 lion mclionhead
lion mclionheadThere were attempts at using a bigger target than a face by trying other demos in opencv.
openpose.cpp ran at 1 frame every 30 seconds.
person-reid.cpp ran at 1.6fps. This requires prior detection of a person with openpose or YOLO. Then it tries to match it with a database.
object_detection.cpp ran at 1.8fps with the yolov4-tiny model from https://github.com/AlexeyAB/darknet#pre-trained-models This is a general purpose object detector.
There were promising results with a 64 bit version of pose tracking on the raspberry pi. Instead of using opencv, this used tensorflow lite. It tracks 1 animal at 8fps. The multi animal network goes at 3fps or 4fps with overclocking.
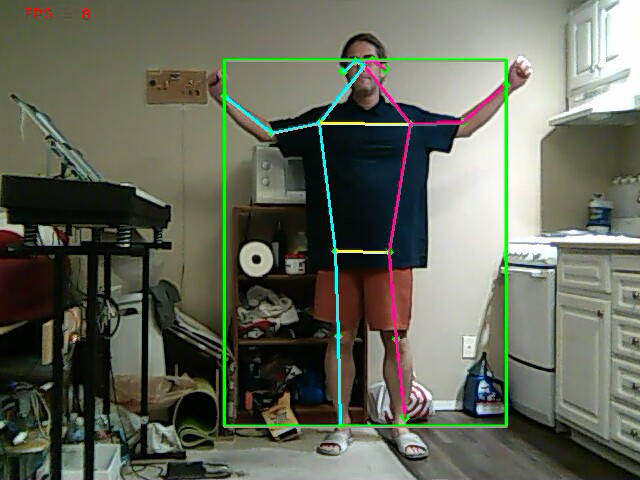
A 1 animal pose tracker would avoid tracking windows instead of lions & it would have an easier time in difficult lighting, but it would probably have the same problem of tracking the wrong animal in a crowd. It's not clear if it chooses what animal to track based on size, total number of visible body parts, or the score of each body part. It may just be a matter of fully implementing it & trying it in the city.
Maybe compiling opencv for aarch64 would speed up the face recognition because of wider vector instructions. There were some notes about compiling opencv for aarch64
https://github.com/huzz/OpenCV-aarch64
That didn't work. 1st,
-D ENABLE_VFVP3=ON
should be
-D ENABLE_VFPV3=ON
Helas, VFPV3 isn't supported on the raspberry pi 4 in 64 bit mode so this option needs to be completely left out. There's a lot of confusion between raspberry pi's in 32 bit & 64 bit mode.
The mane change is to download the latest HEAD of the 4.x branch so it compiles with Ubunt 21.
Helas, after recompiling opencv for 64 bit mode, the truckcam face tracker still ran at 8.5fps, roughly equivalent to the latest optimizations of the 32 bit version. Any speed improvement was from the tensorflow lite model instead of the instruction set.




There was an object tracker for tensorflow lite which sometimes worked.
https://github.com/tensorflow/examples/tree/master/lite/examples/object_detection/raspberry_pi
The advantage is it can detect multiple animals at a reasonable framerate, but it was terribly inaccurate.
This led to the idea of training a custom YOLO model on a subset of the data used to train other YOLO models. YOLO is trained using files from
https://cocodataset.org/#download
There are some train & val files which contain just images. There are other files which contain annotations. There was a useful video describing the files & formats on cocodataset.org.
Basically, all of today's pose tracking, face tracking, object tracking models are based on this one dataset. All the images are non copyrighted images from flickr. They've all been scaled to 640 in the longest dimension. All the images were annotated by gig economy workers manually outlining objects for a pittance.
They're all concentrated around the 2005-2010 time frame when flickr peaked & they're concentrated among just people who were technically literate enough to get online in those days. All of the machine vision models of the AI boom live entirely in that 1 point in time.
4:3 monitors, CRT's, flip phones, brick laptops, overweight confuser geeks, & Xena costumes abound.

There's a small number of photos from 2012 up to 2017. The increasing monetization options after 2010 probably limited the content.
To create an annotation file with a subset of the annotations in another annotation file, there's a script.
https://github.com/immersive-limit/coco-manager
For most of us, the usage would be:
python3 filter.py --input_json instances_train2017.json --output_json person.json --categories person
There are bits about training a YOLO V5 model & a link to a dropbox with a dataset on https://www.analyticsvidhya.com/blog/2021/12/how-to-use-yolo-v5-object-detection-algorithm-for-custom-object-detection-an-example-use-case/
There is so much bloatware, the virtual environment is definitely required. The command to enter the python virtual environment is
source YoloV5_VirEnv/bin/activate
Most people get an error when installing pytorch. It's not compatible with python 3.10 or other random versions of python. Try downloading & compiling python 3.9
./configure --prefix=/root/yolo/yolov5/YoloV5_VirEnv
Sadly, the instructions for training don't involve the JSON files from cocodataset. Instead, they specifiy a .yaml file with the paths of the images & a .txt file for each image. The .txt format for the annotations is a line for each object. Each line has a category index from the .yaml file & the bounding box of the object. There are no subcategories in YOLOV5, so it couldn't track keypoints inside a person. Obviously, the COCO dataset is intended for more than just YOLOV5. There would have to be a conversion from COCO to YOLO annotations.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.