 Ryan Kinnett
Ryan KinnettDISCLAIMER:
This post summarizes my piecemeal, spotty, experimental, and in some cases probably incorrect understanding of the methods described herein. This was all new to me before this project, and it still is, so don't take anything here as gospel.
About Frequency-Shift Keying (FSK)
Key characteristics of FSK are two discrete audio tones representing "marks" and "dashes", aka binary ones and zeroes, with smooth transitions between tones. FSK is a non-returning-to-zero (NRZ) type encoding method, meaning each bit is explicitly represented by one frequency or another, as opposed to representing zeroes as lack of signal. 300-baud FSK (aka Bell 103 standard) is common on HF (SSB). In this mode, an audio signal is composed of a continuous sine wave in which the frequency varies smoothly between two arbitrary frequencies, separated by 200 Hz, representing a stream of ones and zeroes at 300 symbols per second. The modem injects this audio stream into a mic port of an HF transmitter which mixes the pre-modulated AF signal and transmits as SSB. 1200 bd FSK is more common on VHF (FM). 1200 bd packet uses 1200 Hz and 2200 Hz tones representing ones and zeroes, respectively, per the Bell 202 standard. Note that this peculiar selection of tones avoids aliasing but also slightly complicates the process of digital demodulation. Also note that the baud rate matches the frequency of the lower tone, meaning that just one single cycle of 1200 Hz tone fits within each symbol period - this turns out to be a driving factor in which tone differentiation methods can be used.
9600 baud is also possible, but requires a compatible radio which gives the modem direct control of the RF modulator, and even higher symbol rate modes are built on top of that.
This project will initially focus on 1200 FSK since I currently only have access to VHF/UHF radios without modulator ports.
By the way, for context, FSK is one of several physical-layer modulation techniques used to encode digital data into audio frequency and ultimately RF. The content of that digital data is coordinated between the link and application layers. My primary use case for this project is to support Winlink for emergency comms, using the ESP32 either as a KISS TNC or as an audio relay. In both of these modes, link layer coordination is handled by software on the PC and there is no need for the modem to implement higher-order protocols (AX.25). However, I am also interested in supporting APRS, which probably will require onboard link control and AX.25 packetization. In any case, my main point here is to explain the origin of the digital data that's going through FSK modulation and demodulation. We will deal with link control infrastructure and packetization later.
----
Pulling bits out of the air
There are several ways to approach FSK demodulation, each with different levels of capability and resource requirements.
The Fast Fourier Transform (FFT) is more or less the go-to method for differentiating between frequency components in a digitized analog signal for many, miscellaneous applications throughout engineering. That said, the FFT is not particularly well suited for embedded FSK demodulation. The FFT calculates energy in discrete frequency bins between zero and Fs/2, and these calculations are intertwined and inseparable. Since we're only interested in two specific frequencies, most of the information generated by the FFT would be thrown away. Further, FFTs are typically evaluated in adjacent, non-overlapping sample windows, with no information carried over from one window to the next. Additional layers of complexity could work around these issues but generally would not be practical on an embedded microprocessor, even on one as capable as the ESP32.
The next step closer is the Goertzel Algorithm which is more ideal for calculating energy in specific frequencies. This method requires complex number math which is well supported in C and on the ESP32. The method itself appears to be fairly simple, but for whatever reason, I couldn't seem to get it to produce meaningful signal in numerical simulation, after days of trying. I'm sure it's just one little detail I missed. Update: I was able to get this method working, but I'm finding that it's severely constrained by the short window that I have to use in order to discern changes at 1200 baud. Basically, at 26400 Hz sampling frequency, just 22 samples span each 1200 Hz cycle (the symbol rate at 1200 baud). The frequency resolution of this method is dF = fs/N = 26400/22 = 1200 Hz, which is terrible for this application, given that I'm trying to differentiate between tones that are separated by only 1000 Hz. I'm basically locked into this property because I can't extend the Goetzel evaluation window wider than one 1200 baud symbol period. I can't just double sampling frequency because then I would have twice as many samples per 1200 baud period, resulting in the same ratio and same frequency resolution. This interpretation is born out by experimentation described below.
I also experimented with a related approach, the Sliding Discrete Fourier Transform. Similar to the FFT, the Sliding DFT transforms time-domain series of measurements into the frequency domain, yielding an energy spectrum across a range of discrete frequency bins. The Sliding DFT is significantly less computationally complex than the FFT, and it also has an advantage of evaluating with each sample rather than in non-overlapping windows, reducing latency and improving efficiency by reusing previous calculations. I tried several times to code it myself in various forms, then tried and found success with this SlidingDFT library by Bronson Philippa. Here is a test I produced in C, using the SlidingDFT against simulated ADC data representing a random series of 31 bits, overlaid with gaussian noise, with SNR 2:1. I chose a sample frequency of 26400 Hz which is an even multiple of both 1200 Hz and 2200 Hz, and a window of 22 samples which corresponds to one 1200 bd symbol period. This method provided good discrimination between 1200 Hz and "not 1200 Hz", but the 2200 Hz harmonic was indiscernible. The magnitude plot shows a reasonably smooth signal, with no additional low pass filtering needed, and the signal is sharp-edged enough to pick up solitary ones and zeros. This is very promising!
After flailing a bit with the Goertzel algorithm, and before finding success using Philippa's SlidingDFT library, I had just about given up on these canonical methods and had worked out another numerical approach that also seems robust and less computationally complex. I haven't found any documentation of a similar method, but I wouldn't claim to have invented anything here. (EDIT: this method is called a comb filter and is similar to a time delay correlator). The general approach is as follows: for each new sample x[n], subtract the sample that came 180 deg ahead of the current sample if the current tone is 1200 Hz, and take the absolute value of that difference. With 26400 Hz sampling rate, the period of each 1200 Hz cycle is 22 Hz, so for this step, subtract the sample received 11 samples ago. This makes a rectified 1200 Hz "resonator" (my terminology), call it "R1200". Average across the last 1200Hz half-period (11 resonator values in this case) to smooth this out, and call this "S1200". Do the same for 2200 Hz tone. Calculate "envelope" as sum of S1200 and S2200. Calculate differential "Diff" as difference between S1200 and S2200; this will be used with a threshold to differentiate between 1200 and 2200 Hz tones.
- For each new sample x[n]:
- R1200[n] = abs(x[n] - x[n-11])
- S1200[n] = average(R1200[n-11:n])
- R2200[n] = abs(x[n] - x[n-6])
- S2200[n] = average(R2200[n-3:n])
- Env[n] = S1200[n] + S2200[n]
- Diff[n] = S1200[n] - S2200[n]
This approach which I stumbled upon experimentally looks very promising, but it's touchy. There are a lot of knobs to turn, each with its own advantages and disadvantages. More filtering, for example, cleans up noise-induced transients, but it also flattens out legitimate peaks which makes the method more prone to synchronization issues. It's not guaranteed that I'll find an appropriate balance between these competing effects. UPDATE: I found this method to be susceptible to noise because each correlator step evaluates just 2 source samples, whereas some methods look for correlation in all samples within a moving window. Further, this method is sensitive to differences in amplitude between the 1200 Hz and 2200 Hz segments, which is expected to be a real problem with some radios due to audio frequency emphasis/deemphasis filtering.
Simulation
I built a somewhat high fidelity numerical simulation in google sheets, of all places. It simulates a brief period of background noise, followed by a stream of 31 random ones and zeroes which are FSK modulated, then I add random noise, some clipping and scaling to mimic the ESP32 ADC range, then the demodulation steps. The signal and noise are scalable, and I made macros to resample the random bit patterns and signal noise so that I could test the demodulation methods against hundreds of combinations of signal and noise values and relative amplitudes.
Here is a snapshot from just one run:
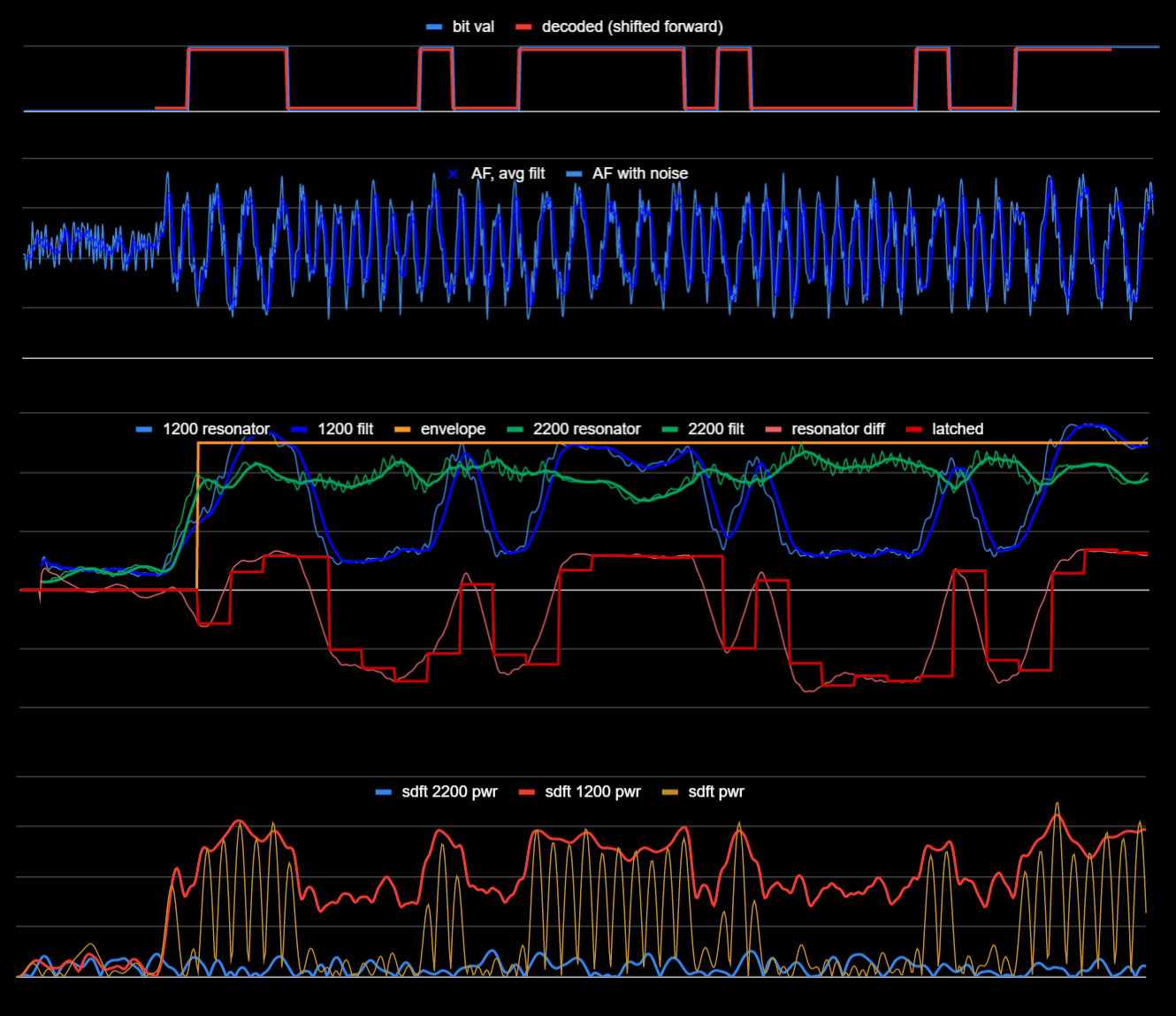
- The top plot shows the random bit pattern in blue, with the (eventually) decoded bit pattern (via time delay correlator method illustrated in third plot) in red.
- The second plot shows the FSK modulated signal with simulated noise (SNR 2:1).
- The third plot shows the 1200 Hz and 2200 Hz resonators, smoothed, the difference between them, and latched values from that differential, used directly for comparison to a threshold (near zero) to interpret decoded bits.
- The fourth plot shows results from the SlidingDFT library. The 2200 Hz trace is virtually unusable, but the 1200 Hz trace shows very clear, usable signal. The "sdst pwr" trace shows the 0th DFT entry which might also be useful for enveloping and discrimination.
Update:
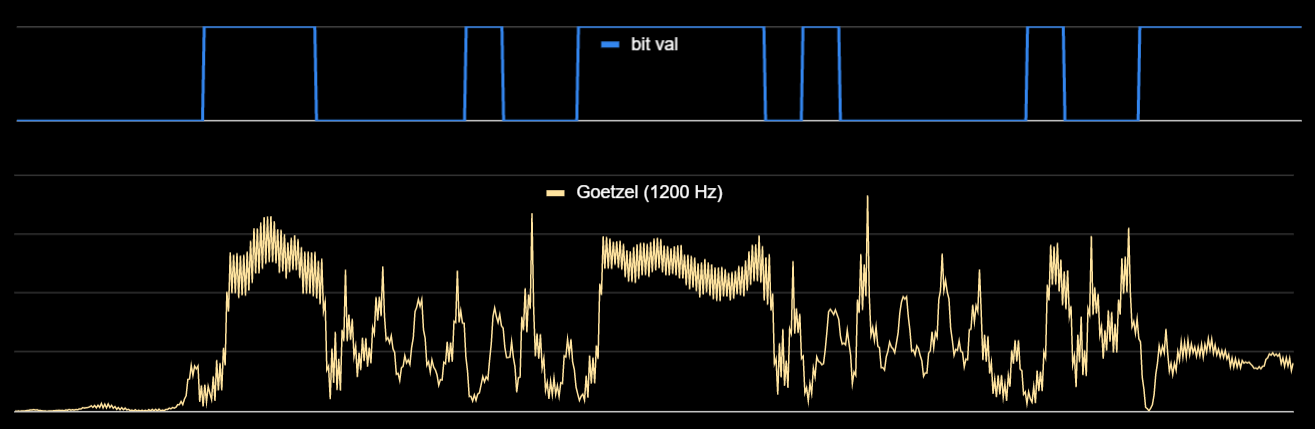
I also experimented with the Goertzel algorithm across the same simulation data. This method produced a signal that roughly correlates with the 1200 Hz periods of the source bit pattern (the 1's), but it also oscillates during the 2200 Hz periods (the 0's), with peaks well past where I would want to set a threshold for the 1200 Hz signals. I believe this is an aliasing effect, due to the fact that 2200 Hz is "not far" from the second harmonic of 1200 Hz, considering the 1200 Hz frequency resolution of this method. I could conceivably take advantage of that oscillation by multiplying the signal by a copy of itself, phase lagged by half of a 2200 Hz period. This would leave the steady plateaus correlating to 1200 Hz and would attenuate the oscillations corresponding to 2200 Hz, and the smoothing this would introduce would only stretch about 1/4 (6/22 to be precise) of the baud period. For this simulation, I cut the noise down to SNR 4:1 and applied a 3-sample averaging filter to the raw samples before calculating Goertzel magnitudes. I don't know, this might work, but it would take some additional creative post-processing to make this usable.
Another Update:
Reading further, I came across a nice writeup by Bernard Debbasch about how he implemented FSK demodulation as part of an ARM-based answering machine project. His approach passes the audio signal through what, in concept, could be considered to be tuned oscillators, implemented as sets of sine and cosine values at each of the pattern frequencies, 1200 Hz and 2200 Hz. He samples at 9600 Hz, providing 8 samples across each 1200 bd cycle. At each 9600 Hz time step he convolves the latest 8 samples with the sine and cosine series and sums these products. The cosine series represent the imaginary component of the signal and resonates when the source signal phase angle is near 90 and 270 deg. The sine series represents the real component of the signal and resonates with either the 1200 Hz series or 2200 Hz series when the phase is near 0 or 180 deg. RSSing the real and imaginary components yields the magnitude of the signal. This approach produces a clear and relatively stable correlation with each filter. Subtracting the outputs of the two filters makes it very easy to differentiate between 1200 Hz and 2200 Hz segments of the source signal.
(Fs=9600Hz, SNR=2)
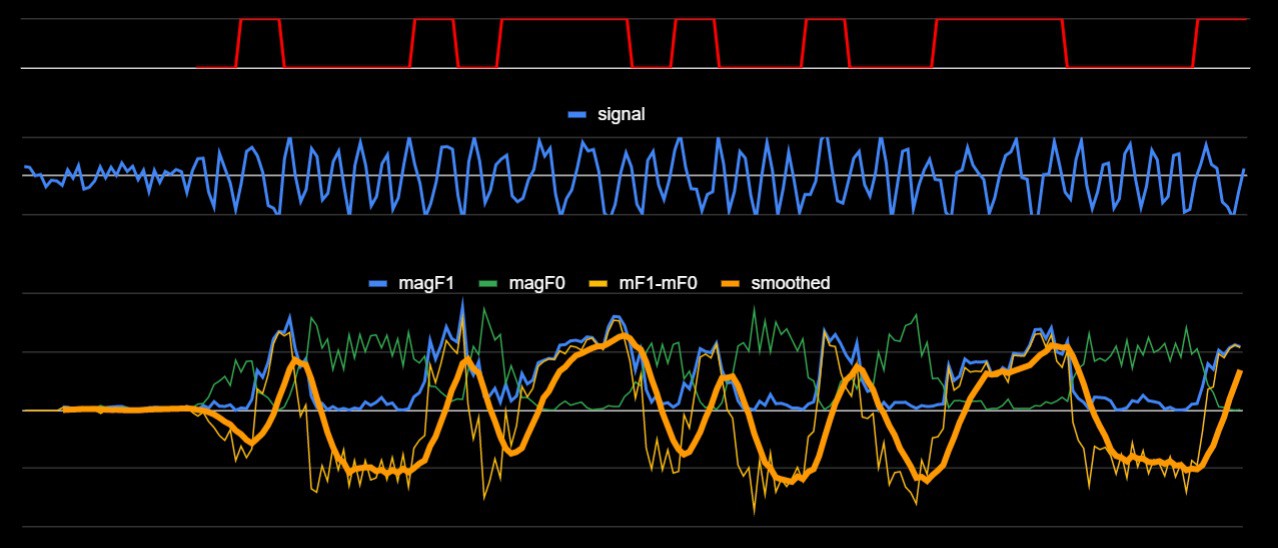
In the bottom chart, I overlaid a windowed average of the 1200 Hz magnitude minus 2200 Hz magnitude difference signal to smooth it out, but that's not really necessary. One can simply check the sign of the unfiltered difference signal. This approach works very well at 9600 Hz. There are several other references to this relatively simple and seemingly robust method, implemented on various older micro-processors. The ESP32 would eat this for breakfast.
Okay one more update then I'm done
Shout out to fellow CalPoly alum Robert Campbell. I ran across his thesis, "Analysis of Various Algorithmic approaches to Software-Based 1200 Baud Audio Frequency Shift Keying Demodulation for APRS" long after I dove into this exploration of FSK demod methods. It was useful to read his analysis and comparison and roughly validate some of my own findings.
Conclusion:
The Sliding DFT, time delay correlator, and tuned filter methods are very promising. Need to try each on hardware and see which is most reliable. With the time delay correlator method, I'm finding bit error rates on the order of 3%. I'm not sure if that's good enough. Update: the Goertzel method also appears to be viable, but seems to produce a more chaotic signal and is relatively complex and does not specifically target my frequencies of interest. I'll keep it mind, but I'm more inclined to start with the other three methods before this one.
Next step: start experimenting with FSK demodulation on the ESP32
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.
Very interesting write-up and thanks for mentioning my name (in a positive way!). One important aspect of AX.25 is that the packets are sent in synchronous frames but it is built on top of a transmission mechanism which is normally used in asynchronous transmissions (Bell 202 most common usage is for for caller ID which carries asynchronous data). The FSK decoding method I selected (and apparently you as well) makes it easy to find the symbol transitions. Interestingly, after working on the article you mentioned I also attempted to decode AX.25 and found that the algorithm was working quite well. I will contact you directly to share some ideas I have around your project.
Are you sure? yes | no