 Patrick Yeon
Patrick YeonMost of this post is going to be down in the embedded software nitty-gritty, but I think I'll start you off with a little video. Here's a neurobyte board on my bench emulating a "chattering" neuron:
Having written and verified an integer-based model of the neuron (as I've described in my previous post), I now need to check that it's still accurate on actual hardware and see that it can run at an acceptable speed. To do this, I split my code into a main loop, and a library that does all of the neuron work, then wrote a second main file to setup all of the hardware peripherals and run a timing loop on the microcontroller:
#include <libopencm3/stm32/rcc.h>
#include <libopencm3/stm32/gpio.h>
#include "./izhi.h"
#define FLOATPIN GPIO1
#define FIXEDPIN GPIO3
int main(void) {
rcc_periph_clock_enable(RCC_GPIOA);
rcc_periph_clock_enable(RCC_GPIOB);
gpio_mode_setup(GPIOA, GPIO_MODE_OUTPUT, GPIO_PUPD_NONE, GPIO15);
gpio_mode_setup(GPIOB, GPIO_MODE_OUTPUT, GPIO_PUPD_NONE, GPIO5);
gpio_clear(GPIOA, GPIO15);
gpio_clear(GPIOB, GPIO5);
fneuron_t spiky_f;
ineuron_t spiky_i;
RS_f(&spiky_f);
RS_i(&spiky_i);
for (int i = 0; i < 5000; i++) {
if (i < 100) {
step_f(&spiky_f, 0, 0.1);
step_i(&spiky_i, 0, 10);
} else {
gpio_set(GPIOA, GPIO15);
step_f(&spiky_f, 10, 0.1);
gpio_clear(GPIOA, GPIO15);
gpio_set(GPIOB, GPIO5);
step_i(&spiky_i, 10 * spiky_i.scale, 10);
gpio_clear(GPIOB, GPIO5);
}
}
}I also added a simple Makefile to keep track of the build details:
ARM_PREFIX = arm-none-eabi-
OPENCM3_DIR = ./libopencm3
CC = gcc
LD = gcc
RM = rm
OBJCOPY = objcopy
ARM_ARCH_FLAGS = -mthumb -mcpu=cortex-m0plus -msoft-float
ARM_CFLAGS = -I$(OPENCM3_DIR)/include -DSTM32L0 $(ARM_ARCH_FLAGS)
#ARM_CFLAGS += -fno-common -ffunction-sections -fdata-sections
ARM_LDLIBS = -lopencm3_stm32l0
ARM_LDSCRIPT = $(OPENCM3_DIR)/lib/stm32/l0/stm32l0xx8.ld
ARM_LDFLAGS = -L$(OPENCM3_DIR)/lib --static -nostartfiles -T$(ARM_LDSCRIPT)
ARM_LDFLAGS += $(ARM_ARCH_FLAGS)
host:
$(CC) izhi.c host.c -o host.o
stm:
$(ARM_PREFIX)$(CC) $(ARM_CFLAGS) -c izhi.c -o izhi.o
$(ARM_PREFIX)$(CC) $(ARM_CFLAGS) -c stm.c -o stm.o
$(ARM_PREFIX)$(LD) $(ARM_LDFLAGS) izhi.o stm.o $(ARM_LDLIBS) -o stm.elf
$(ARM_PREFIX)$(OBJCOPY) -Obinary stm.elf stm.bin
$(ARM_PREFIX)$(OBJCOPY) -Oihex stm.elf stm.hex
clean:
$(RM) *.o *.elf *.map *.binWith the code running on the native hardware, I fired up by trusty Saleae Logic analyzer to watch pins A15 and B5 to see the timing of my `step_f` and `step_i` loops, respectively.
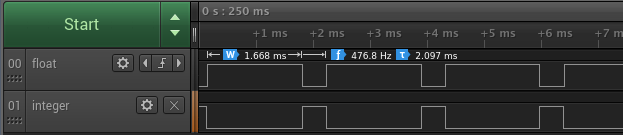

It looks like the fixed-point implementation runs 4x faster at ~0.4ms per loop, vs. ~1.67ms for the floating-point version. This surprised me, I actually expected the floating-point one to be much much worse! As a quick check, I re-compiled with `typedef int16_t fixed_t;` to see if 16 bit integers gave any improvement (I expected not, but especially with performance issues it's important to test one's assumptions), and the integer runtime went down to about 0.32ms per `step_i` loop. Of course, the behaviour would be completely incorrect because of the integer overflow I was struggling with when trying to develop a 16bit version, but it's good to have the datapoint that it looks like a series of 16bit operations takes about 80% as long as a matching series of 32bit operations.
For completeness, I checked the two most obvious compiler optimization settings: `-Os` (optimize for size with speedups that tend not to increase size) and `-O3` (optimize for speed). These led to floating and fixed point loop times of 1.54ms/0.4ms and 1.6ms/0.37ms, so not really huge gains to be had there. This time I'm not surprised; the work being done is pretty straightforward and maps pretty easily to assembly code.
So how fast do I need to get going? Well Zach didn't exactly give me a spec to hit, but in his log on implementing this for v07 he says he needs to update the LEDs every 30us and has the model calculations broken up in to 7 steps of no more than 29us each (there's also steps for reading input dendrites, calculating the value I'm passing as `synapse`, and translating the neuron state into a colour value for the LEDs). To match this I'll aim for less than 200us to run through the neuron model.
The first improvement is the easiest: when the STM32L0 used on the board I have reboots, it starts up with a 2MHz internal clock, but the chip can run up to 16MHz (actually, 32MHz, but the board I have doesn't have an external oscillator, so I'm limited to 16MHz). When I switched over to that oscillator, the simple `step_i` loop went down to 52us (plus an additional 0.8us spent turning the pin I'm using for timing on and off). Oh well that's right inside the 200us I just mentioned, so the smart thing to do would be to try to split the code inside `step_i` into two or three parts of roughly equal runtime and call it a day. But I'm pretty sure there's some easy wins to be had so I'll just go for those.
To jog your memory, here's how the `step_i` call looks right now:
typedef int32_t fixed_t;
#define SQRT_FSCALE 1000
#define FSCALE (SQRT_FSCALE * SQRT_FSCALE)
typedef struct {
// using 1/a, 1/b because a and b are small fractions
fixed_t a_inv, b_inv, c, d;
fixed_t potential, recovery;
} ineuron_t;
static void RS_i(ineuron_t *neuron) {
neuron->a_inv = 50;
neuron->b_inv = 5;
neuron->c = -65 * FSCALE;
neuron->d = 2 * FSCALE;
neuron->potential = neuron->recovery = 0;
}
static void step_i(ineuron_t *neuron, fixed_t synapse, fixed_t fracms) {
// step a neuron by 1/fracms milliseconds. synapse input must be scaled
// before being passed to this function.
if (neuron->potential >= 30 * FSCALE) {
neuron->potential = neuron->c;
neuron->recovery += neuron->d;
return;
}
fixed_t v = neuron->potential;
fixed_t u = neuron->recovery;
fixed_t partial = (v / SQRT_FSCALE) / 5;
neuron->potential = v + (partial * partial + 5 * v + 140 * FSCALE
- u + synapse) / fracms;
neuron->recovery = u + ((v / neuron->b_inv - u) / neuron->a_inv) / fracms;
return;
}When Zach had to speed up the math on the AVR, he changed all the multiplications and divisons to use powers of two, so that he could just use shift operations. The STM32 has a one-cycle integer multiplier, so I'll start off by attacking division operations. The easiest one is the `/ fracms` that I use twice per loop to step the model by timesteps shorter than a millisecond. Instead of having the function work with arbitrary fractions of a millisecond, I've reworked it so that the fraction needs to be a power of two (it will step by 2**(-fracms) milliseconds), and just used a simple shift instead of the divide.
Just this change has brought me down to 37us per loop! This is almost down to being able to run the full model every time the LED timing needs to be updated, so I'm going to press harder still. Even though the datasheet claims this chip has a single-cycle multiplier, I'd feel better seeing proof of the fact. Yes, datasheets have lied to me in the past so I will fact-check them when it's easy to do so. An easy place to start is a multiplication by a constant, so I changed the `v * 5` component to `(v + (v << 2))`, and now this runs at 37.4us per loop, worse than before. I changed it back, and I'm not going to try to eliminate any more multiplications.
Looking for my next target, the divisions by `neuron->a_inv` and `neuron->b_inv` would be hard to turn into shift operations (or even groups of shifts and adds) because they are elements of the model and I will want to keep the model as general as I can support. This leaves me the calculation of `partial` to work on.
`FSCALE` is completely implementation-dependent, and `1000` is conveniently close to `1024 == (2 ** 10)`. So changing `SQRT_FSCALE` to 1024 and replacing `(v / SQRT_FSCALE)` with `(v >> 10)` bought me... exactly no improvement. It doesn't seem right to me that I'd get 15us of speedup by removing two divides, and then no further speedup by removing a third, so I wanted to see what was happening. I added debug listings to the compiler output with the `-g` flag, and then re-compiled the original (two divides to calculate `partial`) and got an assembly listing (with the command `arm-none-eabi-objdump -S stm.hex > stm.list`) to see what the compiler was up to.
Here's the decompiled assembly for the calculation of partial:
fixed_t partial = (v / SQRT_FSCALE) / 5; 80002f8: 69fa ldr r2, [r7, #28] 80002fa: 23a0 movs r3, #160 ; 0xa0 80002fc: 0159 lsls r1, r3, #5 80002fe: 0010 movs r0, r2 8000300: f000 fb86 bl 8000a10 <__aeabi_idiv> 8000304: 0003 movs r3, r0 8000306: 617b str r3, [r7, #20]
Oh, clever compiler: there's only one division (the branch at location 8000300) there. gcc recognized that I was dividing by a known constant (`SQRT_FSCALE`) and then again by another known constant (5), and combined them into a single division call to help me out. I didn't get a speedup by eliminating one of the division operations because the compiler had already gotten this calculation down to one division for me. Oh well, I guess I'll just try harder...
My next gut reaction was to add up order-of-two fractions to approximate 1/5 (eg. 1/8 + 1/16 + 1/128 + 1/256 is 0.19921875, and that's pretty close), but that started to look like a lot of partial fractions to make up the precision. Instead, I figured I could do something like
#define LOG_SQRT_FSCALE 10
#define SQRT_FSCALE (1 << LOG_SQRT_FSCALE)
fixed_t partial = ((v >> LOG_SQRT_FSCALE) * x) >> y;where I would pick `x` and `y` to approximate overall dividing by 5. I want to make it easy to ensure I don't run into integer overflow problems again, so I'll keep `x` below `SQRT_FSCALE`:// 1024 * 5 = 5120
// log2(5120) = 12.322 (use 2**12 == 4096)
// 4096 / 5 = 819.2 (use 819)
fixed_t partial = ((v >> LOG_SQRT_FSCALE) * 819) >> 12;The error from replacing "divide by 5" with "multiply by 819 then divide by 4096" is about 244 parts per million, and I'm okay with that.Once again, I recompiled and ran the code and it got down to 30.2us per loop. Inspired by seeing the compiler combine divisors into one division call, I pulled `neuron->b_inv` out a level and cut down the work of calculating `neuron->recovery` to a single division, and got a huge improvement, with per-loop timing down to 17.8us! I don't know why that lopped over 12us off the loop timing when previously removing a divide would only shave 7us, but I'll take it.
//neuron->recovery = u + (((v / neuron->b_inv - u) / neuron->a_inv)
// >> fracms);
neuron->recovery = u + (((v - u * neuron->b_inv)
/ (neuron->b_inv * neuron->a_inv)) >> fracms);
I'm happy with where that stands for now, removing the final division is not impossible (my first attempt would be a pre-multiply and shift-right strategy like I did when calculating `partial`) but I think it would add too much complexity when setting up the neuron properties. Just to check and see how fast getting rid of the last division would be, I did a timing run with it replaced by a hard-coded right shift and it was down to 7.2us per loop. At least I know that speed is available if I want it and want to work for it.
The last thing to do is implement constructors for the other neuron types and then compare them to floating-point implementations. The actual calculations should not be affected by the performance improvements, but it'll be good to check to make sure. To do this I created a simple gnuplot script named neuroncheck.p:
set term png size 1280,960 set output 'tmp/rs.png' set title "RS neuron" plot 'neurons.dat' using 1:2 title 'float' with lines, 'neurons.dat' using 1:3 title 'fixed' with lines set output 'tmp/ib.png' set title "IB neuron" plot 'neurons.dat' using 1:4 title 'float' with lines, 'neurons.dat' using 1:5 title 'fixed' with lines set output 'tmp/ch.png' set title "CH neuron" plot 'neurons.dat' using 1:6 title 'float' with lines, 'neurons.dat' using 1:7 title 'fixed' with lines set output 'tmp/fs.png' set title "FS neuron" plot 'neurons.dat' using 1:8 title 'float' with lines, 'neurons.dat' using 1:9 title 'fixed' with lines set output 'tmp/lts.png' set title "LTS neuron" plot 'neurons.dat' using 1:10 title 'float' with lines, 'neurons.dat' using 1:11 title 'fixed' with lines set output 'tmp/rz.png' set title "RZ neuron" plot 'neurons.dat' using 1:12 title 'float' with lines, 'neurons.dat' using 1:13 title 'fixed' with lines set output 'tmp/tc.png' set title "TC neuron" plot 'neurons.dat' using 1:14 title 'float' with lines, 'neurons.dat' using 1:15 title 'fixed' with lines
and when checking through visually it mostly looks alright:
- Most neuron outputs look like they do in the paper, and the fixed and floating point implementations don't differ by much
- The fixed point implementation looks a little slower (the neuron's reaction speed, this isn't about processing speed) than the floating point one, but not horribly so.
- My IB implementations don't agree with each other, and neither agrees with what was presented in the paper.
- My RZ implementations agree with each other, but are always firing, unlike the RZ in the paper.
The end result here is a little mixed: The obvious way to implement this model (using floating point) would have taken about 210us per loop, and I've got it down to 7.2us per loop without too drastically affecting the readability of the code. This may seem like overkill (if it only needs to update every 200us, why bother?) but this frees up a lot of space to do other things like run complex sensors, calculate spiffy lighting, or even run multiple neurons on one microcontroller. On the flip side, I'm not sure why my IB and RZ neurons aren't doing well, and this is going to require me to dig back into the paper to understand what's really going on.
Here's the final code, I expect it to roll into the main repo soon, but you can also see my work on its own, frozen in time on my github page.
// XXX Note: if you change LOG_SQRT_FSCALE, you'll need to re-check the math
// XXX to confirm that it won't overflow, as well as play with those
// XXX constants when calculating `partial`.
#define LOG_SQRT_FSCALE 10
#define SQRT_FSCALE (1 << LOG_SQRT_FSCALE)
#define FSCALE (SQRT_FSCALE * SQRT_FSCALE)
static void base_i(ineuron_t *neuron) {
neuron->a_inv = 50;
neuron->b_inv = 5;
neuron->c = -65 * FSCALE;
neuron->d = 2 * FSCALE;
neuron->potential = neuron->recovery = 0;
neuron->scale = FSCALE;
}
void RS_i(ineuron_t *neuron) {
base_i(neuron);
neuron->d = 8 * FSCALE;
}
void IB_i(ineuron_t *neuron) {
base_i(neuron);
neuron->c = -55 * FSCALE;
neuron->d = 4;
}
void CH_i(ineuron_t *neuron) {
base_i(neuron);
neuron->c = -50 * FSCALE;
}
void FS_i(ineuron_t *neuron) {
base_i(neuron);
neuron->a_inv = 10;
}
void LTS_i(ineuron_t *neuron) {
base_i(neuron);
neuron->b_inv = 4;
}
void RZ_i(ineuron_t *neuron) {
base_i(neuron);
neuron->a_inv = 10;
neuron->b_inv = 4; // should be 1/0.26, we'll see if this is close enough
}
void TC_i(ineuron_t *neuron) {
base_i(neuron);
neuron->d = FSCALE / 20;
neuron->b_inv = 4;
}
void step_i(ineuron_t *neuron, fixed_t synapse, uint8_t fracms) {
// step a neuron by 2**(-fracms) milliseconds. synapse input must be scaled
// before being passed to this function.
if (neuron->potential >= 30 * FSCALE) {
neuron->potential = neuron->c;
neuron->recovery += neuron->d;
return;
}
fixed_t v = neuron->potential;
fixed_t u = neuron->recovery;
//fixed_t partial = (v / SQRT_FSCALE) / 5;
fixed_t partial = ((v >> LOG_SQRT_FSCALE) * 819) >> 12;
neuron->potential = v + ((partial * partial + 5 * v + 140 * FSCALE
- u + synapse) >> fracms);
//neuron->recovery = u + (((v / neuron->b_inv - u) / neuron->a_inv)
// >> fracms);
neuron->recovery = u + (((v - u * neuron->b_inv)
/ (neuron->b_inv * neuron->a_inv)) >> fracms);
return;
}
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.
#define SQRT_FSCALE 1024.. at least.
But better and readable is
#define SQRT_FSCALE (1<<(24/2)) // use "1.7.24" fixed point format ("1sign.7integer.24fractional" parts bit counts)
Are you sure? yes | no