 Dhruv Joshi
Dhruv JoshiThe machine learning system on cloud was working well on the website theia.media.mit.edu - our goal is to integrate this into the device via API, so that whenever someone takes images they can choose to grade it by sending it on cloud. The natural limitation of this is that the user needs access to the internet, which may not be available in remote areas, and so we would eventually have to move the processing of images onto the raspberry PI itself. At the present moment, for a proof of concept we would use the cloud-based system.
This is written in python as a seperate module, with a function grade_request() that is callable, with the filename supplied as an argument. The API takes a multipart form, in which we send the file object (C-style, returned by open() in python) using the requests module. The API request requires a unique token which is generated by the website - this would help us identify the institution/device making the request.
The server returns a 200 reponse, and a JSON object containing the grade as a float (from 0.0 to 4.0). To test it out, the following table surveys a few test images and their responses from the server:
| Image | Grade |
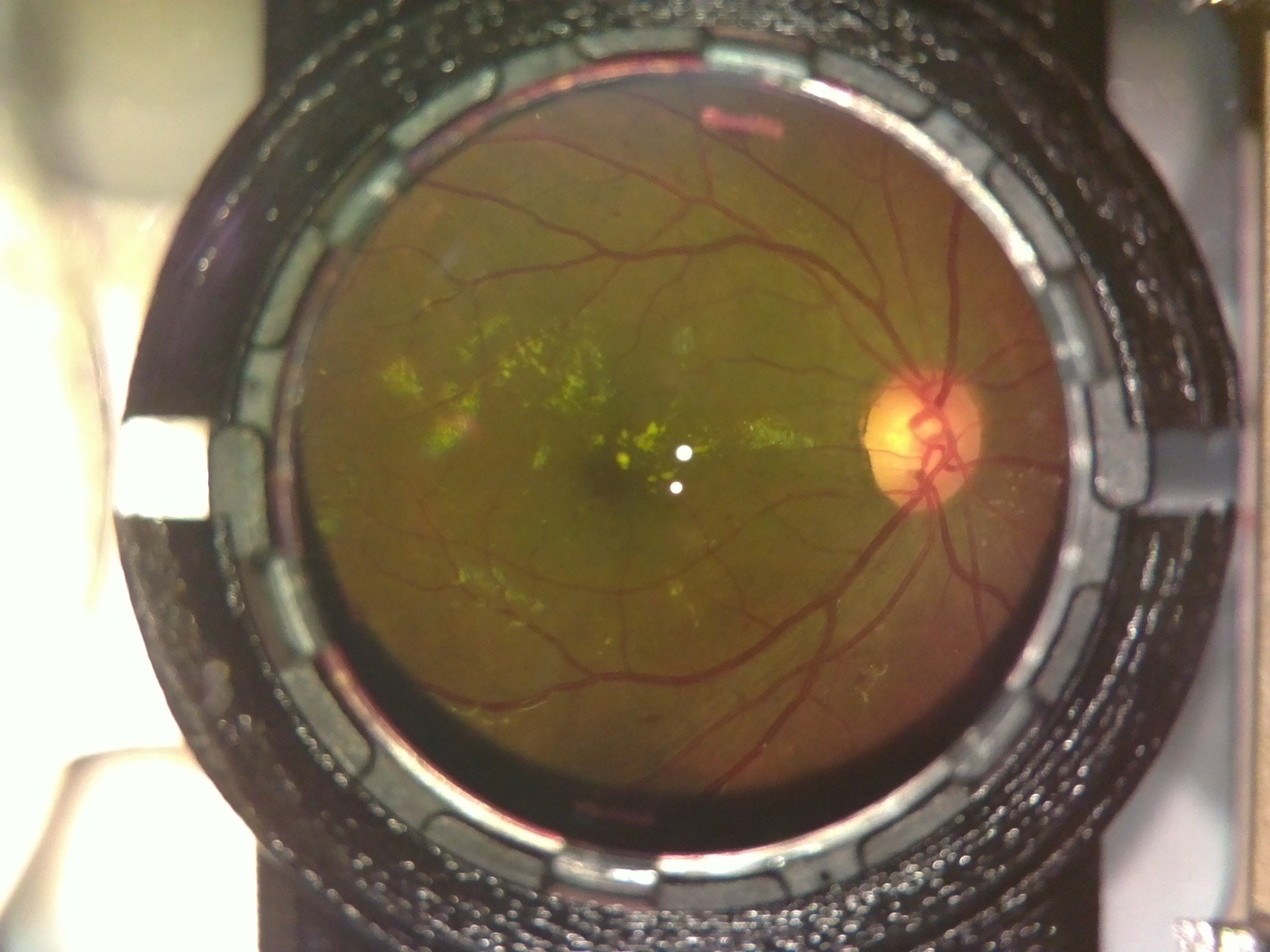 | 2.08 |
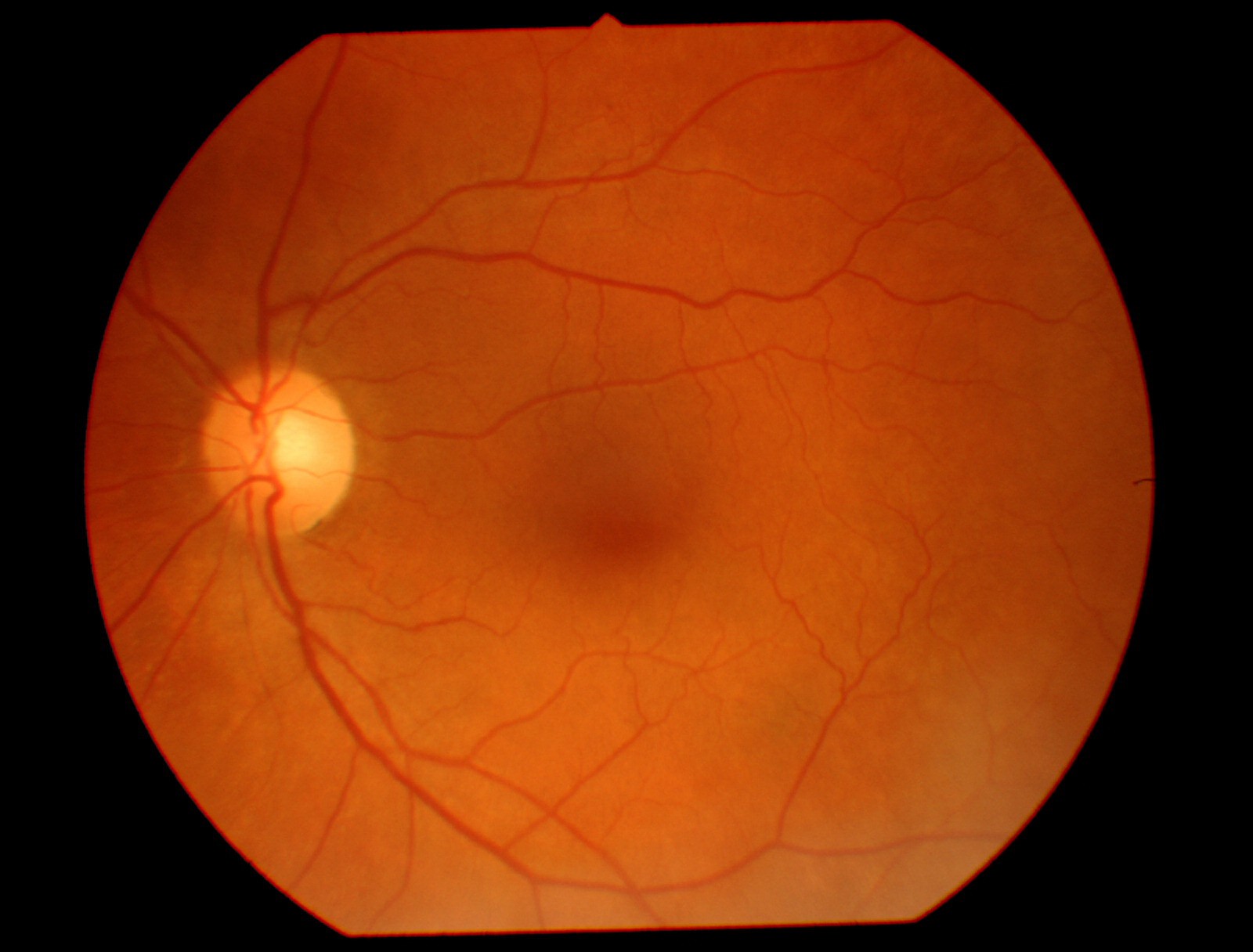 | 0.09 |
 | 0.13 |
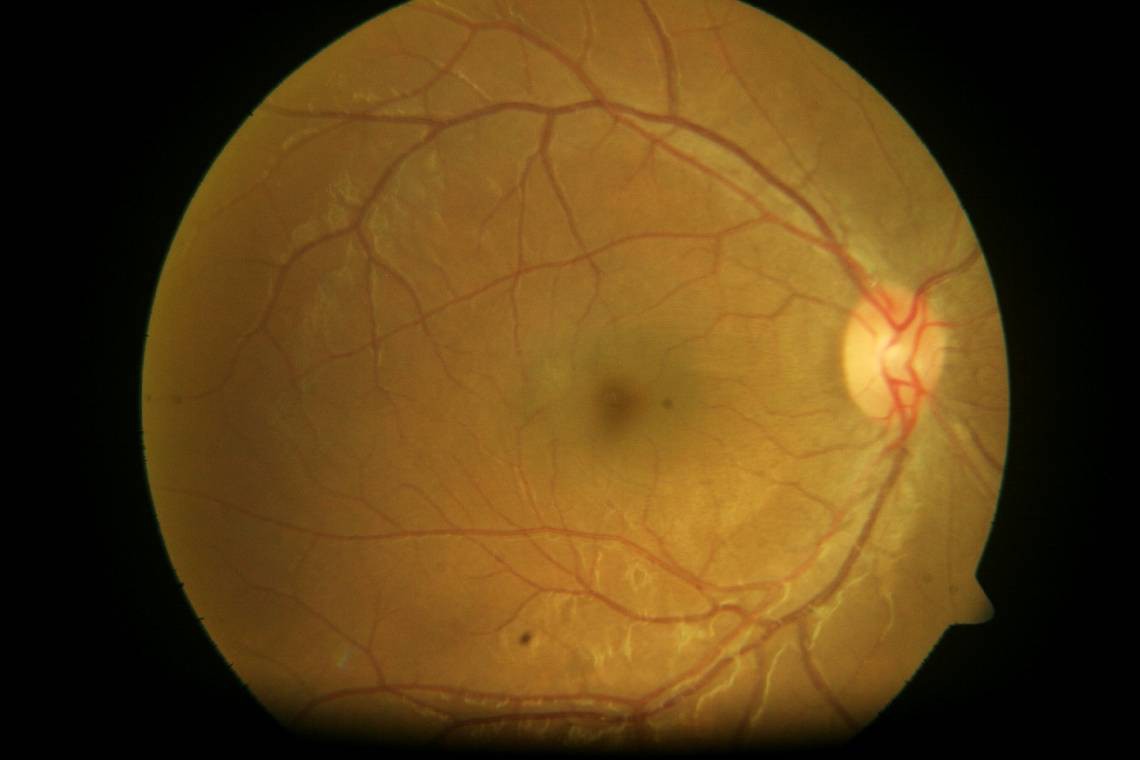 | 0.33 |
 | 0.08 |
 | 2.27 |
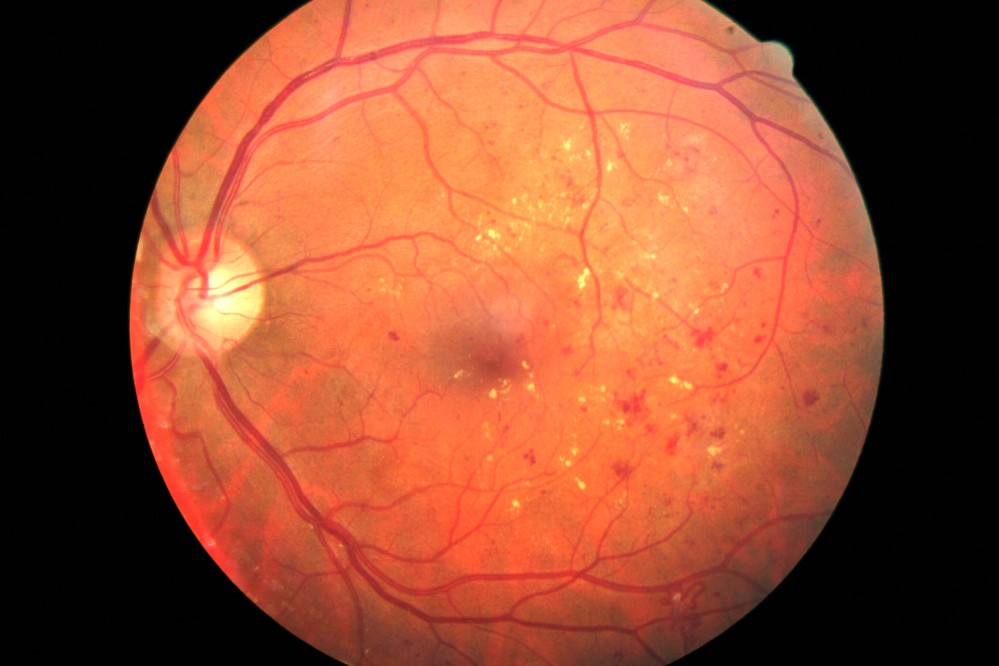 | 3.08 |
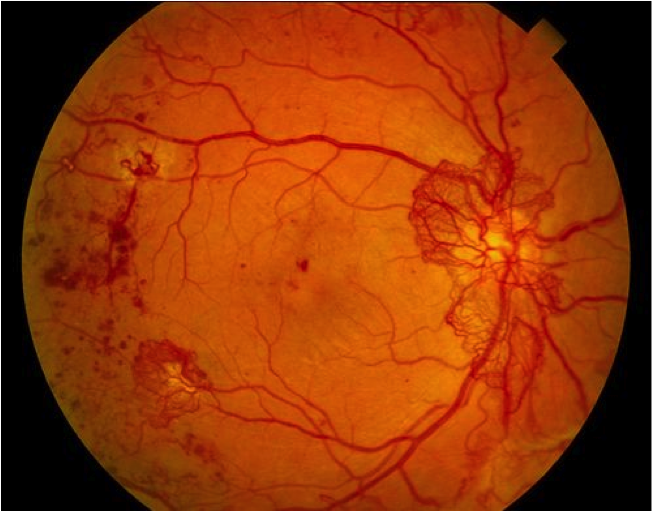 | 2.43 |
As can be seen, even the first image, which had a lot of noise (i.e. non-retina artifacts like the lens holders and other parts in our device which had not been computationally removed) gave a result which matched fairly well with what we would expect. The algorithm was robust enough to not be confused by the whitish streaks as well as the black dots (artifacts - usually dust on the camera or lenses) in the 4th image, correctly labelling it within the healthy bracket (less than 1.0).
These tests worked quite well on high-quality images from fundus imaging devices in the clinic. We would like to evaluate the performance of this system on images taken by our device. For this we need to convert our images into a format which is similar to what the clinical standard devices would output - which would start by understanding the limitations in our device's imaging capabilities. The fundamental differences between OWL images and fundus images are:
- The glare spots at the center - these would be removed by the computational inpainting method described earlier.
- Our device's images are limited to 30 degree field of view (FOV) - which need not be central. This is not a major limitation as this FOV gives enough information for a nonspecific retinal examination.
- Our images would have radial distortion due to the 20D lens and the M12 camera lens of the raspberry PI. This would result in slightly different edge distortions compared to a traditional fundus imaging device. To a human examiner, this would make little difference - but to the machine learning algorithm, this may have a non-negligible effect which we would have to investigate.
Point (1) would have the greatest effect on the DR score - since the white spots may be confused by the algorithm to be due to DR. The following table shows the scoring at different stages of processing:
| Image | Process performed | Grade |
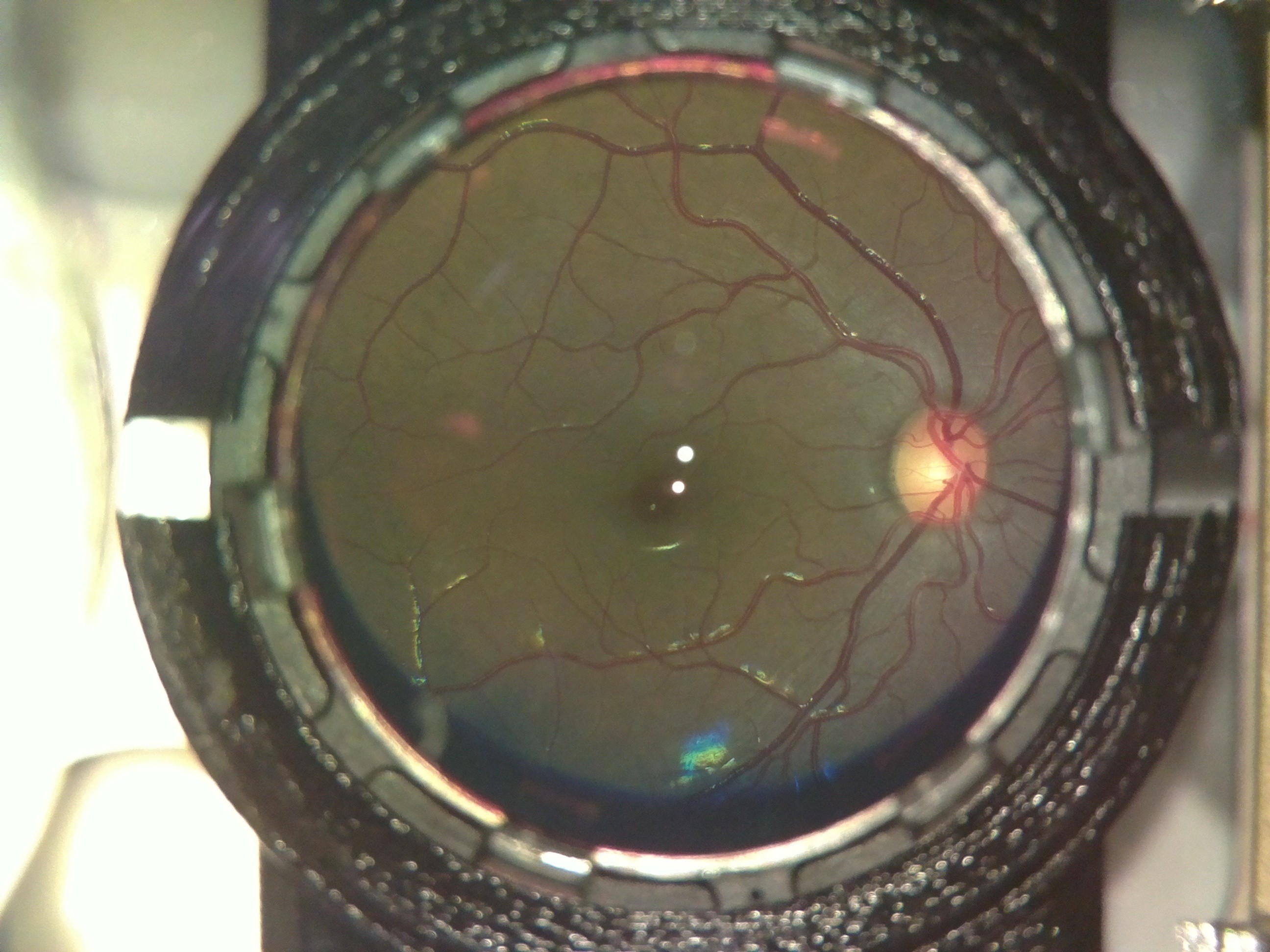 | None (raw image) | 0.15 |
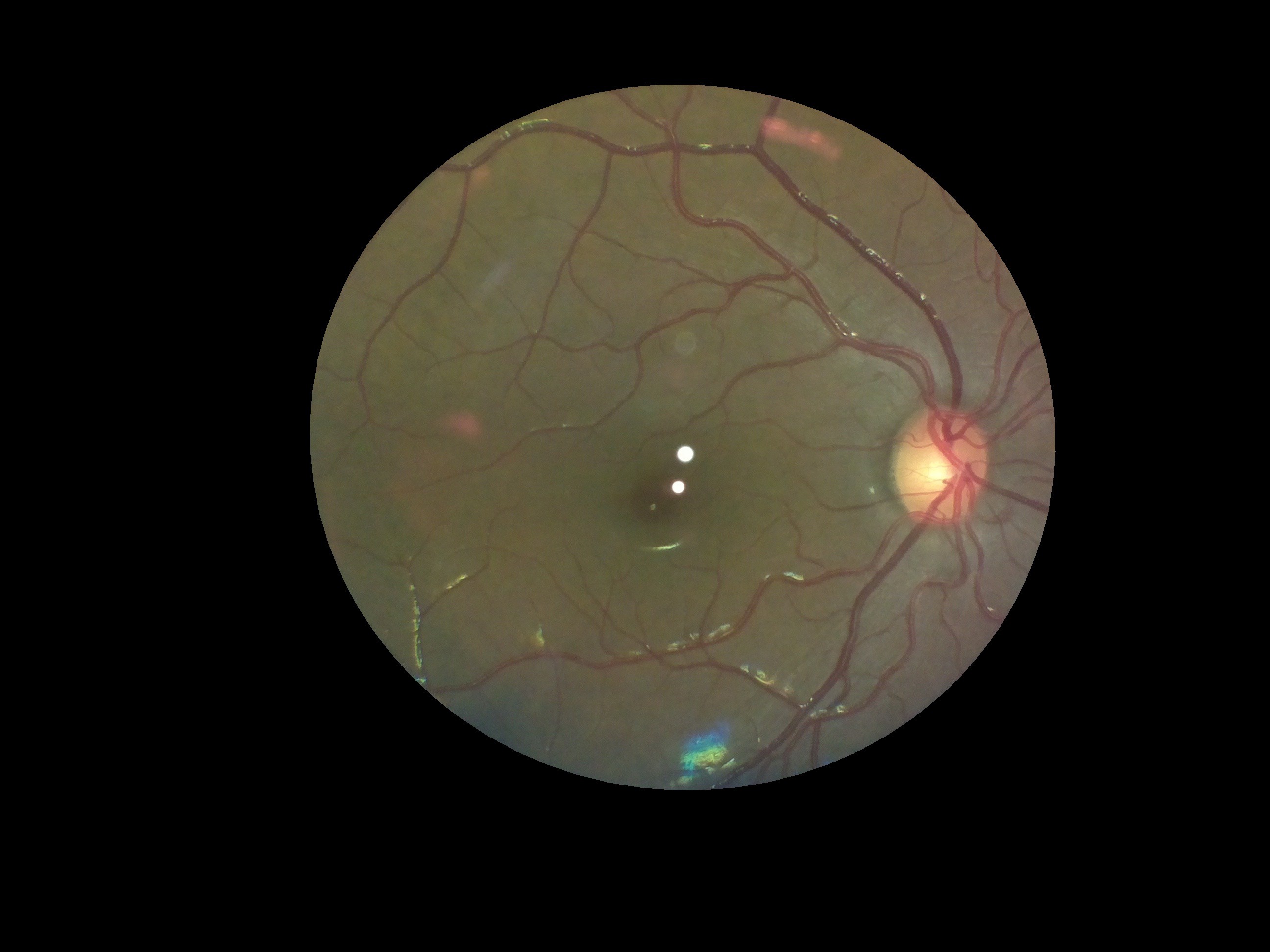 | Extracted the fundus from the background | 0.12 |
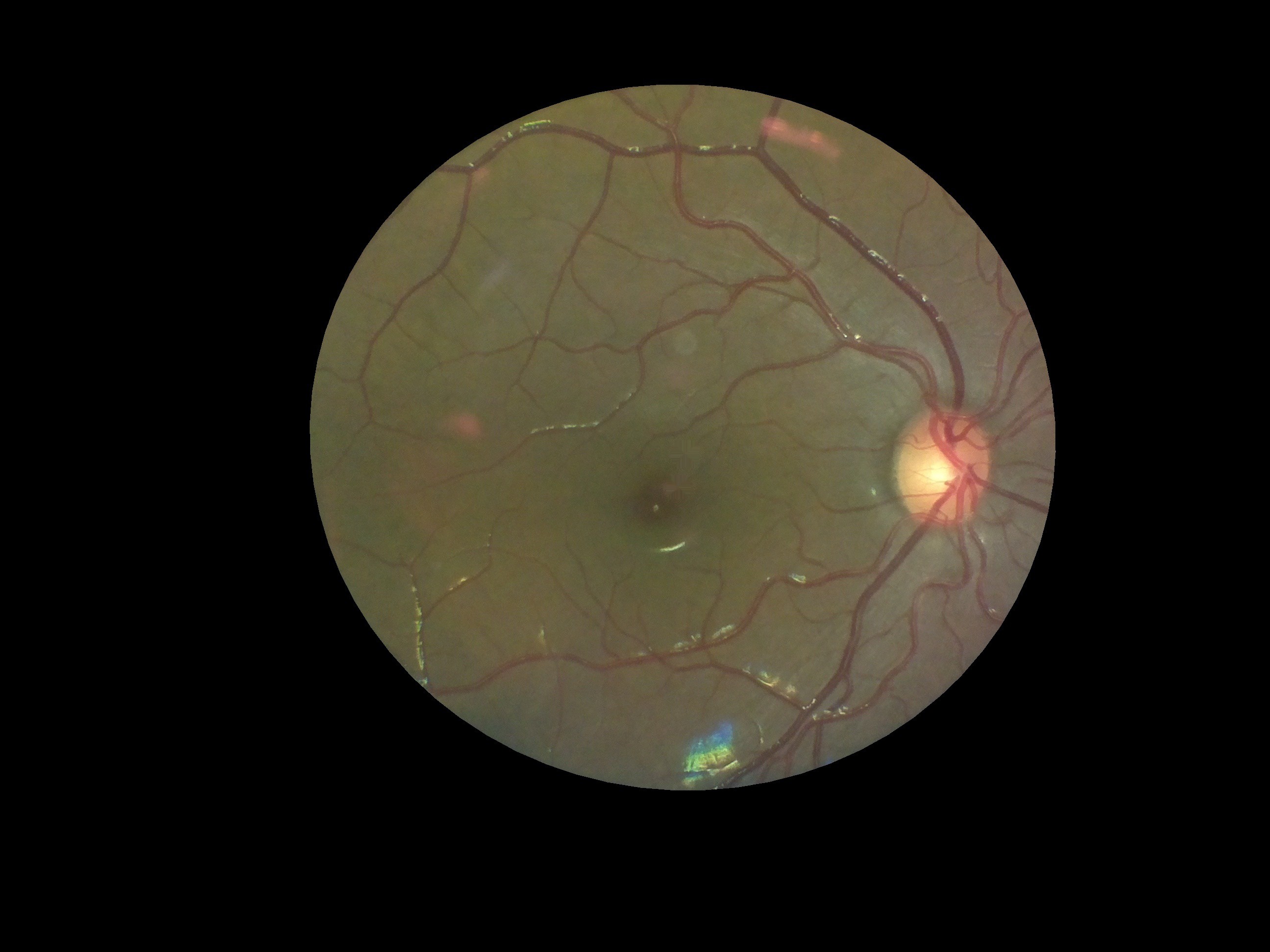 | Removed the glare from the image | 0.16 |
Interestingly, there was very little variation between the three images as far as scoring by the algorithm was concerned. However, we would need to conduct a large study on patients and healthy volunteers comparing images from our device and from clinical standard devices to really quantify how closely in agreement the DR grading is. However, for the purposes of a first stage screening device, the automation system broadly classifies images quite well.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.