 joey castillo
joey castilloNOTE: This project log was originally posted on 08/05/2023 at 19:00 EDT, but due to a misunderstanding, it had to be deleted and remade.
There’s a note in my notepad, under the broad subject area of retrocomputing: “Fundamental tension: understanding the past vs inventing the future.” Today’s notions of computing are the result of decades of choices, conscious and unconscious, by people in the past who invented the future. Some of those choices were the result of deep discussions of technical merit; others were based on expediency or commercial considerations. Either way, these choices ended up written into specifications and protocols, many of them coded in software, but many also implemented in in hardware, creating a built world of objects that represents the past’s implementation of the future.
Sometimes, the past got it right. Sometimes, it got it wrong. I think it’s important to understand what the past got wrong so that we can invent a better future.
One big area where the past intersects with the Open Book is in the encoding of languages. I’ve long felt strongly that the Open Book should support readers of books in all the languages of the world. That means it needs to have some way to store texts in all the world’s languages, and display them on an e-paper display — all on a tiny, low-power microcontroller with the RAM of a computer from the late 1980s and the compute power of a computer from the mid 1990s.
Let’s take a trip back in time: what did this era of computing look like?
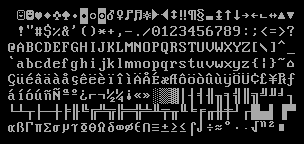
Well, in the late 1980s, you had ASCII, which is lines 2, 3 and 4 of this graphic, and includes glyphs for English letters, numbers and punctuation marks. Many computers also supported “Extended ASCII,” which the first line and the bottom half of this graphic. With this extension, you got characters for several more Western European languages, as well as some symbols for math and engineering. The way this worked was this: your graphics card would have stored bitmap representations of each of these glyphs on a little ROM chip (probably 8 kilobytes), and when displaying text, it would look up the bitmap for each character and copy it into display RAM, so it could render on your monitor.
This worked fine if you were an English-speaking writer (or a Spanish-speaking mathematician). But if you were interested in transcribing works in a rare or endangered language (like, say, the Cherokee language), your computer wouldn’t be able to do that out of the box. In a world of 8 kilobyte character ROMs, those well-intentioned folks in the past couldn’t fit every language into your computer and make it commercially viable. Moreover, ASCII only has 128 code points (256 if you really stretch it).
Those folks in the past had painted themselves into a corner: there was literally no room left to encode more languages.
Unicode: Solving the Encoding Problem
If you’re not familiar with Unicode, here’s the one sentence pitch: it’s an attempt to unify all the world’s writing systems — ancient and modern, past, present and future — into a single universal character encoding. Under Unicode, every glyph for every character that is or ever has been is assigned a unique code point. There are 1.1 million of them available, and we haven’t yet hit 10% utilization.
Technically, Unicode was invented in 1991, and computers were getting more capable and powerful throughout the 1990s. Seeing as we had solved this problem from a technical perspective, surely operating systems and users all adopted this new universal character encoding quickly, ushering in a golden age of interoperability, peace and prosperity.
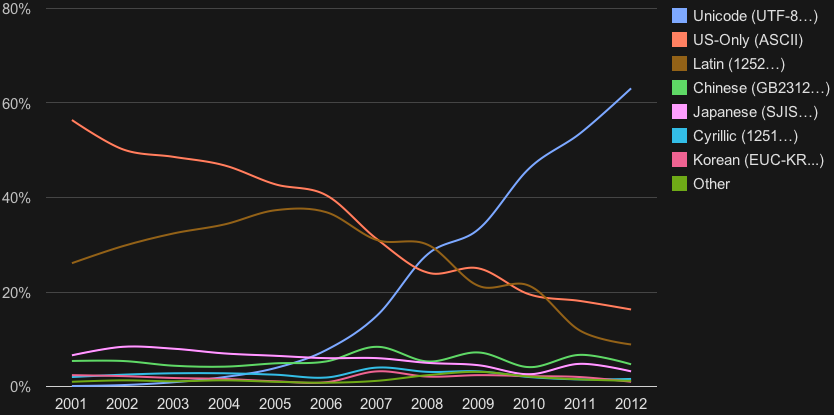
Of course, I’m only joking! In reality a patchwork of mutually incompatible code pages dominated the early days of personal computing, remapping the 256 ASCII code points to different languages in a manner that all but guaranteed that any attempt to open a non-Western file would result in completely incomprehensible mojibake. It wasn’t until the 2010s that Unicode achieved a majority share of the text on the Internet.
And yet! Even then (and even now), there was/is no guarantee that your operating system could/can actually display these properly encoded texts. Because even today, with a smartphone thousands of times more powerful than the most iconic supercomputer of the 20th century, there’s no guarantee that your operating system vendor cared enough to draw glyphs for the Cherokee language (ᏣᎳᎩ ᎦᏬᏂᎯᏍᏗ).
This is a choice.
GNU Unifont, and an Introduction to Babel
I hope that earlier when you read the description of Unicode — an attempt to unify all the world’s writing systems — you read that as as ambitious as it actually is. Like, seriously: 🤯.

The Open Book builds on another ambitious project: GNU Unifont. Unifont is an attempt to create one universal bitmap font, with a glyph for every single character in this universal character encoding. The Open Book, up to now, has done something very similar to what the IBM graphics card did with its 8 kilobyte character ROM: it’s included a 2 megabyte Flash chip, flashed on first boot with bitmap glyphs for every code point in the Unicode Basic Multilingual Plane (or BMP).
For reference, the BMP contains 65,520 glyphs. The majority of these are Chinese, Japanese and Korean characters, but it also encompasses characters for essentially every language in use today: Latin and non-Latin European scripts (Greek, Cyrillic); Aramaic scripts like Hebrew and Arabic; Brahmic scripts for Hindi, Nepali and Sanskrit; and yes, tribal languages like Cherokee. Without getting exhaustive, the gist of GNU Unifont is this: you name it, we’ve got it.

I call my Unicode support library “Babel” (for obvious reasons), and I have some fun notes about how the book gets good performance out of its massive library of glyphs. I think I’ll write about that in a Part II next week, just because this project update is getting long. Mostly I want to close this post by talking about the importance of universal language support, why for me it’s the sine qua non of this whole thing.
Universal Language Support: Why it Matters
It’s a bit of a truism to say that language and culture are deeply linked, so sure, it’s not surprising that a device that aspires to display cultural works would aspire to support many languages. But it’s more than that. Throughout history, attacking language has been a tool for erasing culture. Often this was explicit and overt, like the Native American boarding schools that forbade students from speaking their native tongues. And to be clear, I’m not suggesting that the engineers who made English characters the lingua franca of computing were committing an intentional act of colonialism. But you don’t need intent to have an effect: the hegemony of ASCII, for years, made second-class citizens of billions of computer users by excluding their languages by default.

On the other hand, seeing your language acknowledged and being treated as worthy of inclusion? That, to me, feels empowering. The Open Book doesn’t have a separate code path for rendering ASCII glyphs versus glyphs for any other language. There’s no extra configuration to read Leo Tolstoy in the original Russian, or The Thousand and One Nights in the original Arabic. The Open Book aims to support all languages and treat them the same way.
This, too, is a choice.
A couple of years back, I saw a talk by Rebecca Nagle, a writer and activist and citizen of the Cherokee nation. Her talk specifically called out the link between tribal language and world view; the idea that the Cherokee language is a crucial link to a way of life that’s been under attack for centuries. The Cherokee language is deeply endangered language today; by some estimates, only about 2,000 Cherokee speakers remain. One dialect is extinct.
Coordinated efforts are underway to save the Cherokee language. Technology can help that effort with its support, or harm that effort through indifference. In both encoding code points for the Cherokee Language and drawing glyphs to represent it, Unicode and Unifont support those efforts — and by building on those foundations, the Open Book does too.
To me, this represents the best that technology can aspire to. It shows the good that can come when we focus on universal access over bells and whistles, when we focus on choices that empower every user.
That’s the kind of future I want to invent.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.
This technology looks very interesting. It seemed like a simple idea, but I didn't even think about it. But I don’t have time for this, and I’ve already found an assignment expert for college, I use https://essays.edubirdie.com/assignment-expert for this. The main thing is not to listen to anyone, do as you know. I believe in you, I want to see such a book live.
Are you sure? yes | no
Very cool book
Are you sure? yes | no