 Flo
FloThe UltraBip is one of the market leading Hike&Fly (no display) varios with voice announcements, solar chaging and sensor fusion ('instant vario'). The audio files show some upcoming wind detection features as well.
Speech and vario tones are splitted to speaker and piezo for energy reasons, resulting in the well known "dying duck beeps". Some say this could be fixed with a decent speaker.


Teardown
Taking this thing appart reveals a microSD card, STM32WB55 MCU with Bluetooth, ICM-42605 IMU, DPS310 barometer and GOTOP GT-1110-SN GPS with ceramic antenna.



The battery charge controller is a HP4555, for USB/Solar power switching a MAX40203 is used.
The main PCB says "BlueBip", at the time I bought this, the BlueBip wasn't out. Now I know: an UltraBip is just a BlueBip with the GPS + Speaker extention board. Firmware is identical. So feel free to source some components and make the expansion yourself (difference in price is 100€).
- Connector should be DF40HC(3.5)-30DS-0.4V(51)
- Audio amp: Need to check the signals first.
- Speaker something like "2209" on Alibaba
- GPS antenna: Cirocomm 16x6x4mm (PA166AA0000)
- GPS: GT-1110, the Sony (SN) version is rare, the MediaTek MTK is more common. Probaply check if it is just NMEA, so any GPS would be ok.
Pinout:
1: TP12 + P1 AMP
2: connected to 4
3: NC
4: connected to 2
5: NC
6: TP7
7: NC
8: TP8 + P4 AMP (RC network)
9: TP9 + P3 AMP (RC network)
10: NC
11: TP10 + P7 AMP
12: NC
13: TP6
14: NC
15: TP11 + P2 AMP
16: 3,3V GPS (1,8R and load switch)
17: GPS VCC switch + TP16
18: NC
19: NC
20: NC
21: NC
22: TP19
23: GND
24: GPS RX/TX 220R
25: NC
26: GPS RX/TX 220R
27: TP20
28: NC
29: 10k to GPS GND
30: TP24
AMP pinout:
1:
2: P6
3:
4:
5: Speaker +
6: P2
7:
8: Speaker -

The speaker amp must be something lika a TPA2005D1 (didnt find the exact part "ZB3"), USB audio seems to be handled by a FSA221 switch using D+/D- lines as headphone R/L on the C-type socket if triggered.
As the W55 don't have a DAC, the audio generation needs to be done by an external DAC. The SMD markings of the remaining pasts don't help here, but pin-count wise (6) it is I2C (or a special mono I2S PCM chip driven by the ST SerialAudioInterface, but I don't know any of them)

The case propably uses the same mold as the previous varios. Some parts of the plastic need to be removed manually? to fit the GPS antenna, speaker and USB C socket.


Audio Output
The device features audio output over USB. But not the smartphone like with external DAC, you need a special adapter. There is a IC (FSA221) for switching the USB data lines to audio lines when CC1/CC2 are pulled to ground by the male USB plug. When USB audio is connected, the internal buzzer and speaker are muted.
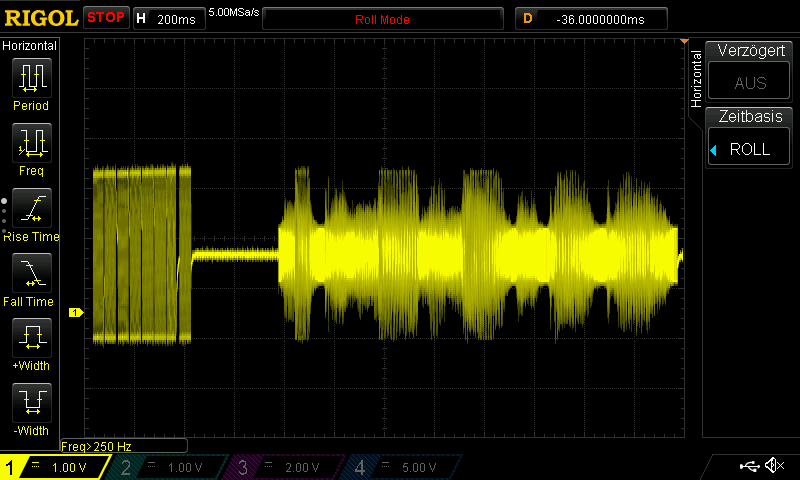
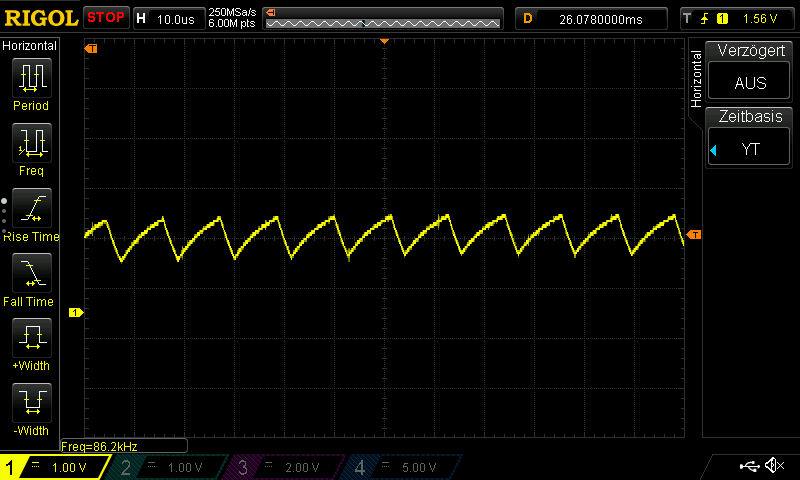
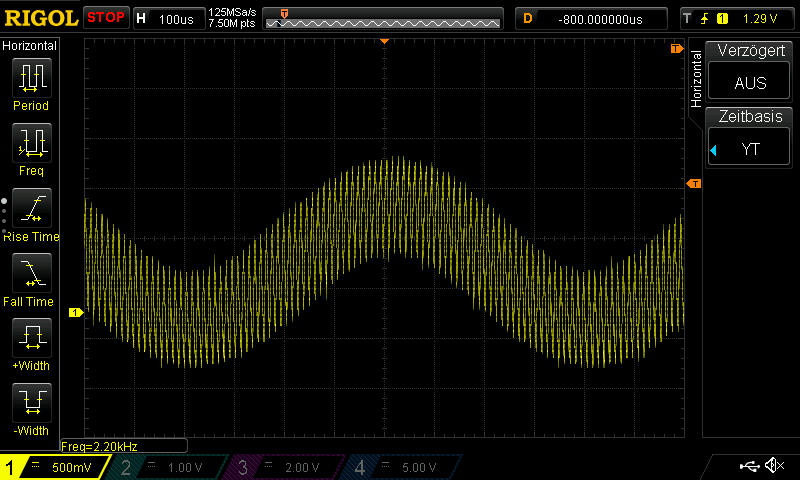
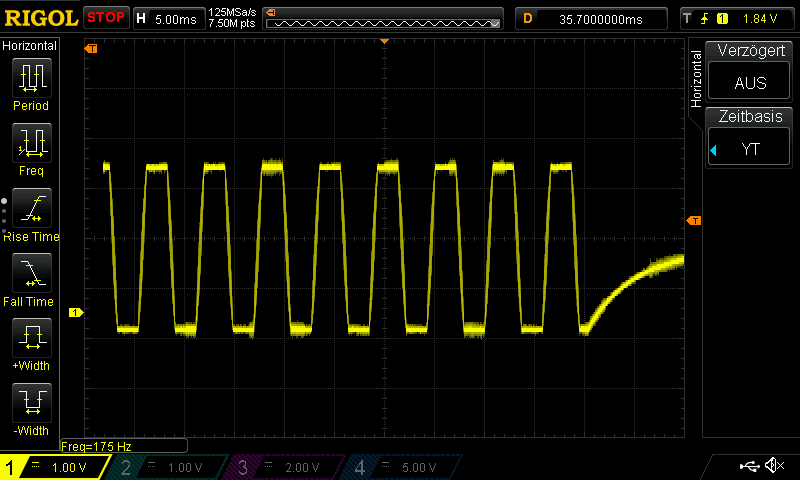
Making Custom Voice Pack
2023-05 Update:
The new firmware uses a "new efficient smaller and compressed format" aka lossy QOA (Quite OK Audio Format), so the wav files need to be converted after generation.
Witin the voicepack they finally seperated time and duration.
The code for voice generation below is updated, and I added the whole jupyter notebook plus readymade voicepacks in this project. One is filtered (higher volume, see code below), the other one is unedited from google tts (less volume, less distorsion)
____________________
As I don't like the voice and some wordings of the german audio files e.g. "Schwerwert für Sinkton", I decided to build my own voice package using Googles Wavenet TTS. The .ubpack file is ?FAT12 RAW file system blob? which can be mounted on linux and extract its contents easily.
For compatibility the .WAV nees to be the same format (16-bit, 22.05 kHz, mono) as the original files, which is the default output of google tts anyway. For better acustics I applied a bandpass/highpass for filtering out ervthing below 400 Hz. This may also save some energy. As the voice beeing too silent you need to boost it a bit. In my case x1.9 is a good compromise betweed distortion and volume
For using google tts you have to add a billing account, but there a 1M chars for free each month, generating voice pack is below 12k chars, so no problem.
import os
import scipy.signal as sg
from scipy.io import wavfile
import glob
import fnmatch
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]="google-api.json" <-- get yours from google
from google.cloud import texttospeech
client = texttospeech.TextToSpeechClient()
voice = texttospeech.VoiceSelectionParams(language_code='de-DE',name='de-DE-Wavenet-B',ssml_gender=texttospeech.SsmlVoiceGender.MALE)
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.LINEAR16,
speaking_rate = 1.12,
pitch = 5,
volume_gain_db = 10,
sample_rate_hertz = 22050
)
# https://cloud.google.com/text-to-speech/docs/reference/rpc/google.cloud.texttospeech.v1beta1#google.cloud.texttospeech.v1beta1.AudioConfig
# https://cloud.google.com/text-to-speech/docs/voices
def tts(fname, tinput):
synthesis_input = texttospeech.SynthesisInput(text=tinput)
response = client.synthesize_speech(input=synthesis_input, voice=voice, audio_config=audio_config)
with open("./out/"+fname+'.wav', 'wb') as out:
out.write(response.audio_content)
def prepare():
l.append(['time/duration', 'Flugzeit:'])
l.append(['time/time', 'Uhrzeit:'])
for i in range(24):
if i == 1:
l.append(['time/hour_{0}'.format(i), '{0} Uhr'.format(i)])
else:
l.append(['time/hour_{0}'.format(i), '{0} Uhr'.format(i)])
for i in range(24):
if i == 1:
l.append(['time/duration_{0}'.format(i), '{0} Stunde'.format(i)])
else:
l.append(['time/duration_{0}'.format(i), '{0} Stunden'.format(i)])
for i in range(60):
if i == 1:
l.append(['time/min_{0}'.format(i), '{0} Minute'.format(i)])
else:
l.append(['time/min_{0}'.format(i), '{0} Minuten'.format(i)])
for i in range(-100,5000,10):
l.append(['al/al_{0}'.format(i), '{0} Meter'.format(i)])
for i in range(5000,7001,100):
l.append(['al/al_{0}'.format(i), '{0} Meter'.format(i)])
for i in range(0,80,1):
l.append(['sp/sp_{0}'.format(i), '{0} Kilometer pro Stunde'.format(i)])
for i in range(85,201,5):
l.append(['sp/sp_{0}'.format(i), '{0} Kilometer pro Stunde'.format(i)])
l.append(['nav/wind_speed', 'Windgeschwindigkeit'])
l.append(['nav/wind', 'Windrichtung'])
l.append(['nav/heading', 'Richtung'])
l.append(['nav/e', 'Ost'])
l.append(['nav/n', 'Nord'])
l.append(['nav/ne', 'Nord Ost'])
l.append(['nav/nw', 'Nord West'])
l.append(['nav/s', 'Süd'])
l.append(['nav/se', 'Süd Ost'])
l.append(['nav/sw', 'Süd West'])
l.append(['nav/w', 'West'])
for i in range(0,61,1):
l.append(['voices/{0}'.format(i), '{0}'.format(i)])
for i in range(0,101,25):
l.append(['voices/{0}_percent'.format(i), '{0} Prozent'.format(i)])
l.append(['voices/altitude_max', 'Maximale Höhe:'])
l.append(['voices/auto_shutdown', 'Automatische Abschaltung in:'])
l.append(['voices/bat_charging', 'Batterie lädt'])
l.append(['voices/bat_empty', 'Batterie: leer'])
l.append(['voices/bat_low', 'Batterie: schwach'])
l.append(['voices/bat_med', 'Batterie: mittel'])
l.append(['voices/bat_good', 'Batterie: voll'])
l.append(['voices/bluetooth_connected', 'Bluetooth verbunden'])
l.append(['voices/bluetooth_disconnected', 'Bluetooth getrennt'])
l.append(['voices/bluetooth_off', 'Bluetooth deaktiviert'])
l.append(['voices/bluetooth_on', 'Bluetooth aktiviert'])
l.append(['voices/contact', 'Bitte kontaktieren Sie das Support Team'])
l.append(['voices/dot', 'Punkt'])
l.append(['voices/error', 'Fehler'])
l.append(['voices/firmware', 'Firmware'])
l.append(['voices/gps_disabled', 'GPS deaktiviert'])
l.append(['voices/gps_ok', 'GPS ok'])
l.append(['voices/integration_settings', 'Integrationsstufe'])
l.append(['voices/language', 'Sprache: Deutsch'])
l.append(['voices/language_select', 'Wählen deine Sprache'])
l.append(['voices/language_selected', 'Deutsch ausgewählt'])
l.append(['voices/lift_threshold_settings', 'Grenzwert für Steig Ton'])
l.append(['voices/loading_config', 'Lädt Konfiguration'])
l.append(['voices/minus', 'Minus'])
l.append(['voices/no_gps', 'Suche GPS'])
l.append(['voices/plus', 'Plus'])
l.append(['voices/profile_1', 'Profil 1'])
l.append(['voices/profile_2', 'Profil 2'])
l.append(['voices/profile_3', 'Profil 3'])
l.append(['voices/profile_acro', 'Acro'])
l.append(['voices/profile_alpinism', 'Alpinismus'])
l.append(['voices/profile_bivouac', 'Biwak'])
l.append(['voices/profile_competition', 'Wettbewerb'])
l.append(['voices/profile_cross', 'Cross Country'])
l.append(['voices/profile_hike', 'Hike and Fly'])
l.append(['voices/profile_paragliding', 'Gleitschirm'])
l.append(['voices/profile_paramotor', 'Paramotor'])
l.append(['voices/profile_select', 'Profil auswählen'])
l.append(['voices/profile_selected', 'ausgewählt'])
l.append(['voices/profile_speedriding', 'Speedriding'])
l.append(['voices/profile_tandem', 'Tandem'])
l.append(['voices/recording', 'Aufzeichnung'])
l.append(['voices/reset_hold', 'Halte die Taste zum zurücksetzen auf Werkseinstellungen gedrückt'])
l.append(['voices/reset_wait', 'Auslieferungszustand wird geladen, bitte warten'])
l.append(['voices/settings_5', '5 Zentimeter pro Sekunde'])
l.append(['voices/settings_10', '10 Zentimeter pro Sekunde'])
l.append(['voices/settings_15', '15 Zentimeter pro Sekunde'])
l.append(['voices/settings_20', '20 Zentimeter pro Sekunde'])
l.append(['voices/settings_30', '30 Zentimeter pro Sekunde'])
l.append(['voices/settings_40', '40 Zentimeter pro Sekunde'])
l.append(['voices/settings_50', '50 Zentimeter pro Sekunde'])
l.append(['voices/sink_alarm_settings', 'Grenzwert für Sink Ton'])
l.append(['voices/speed_max', 'Maximale Geschwindigkeit'])
l.append(['voices/takeoff', 'Abflug'])
l.append(['voices/takeoff_off', 'Abflugerkennung deaktiviert'])
l.append(['voices/takeoff_on', 'Abflugerkennung aktiviert'])
l.append(['voices/tap_disabled', 'Doppeltipp deaktiviert'])
l.append(['voices/timezone', 'Zeitzone'])
l.append(['voices/update_fail', 'Fehler: Update fehlgeschlagen'])
l.append(['voices/update_ok', 'Update erfolgreich'])
l.append(['voices/updating', 'aktualisiere'])
l.append(['voices/vario_disabled', 'Vario deaktiviert'])
l.append(['voices/vario_lift_0', '0 Meter pro Sekunde'])
for i in range(10,51,10):
l.append(['voices/vario_lift_{0}'.format(i), '0,{:0.0f} Meter pro Sekunde'.format(i/10)])
for i in range(100,1001,100):
l.append(['voices/vario_lift_{0}'.format(i), '{:0.0f} Meter pro Sekunde'.format(i/100)])
for i in range(150,1001,100):
l.append(['voices/vario_lift_{0}'.format(i), '{:0.1f} Meter pro Sekunde'.format(i/100)])
for i in range(10,51,10):
l.append(['voices/vario_sink_{0}'.format(i), 'minus 0,{:0.0f} Meter pro Sekunde'.format(i/10)])
for i in range(100,1001,100):
l.append(['voices/vario_sink_{0}'.format(i), 'minus {:0.0f} Meter pro Sekunde'.format(i/100)])
for i in range(150,2001,100):
l.append(['voices/vario_sink_{0}'.format(i), 'minus {:0.1f} Meter pro Sekunde'.format(i/100)])
l.append(['voices/version', 'Version:'])
l.append(['voices/voice_auto_off', 'Automatische Ansage deaktiviert'])
l.append(['voices/voice_auto_on', 'Automatische Ansage aktiviert'])
l.append(['voices/voice_pack', 'Sprachpaket'])
l.append(['voices/voice_update', 'Bitte Sprachpaket aktualisieren'])
l.append(['voices/voice_updated', 'Sprachpaket aktualisiert'])
l.append(['voices/vol_0', 'Vario stumm'])
l.append(['voices/vol_1', 'Lautstärke: leise'])
l.append(['voices/vol_2', 'Lautstärke: mittel'])
l.append(['voices/vol_3', 'Lautstärke: laut'])
l.append(['voices/vol_4', 'Lautstärke: sehr laut'])
l.append(['voices/vz_max', 'maximales Steigen'])
l.append(['voices/wait', 'bitte warten'])
l.append(['voices/warning', 'Achtung'])
l.append(['voices/weak_lift_off', 'Nullschieberton deaktiviert'])
l.append(['voices/weak_lift_on', 'Nullschieberton aktiviert'])
# new 2023-04-21
l.append(['voices/battery', 'Batterie'])
l.append(['voices/bluetooth', 'Bluetooth'])
l.append(['voices/bluetooth_pair', 'Bluetooth Kopplung aktiviert'])
l.append(['voices/bluetooth_pin', 'Bluetooth Pincode lautet'])
l.append(['voices/bluetooth_remote_event', 'Bluetooth Fernbedienugsmodus'])
l.append(['voices/gps', 'GPS'])
l.append(['voices/landing', 'Landung'])
l.append(['voices/memory', 'Speicher'])
l.append(['voices/gps', 'GPS'])
l.append(['voices/sensors_imu', 'Beschleunigungssensor'])
l.append(['voices/sensors_pressure', 'Barometer'])
l.append(['voices/solar_cell', 'Solarzelle'])
l.append(['voices/vario_sink_off', 'Sinkton deaktiviert'])
l.append(['voices/vz_min', 'Maximales Sinken'])
def filter_audio(f):
lf = 400.
hf = 11000.
fr, x = wavfile.read(f)
b, a = sg.butter(4, [lf / (fr / 2.), hf / (fr / 2.)], 'bandpass')
x_fil = sg.filtfilt(b, a, x).astype('int16')
x_fil = (x_fil.astype('float')*1.9).astype('int16')
wavfile.write('./filtered/'+f, fr, x_fil)
l =[]
prepare()
# place overwrites here, like naming your profiles
# l.append(['voices/profile_1', 'Profil myfirstwing'])
# l.append(['voices/profile_2', 'Profil mysecondwing'])
count = 0
chars = 0
for i in l:
count+=1
chars += len(i[1])
print(str(count/len(l)*100) + ' %',end=' \r')
tts(i[0], i[1])
print('\ndone')
print(chars, "chars")
# increase volume and apply bandpass
for root, dirnames, filenames in os.walk('out'):
for filename in fnmatch.filter(filenames, '*.wav'):
filter_audio(root+'/'+filename)
# make audio package file by mounting it and replace the old .wav files
After generation you need to pack the FAT12 file again. The fastest way I found was to copy a original file, mount it, remove the old content, unmount and save it as template.
From there you can put your audio files as long as it is below 125MB.
# Pack FAT12 audio package. run as sudo rm de.ubpack cp temp.ubpack de.ubpack mount de.ubpack ./mnt cp -r ./out/* ./mnt/ umount ./mnt
Have fun.
To Stodeus: your "Indeed, we fixed the German voicepack with the help of native speaking pilots this winter..." you should propably find someone not being an illiterate. Still horrible.
And also think about different voices, I like the mal voice much more, because it is not so shrill.