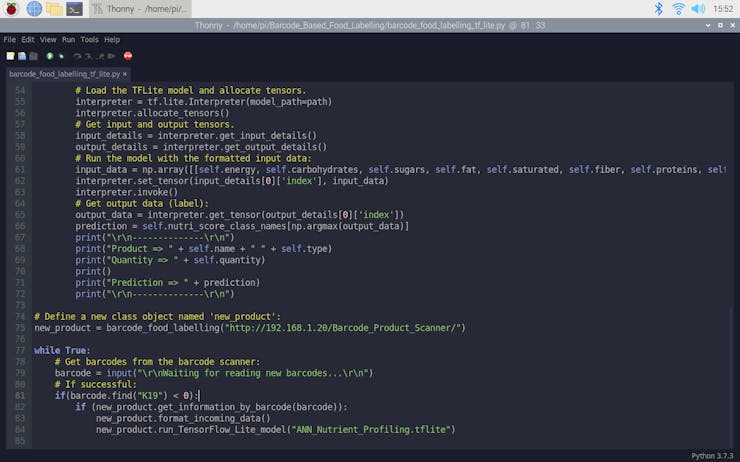
⭐ Use the input() function to detect the scanned barcode when the barcode scanner types it.
⭐ If the scanned barcode is accurate and the PHP web application returns product characteristics from the Open Food Facts database successfully, run the TensorFlow Lite model to make a prediction.
while True: # Get barcodes from the barcode scanner: barcode = input("\r\nWaiting for reading new barcodes...\r\n") # If successful: if(barcode.find("K19") < 0): if (new_product.get_information_by_barcode(barcode)): new_product.format_incoming_data() new_product.run_TensorFlow_Lite_model("ANN_Nutrient_Profiling.tflite")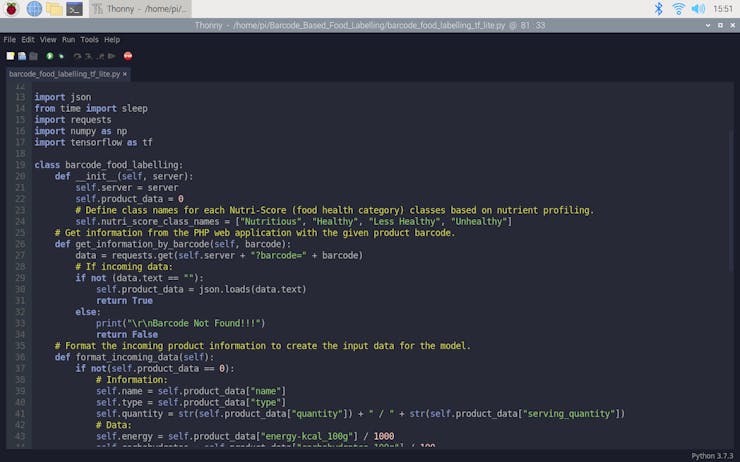
Step 6.1: Experimenting with the model by making predictions on varying food products
After setting up and running my TensorFlow Lite model on Raspberry Pi, I used my device to predict the healthiness classes of varying food products under different categories at my disposal. As far as my experiment goes, the model is working impeccably :)
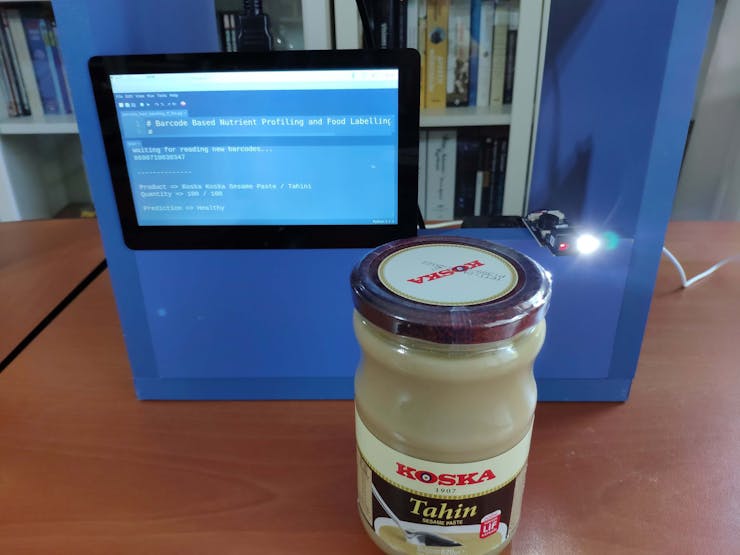
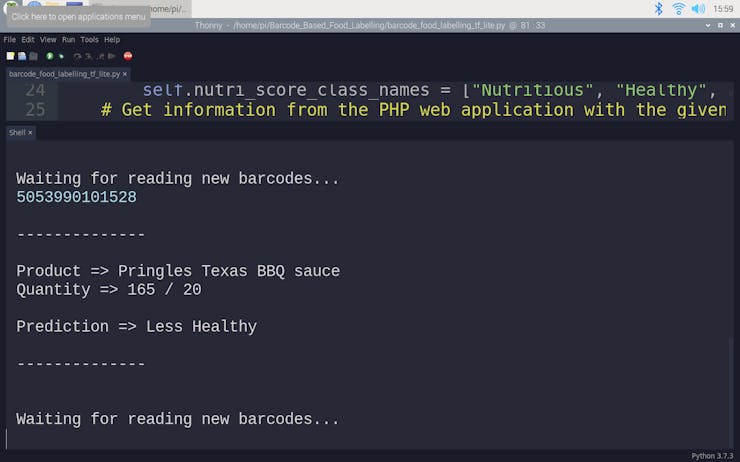
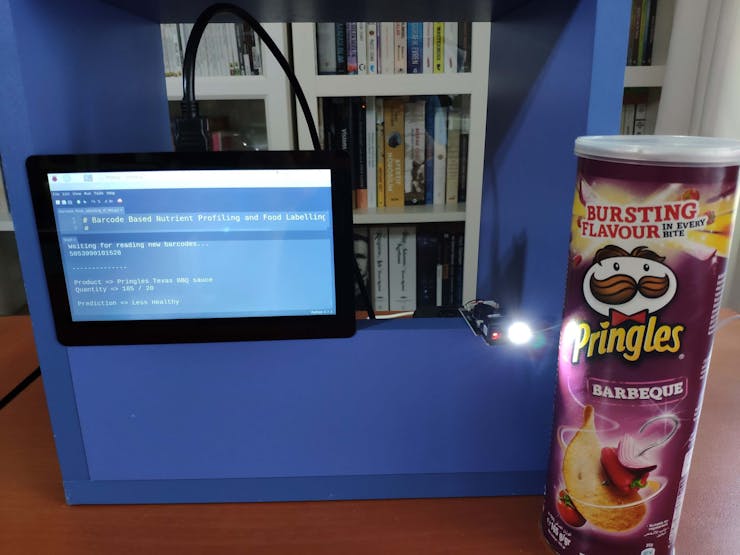
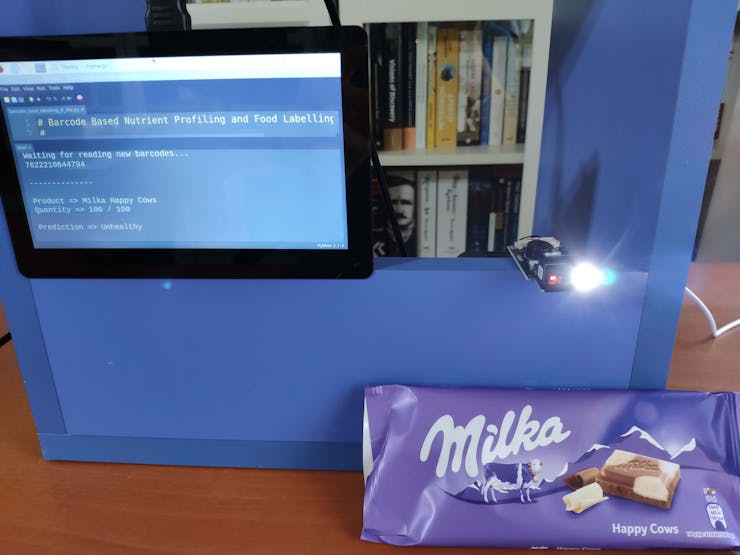
🍔🥗 While running, the device waits for the barcode scanner to scan a food product barcode.
🍔🥗 If the scanned product barcode is not found in the Open Food Facts database, the device prints: Barcode Not Found!!!.

🍔🥗 Otherwise, the device runs the TensorFlow Lite model to predict the healthiness class of the given food product and prints:
- product's brand name and type,
- product's quantity and serving quantity,
- model's prediction on product's healthiness class.
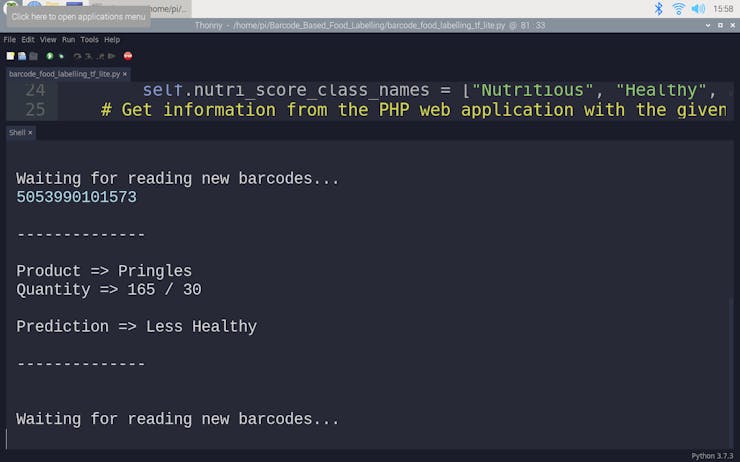
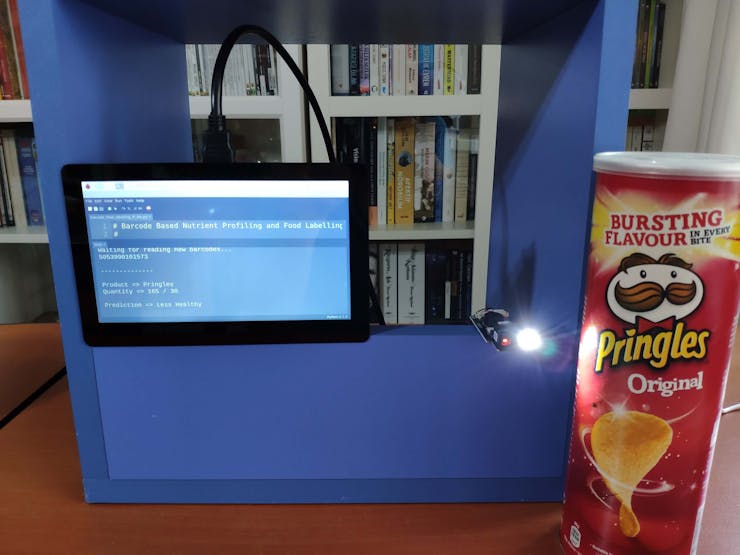
🍔🥗 Predictions on different food products for each healthiness class defined by the model:
- Nutritious
- Healthy
- Less Healthy
- Unhealthy
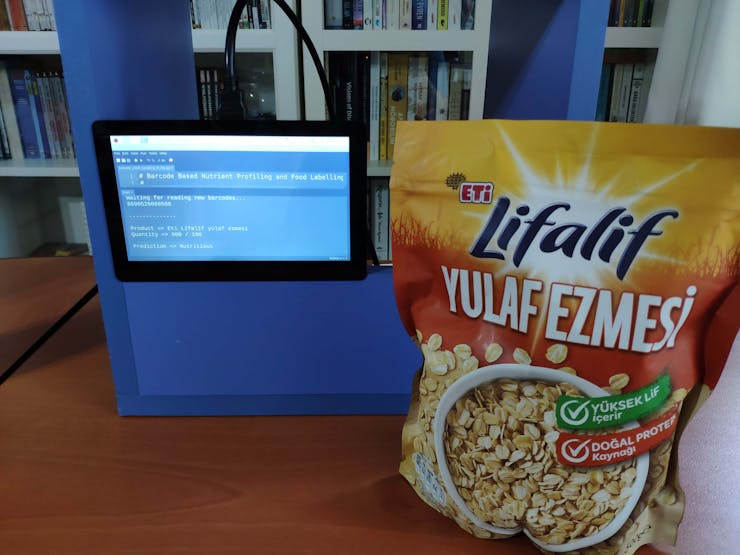


Connections and Adjustments
For this project, developing software and building the neural network model were the struggling tasks in comparison with connecting hardware.
Since the GM65 barcode scanner module is a laser-based scanner that shows up as an HID keyboard, I connected it directly to my Raspberry Pi via the USB port.

I used the DFRobot 7'' HDMI Display with Capacitive Touchscreen to show my neural network model's predictions on healthiness classes. Raspberry Pi Model 3 can be attached to the screen via standoffs, machine screws, and the integrated HDMI Adapter. However, if you want to use a Raspberry Pi Model 4 with the screen, as did I, you may need an HDMI to Micro HDMI Adapter.

Videos and Conclusion
After completing all steps above and experimenting, the device became a handy robot assistant to distinguish healthy and unhealthy foods by extrapolating healthiness classes from meager packaging information with my neural network model :)

Further Discussions
By bringing devices like this into general use, they can be utilized to:
🍔🥗 advice consumers with clear and consistent food ratings,
🍔🥗 encourage all manufacturers and retailers to create a unanimous approach to packaging,
🍔🥗 set standards for broadcast advertising and other forms of food advertising and promotion,
🍔🥗 check health claims to prevent misleading messages from manufacturers,
🍔🥗 regulate health policies and health impact assessment,
🍔🥗 assist evaluation of population dietary surveys and food consumption trends,
🍔🥗 create marketing opportunities for reformulated foods and healthier product lines.

References
[1]Public Health Nutrition: 12(3). "Defining and labelling ‘healthy’ and ‘unhealthy’ food". 29 May 2008. 331–340. doi:10.1017/S1368980008002541.
[2]Colruyt Group. "What is the Nutri-Score?