We began with a simpler task: voice synthesis, as this task is solved by many vendors. In 1984 Steve Jobs surprised everybody at his Macintosh presentation when the first Mac started speaking.
We did not have any problems with the selection of the speech synthesis modules. They all work well and have a wide choice of voices.
Finally, we used the standard Microsoft SAPI. This product with various language sets is distributed free of charge.
As for the image recognition, the task here was more complicated, as we needed not just to recognize a face or an object but to recognize it in the streaming video going from the camera. The choice of the resources used by the program is very important. It does not matter for a computer but does matter for a tablet, as the program should work efficiently and should not slow or stop the system.
For this solution we used the OpenCV library. To speed up the work, any face of a certain size in the camera field vision is searched for. The search is done with the help of Haar cascades and the ready trained template from the OpenCV library.
A detected face is cut out, normalized (unified) in size and light, and reproduced in black and white.
After that a ready FaceRecognizer algorithm, trained on a number of images of the same face taken from different angles, is used to recognize a certain person.
Now let’s go to a more complicated part – voice recognition.
Here we have spent 90% of our labor and should admit that only now we are fully satisfied with the result. We tried to use ready Open Source solutions.
Unfortunately, 99% of these solutions are either not free or poor. That is, if you say “Manchester” the system hears “Liverpool”. We had to choose and try various words and combinations.
Thus, a well-known Open Source Sphinx works off-line and has all the necessary tools, but it takes much time to train it to get more or less acceptable level of recognition.
At the end we chose Google Speech API, which maintains not more than 50 recognitions a day (about 15 minutes of the recognition process). It’s enough for a demo.
The Google program has a good quality of recognition. It works even at the distance of a few meters.
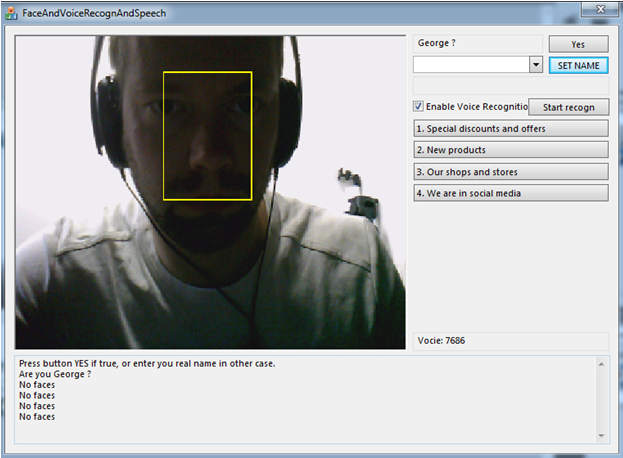
So, how does the program work?
The first thing the program does when activated is to detect a face in the field of camera vision. If it sees the face for the first time (it is not found in the database), it asks to enter and save the name. After that the program will always recognize this face.
Then the program switches to the mode of speech recognition: pronounced words, sentences or commands. As soon as the program recognizes a phrase, pronounced be a person, it looks for an adequate answer in the database and voices the answer. It is necessary to put all possible answers into the program beforehand for the program to know what to say. So far, it looks like a simple text file.
| ( | Tim = Good afternoon, Tim. We welcome you at our conference. Steve = Thank you for coming, Steve. You will be now welcomed. Have a nice day! 35310204 = Your credit repayment is due before the 30th day of the following month. | ) |
This is not about an artificial intellect. This is about an interface for image and speech recognition and speech synthesis.
So, what possibilities do this program and the interface open? It is possible to use them for development of a certain robotic platform. This kind of platforms exists nowadays as electronic kiosks.
As we see it, this program will look more elegant if used together with our DIY SelfieBot.
Let’s consider theoretical options of the platform application
1.Conference registration counter SelfieBot
- Conference registration counter SelfieBot
- Virtual secretary SelfieBot
- Self-service terminal SelfieBot
- Shop assistant SelfieBot
- Robot-waiter SelfieBot in a café/restaurantе
Problem to be solved: reduction of conference staff costs.
Task: Support of conference visitors and guests with a user-friendly interface for automatic online registration.
Solution:...
Read more »

 WalkerDev
WalkerDev
 Kenny.Industries
Kenny.Industries
 Swaleh Owais
Swaleh Owais