 glgorman
glgorman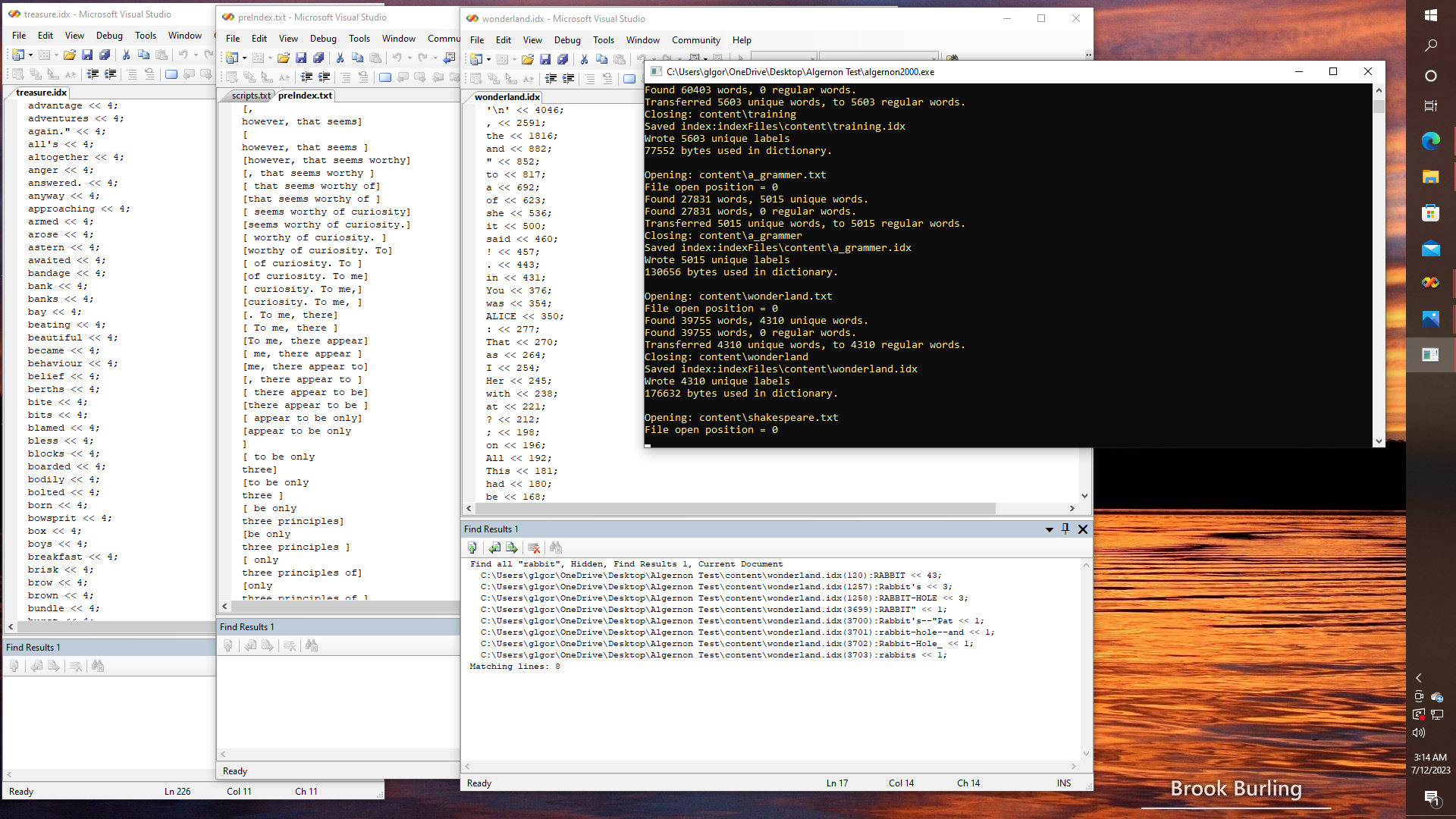
Alright. Here is some random nonsense, before we get back to the topic of binary trees, shrubberies, and so on; that is for those who prefer to chase rabbits during the meanwhile, that is. If my indexing software is working correctly, the word ALICE occurs 350 times in "The Adventures of Alice in Wonderland", whereas there are several variations of RABBIT (43 times), Rabbit's (3 times), RABBIT-HOLE (3 times), etc. Then again, in "Treasure Island" it would appear that the words "advantage", "adventures", "anger", and so on, each appear exactly four times.
Now the next step, of course, is to construct another "index" which captures the context in which each word might occur and construct another tree structure, (or another shrubbery if you know what I mean!) that contains context information for every word, so that we can either reconstruct the original texts from the contextual fragments, or else we can generate new weird and seemingly random stuff, and this, in turn, is how a simple model for a "Markov-chain" based chat engine cand be built, since by adding additional layers to the onion, we can by a way of a statistical analysis attempt to "predict" the next word in a sentence.
It is also quite possibly how it was that I unintentionally invented the first variant of what became known as a "Google BOMB" sometime back around 1998 when I indexed "War and Peace" and a bunch of stuff, and then created a website with the indexes and context information for about 5000 common English words, that was then re-sorted and presented in a hybrid format that was meant to be able to combine some of the features of a Concordance of the Bible, with a massive database created by indexing and analyzing dozens of other works, so that if you clicked on a word (which had a hyperlink) if you wanted to, and then read "context information" in a very rough way, so that you could then click on the next word, and then jump to another web page, that would allow you to "continue to follow" that context, or you could change contexts if you wanted to, by jumping back and forth between documents, and so on.
Now getting this to work with a training set that includes hundreds of thousands of books is one challenge, while another is getting it to work on an Arduino, or a Raspberry Pi so that we can train it with whatever it needs to "learn" about solving mazes or killing trolls, or making a deluxe pizza without burning the house down that is.
Thus, while there have been many attempts to do some form of generative AI, all of them are deficient in one way or another. Sometimes the code is simply bloated and impossible to understand, or maintain, or there are legal issues affecting its use, one way or another, because of terms of use, or else the developers have used third-party materials without obtaining the required permissions. But of course, you knew that. Or else there are bots like Eliza, or Megahal, which either used a fixed, i.e., hard-coded and very limited pattern matching scheme (Eliza), or else did not support large language models, with multiple training sets, i.e., since the original MegaHal was a single-threaded application that used just one training file as input, neither was it 64-bit aware, or "large data" aware, in some form or fashion.
Just figuring out ways of managing large dictionaries can be quite the challenge, since it is all too easy for the heap to fragment, or new char [] to return NULL when you are making millions of calls to malloc or whatever, and like a stupid brain-dead rat, the program doesn't seem to want to do anything but roll over and die.
Yet there is so much more that can be done with this, and interesting stuff at that, since as the authors of a certain paper have claimed, "Large Language Models (LMM) can be effective unsupervised learners", which proves a very interesting point, on the one hand, but which leaves open an important question: What about systems that are based on smaller "custom crafted" and therefore specialized training sets. Isn't that what is actually needed in many cases, such as "tech support" applications, or in any potential use case that might involve "natural language software development?"
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.