Motivation
In order to support the development of gesture controlled musical instruments like for example lalelu_drums, I want to run a human pose estimation AI model with a high frame rate (>=75 frames per second (fps)). I found the Google Coral AI accelerator an interesting device, since it is compatible with single board computers like Raspberry Pi and there are ready-to-use pose detection AI models available for it.
The code (python only) supporting this project is hosted on GitHub.
Choosing the network
I did some tests with the PoseNet model, that is available in various precompiled versions for the Coral, but I found that it has limited performance for my use case, especially when it comes to moving the legs. When I raised and lowered my legs like in an exaggerated walking motion, the PoseNet results for the leg keypoints often switched to wrong coordinates in the image. Therefor, I was happy that Google released the Movenet pose estimation model and also provided precompiled versions for the Coral. Movenet is trained with image data specific for sports and dancing, so I think it is close to ideal for my purpose.
Movenet comes in two sizes: the smaller, faster and less precise 'lightning' and the larger, slower but more precise 'thunder'.
Speed benchmarking
The Google Coral AI accelerator advertises itself with very low inferences time on its webpage. However, when I tried to reproduce these values with my own benchmark, I got much longer inferene times.
| movenet lightning | movenet thunder | |
| from coral.ai | 7.1 ms | 13.8ms |
| measured (Raspberry Pi 4 + Coral) | 20.9 ms | 39.4 ms |
| measured (Raspberry Pi 4 overclocked + Coral) | 14.5 ms | 27 ms |
The explanation for this behaviour is, that only a fraction of the calculations necessary for the movenet inference is actually performed on the Coral, while the significant rest is done on the CPU, since the Coral does not support all the necessary operations. Therefor, inference speed depends heavily on the CPU.
So, I overclocked the Raspberry Pi with the following settings in config.txt
over_voltage=6 arm_freq=2000 force_turbo=1
As shown in the table, the inference times could be reduced by ~30%, but still they do not allow frame rates >= 75fps. My solution to overcome this limitation is shown below, but first I would like to discuss the selection of the camera.
Choosing the camera
I started off using the Raspberry Pi camera V1, which was working fine. However, I later switched to the PS3 camera (Play Station Eye) for the following reason.
The PS3 camera is connected via cable that can be several meters long (I could successfully use a USB extension cable). This is important for my application, since if you are playing gesture controlled musical instruments in front of an audience, the camera will be between you and the audience and therefor should be as unobstrusive as possible. In case of the Raspberry Pi camera, it would not only be the camera, but also the Raspberry Pi and the Google Coral USB accelerator and there would not only be a single USB cable, but at least one power cable plus audio output cable.
So, I recommend the PS3 camera, also for the following other advantages:
- Available second-hand for a few euros
- Integrated to the linux kernel for a long time, so should work with any linux distribution
- Supports high frame rates (up to 187fps)
- Large pixels, meaning that if you want low resolution images anyway, you need no preprocessing (binning) and you collect a lot of light.
(Obviously, the PS3 camera was designed for applications very similar to mine)
The biggest disadvantage I see is that the available frame rates have quite a coarse spacing. In the regime I am interested in, there is 50, 60, 75 and 100fps.
Unfortunately, the PS3 camera is not manufactured anymore. So if you know a good alternative with similar features, please let me know.
Time interleaved strategy
My solution to achieve 75fps with a movenet inference time of ~15ms is to use two Google Coral USB accelerators in parallel, in a time interleaved fashion.
To allow parallel execution of the movenet inference, I created separate worker processes, one for each Coral, and assigned each to a specific CPU core. As described above, a significant fraction of the movenet inference accelerated by the Coral is carried out on the CPU, so it is necessary to reserve separate CPU cores to achieve full parallelization.
The strategy is visualized in the following drawing. Every new frame event triggers an event handler in the main process. The event handler forwards the new frame data to one of the worker processes for movenet inference. Then, the main process waits for the other worker process to finish its inference task. Since the movenet inference takes only little longer than one frame interval, there remains a significant time slot for custom downstream processing of the human pose data.
In principle, this approach can also be used with more than two Corals.

The communication between the processes is done with the tools provided by the multiprocessing python library. Signalling is done using Event objects and data transfer is done with the help of shared memory arrays.
It is clear that this strategy does not reduce the latency of the human pose estimation below the numbers given in the table above. Still, for the application in the regime of gesture controlled musical instruments, the gain in temporal resolution the presented strategy provides, can make a critical difference.
Results on RaspberryPi 4B
In the following some experimental results on a Raspberry Pi 4B (1GB) are given. The setup of the OS and the necessary libraries is described here. Note that it is crucial to use an OS without graphical user interface, so that the system is not slowed down by the many background tasks of a full desktop installlation.
Here is a video demonstration of example_pose_pipeline.py. Live camera images with 75fps are processed with the movenet lightning model and the lateral coordinate of the nose of a person in the image is provided as console output.
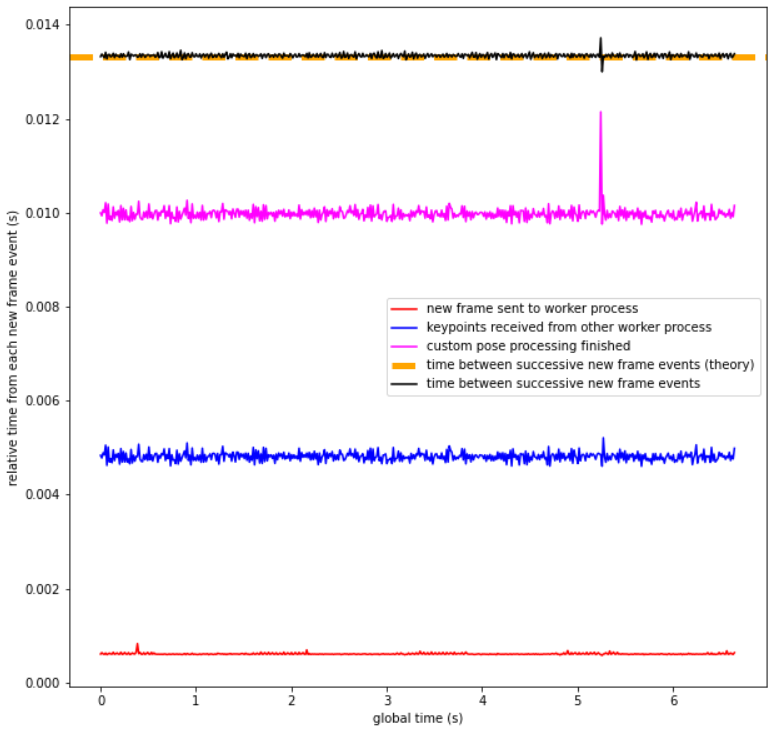
Here is some profiling data of 500 consecutive frames. It can be seen that the time between successive new frame events matches well the theoretical expectation at 75fps.
The transfer of the new frame to a worker process takes below 1ms, typically.
At ~5ms from the new frame event, the pose estimation result from the previous frame is available and downstream processing of the pose data can start. In this example, I added a 5ms sleep command to simulate the duration of some custom pose processing, therefor the pink curve is at ~10ms (5ms + 5ms).
Most importantly, the maximum available time for the event handler (13.3ms) is always met, so that no frames are lost. In the video, it can only be seen indirectly by the fact that there are NO gstreamer warnings about loosing frames.
To achieve this 'almost realtime' performance, I make use of the following two settings for each worker process
- With the psutil library I set the CPU affinity to a specific CPU core (see movenet_process.py#L70)
- With the chrt command I set the scheduler to round-robin scheduling (see movenet_process#L67)
If I omit these two settings, the timing behaviour is much more chaotic and not usable for making music:

Finally, here is the htop output during the example run, showing that cores 2 and 3 are busy with inference. Note that the application easily fits into the 1GB ram of this Raspberry Pi.

Unfortunately, the examle currently does not work with the thunder movenet model. I assume it is due to power shortage on the USB ports, so as soon I have an active USB hub available, I will try it out.
Where's the hack?
Actually, there is not so much hacking in here. I more or less used all the components for what they were designed for. From my view the strongest hacking aspect is, that I use a high-level language like python to achieve almost realtime low-latency video processing, which would typically be done with a more hardware-centric language.