 ventosus
ventosusThe freeader will be designed to load prerendered text as bilevel (1 bit per pixel) image data.
Considering an image size of 800x600 pixels, this gives a raw storage size of (800*600/8=60kB) per page.
To safe space on the SD card and to speed up loading of pixel data from the SD card by the uC, we'd like to compress the pixel data if possible.
The following questions arise thereby:
- Are there special compression algorithms for bilevel text documents?
- Are there decompression algorithms suitable to run on a uC?
So, let us compare some widely used compression algorithms to the raw image data (pbm)
- LZO (https://en.wikipedia.org/wiki/Lempel–Ziv–Oberhumer)
- CCITT Group 3 (https://en.wikipedia.org/wiki/Modified_Huffman_coding)
- CCITT Group 4 (https://en.wikipedia.org/wiki/Group_4_compression)
- GZIP
- BZIP2
- XZ
- JBIG1 (https://en.wikipedia.org/wiki/JBIG)
- JBIG2 (https://en.wikipedia.org/wiki/JBIG2)
The CCITT*, and JBIG* are special compression algorithms for bilevel image data (FAX, scanned documents).
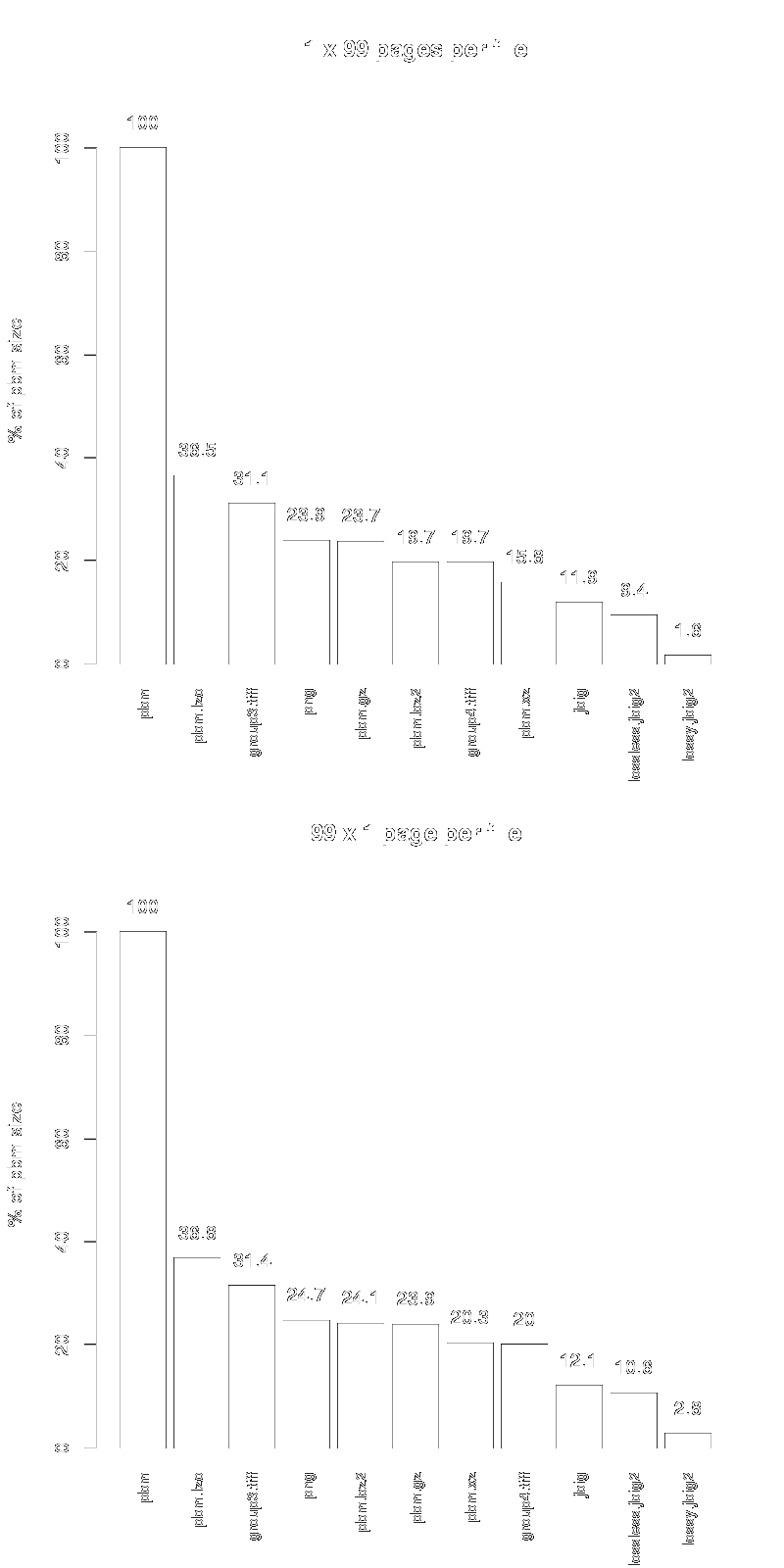
I use two cases for the comparison, in each one I have compressed the first 99 pages of 'Flatland'. Once all pages appended into a single image, and once each page on its own.
From the figures below, you can clearly see, that the JBIG* algorithms perform best. Only the Group 4 version of the CCITT compression may be suitable, though.
So, which one of CCITT Group 4, JBIG1 and JBIG2 whould we use on the uC to decode image data?
This is a matter of available libraries, computational cost and memory usage. Ideally, a given decompression algorithm should not use any dynamic memory and would be designed with a byte stream API, e.g. read some bytes of compressed data until a complete image line has been decompressed, update the decompressed image line on the display, read next chunk of compressed bytes from SD, ...
Are there any free decompression libraries out there:
CCITT: http://www.libtiff.org/, ftp://alpha.greenie.net/pub/mgetty/tools/viewfax-2.4.tar.gz
JBIG1: https://www.cl.cam.ac.uk/~mgk25/jbigkit/
JBIG2: http://www.ghostscript.com/jbig2dec.html
There is no standalone library for CCITT compression, but the algorithms could be extracted from various projects (libtiff, imagemagick, gimp, viewfax). CCITT compression is lightweight, can be implemented with a byte stream filter design and would thus be readonable to be run on a uC. But I would need to write the filters from scratch for usage on uC.
There is a library for JBIG1 compression/decompression, it uses only ~4kB static memory, uses no dynamic memory, has a byte stream API and is optimally suited to be run on a uC. It can directly be used on a uC.
There are separate projects for JBIG2 compression/decompression. The decompression library needs a lot of memory, as whole pages need to be present in memory (no byte stream filter design). It would need to be migrated to a a byte stream API design to be usuable on a uC. The JBIG2 compression has a lossless and lossy mode. The lossless mode is similar to JBIG1, the lossy mode can reach much higher decompression rates (but it needs a lot of memory).
We obviously have a winner, it's JBIG1, as it has a readily available library with a byte stream API design, uses little static memory only and offers very good compression (10%).
I will need to test the algorithm on a real uC, though, to find out how computationally expensive it is...
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.