 lion mclionhead
lion mclionheadIn the field, efficientdet_lite0 was vastly superior to face tracking. The mane problems were trees & skeletal structures.








Trees are the lone bigger problem than face tracking. A higher camera elevation or chroma keying might help with the trees.

Face tracking couldn't detect lions from behind.

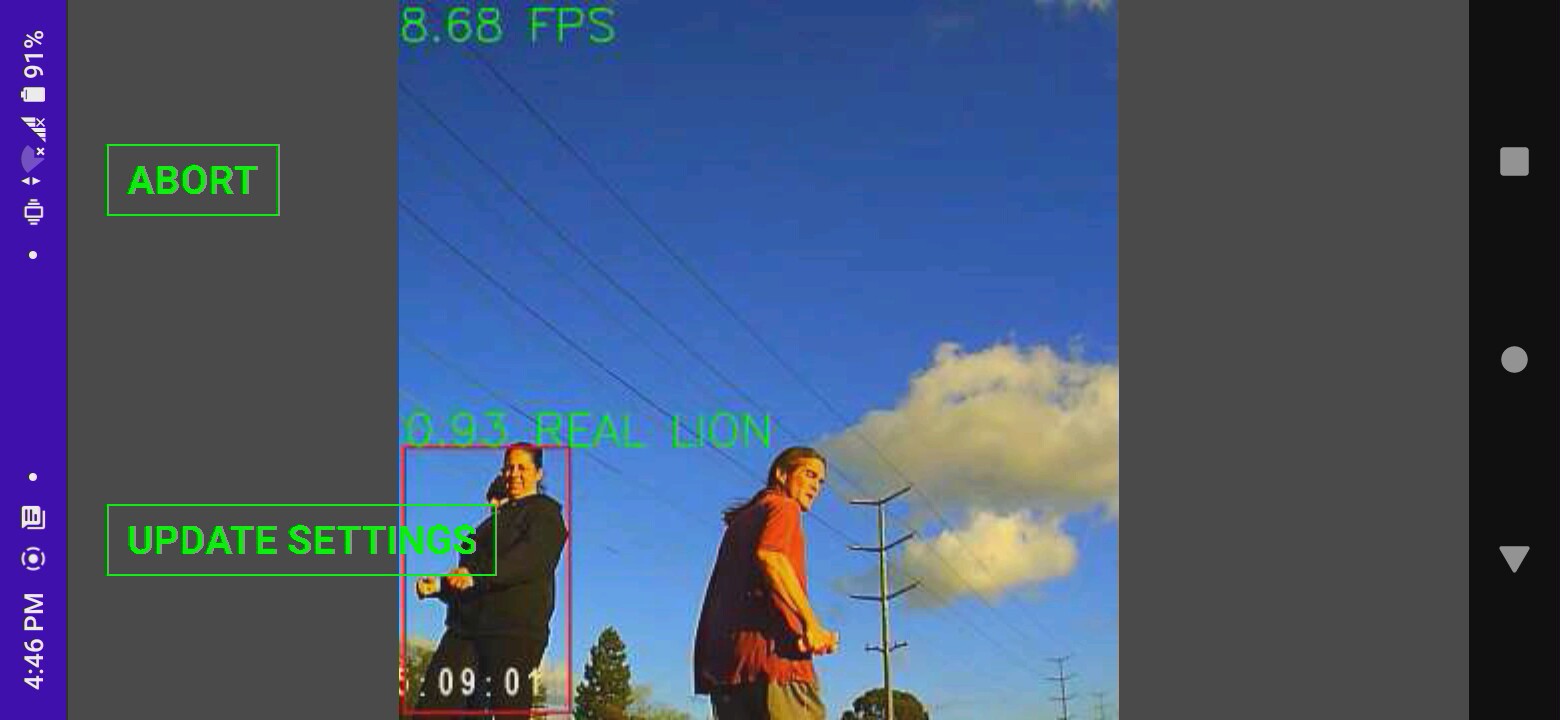
Multiple animals were as bad as face tracking.

It definitely coped with back lighting better than face tracking.

Range was limited by that 320x320 input layer.

Most footage with an empty horizon had the lion in the high .9's, but there's little point in having nothing else in frame.
The leading idea is labeling a video of lions with YOLOv5 & using this more advanced detection to train efficientdet_lite0. There's trying a FFT on the detected objects & making a moving average of the lion's average color. Trees should have more high frequency data & should be a different color.
Sadly, there's no easy way to get rid of the time stamp on the 808 keychain cam. Insert an SD card & it automatically writes a configuration file called TAG.txt. The file can be edited to remove the time stamp: StampMode:0 The problem is if the SD card is in the camera during startup, the raspberry pi detects the camera as an SD card instead of a camera. You have to tap the large button on it after booting to change mode. There's no indication of what mode it's in other than a long delayed message on the truckcam app.
Armed with 35,000 frames of lion video, the easiest way to label it was the pytorch installation formerly used to train YOLOv5.
https://hackaday.io/project/183329/log/203055-using-a-custom-yolov5-model
It actually has a detect.py script which takes an mp4 file straight from the camera & a .pt model file.
Yolov5 in pytorch format is downloaded from:
https://github.com/ultralytics/yolov5/releases/tag/v6.1
There are various model sizes with various quality. It begins again with
source YoloV5_VirEnv/bin/activate
python3 detect.py --weights yolov5x6.pt --source lion.mp4
The top end 270MB model burns 1.9GB of GPU memory & goes at 10fps on the GTX 970M. It puts the output in another mp4 file in runs/detect/exp/
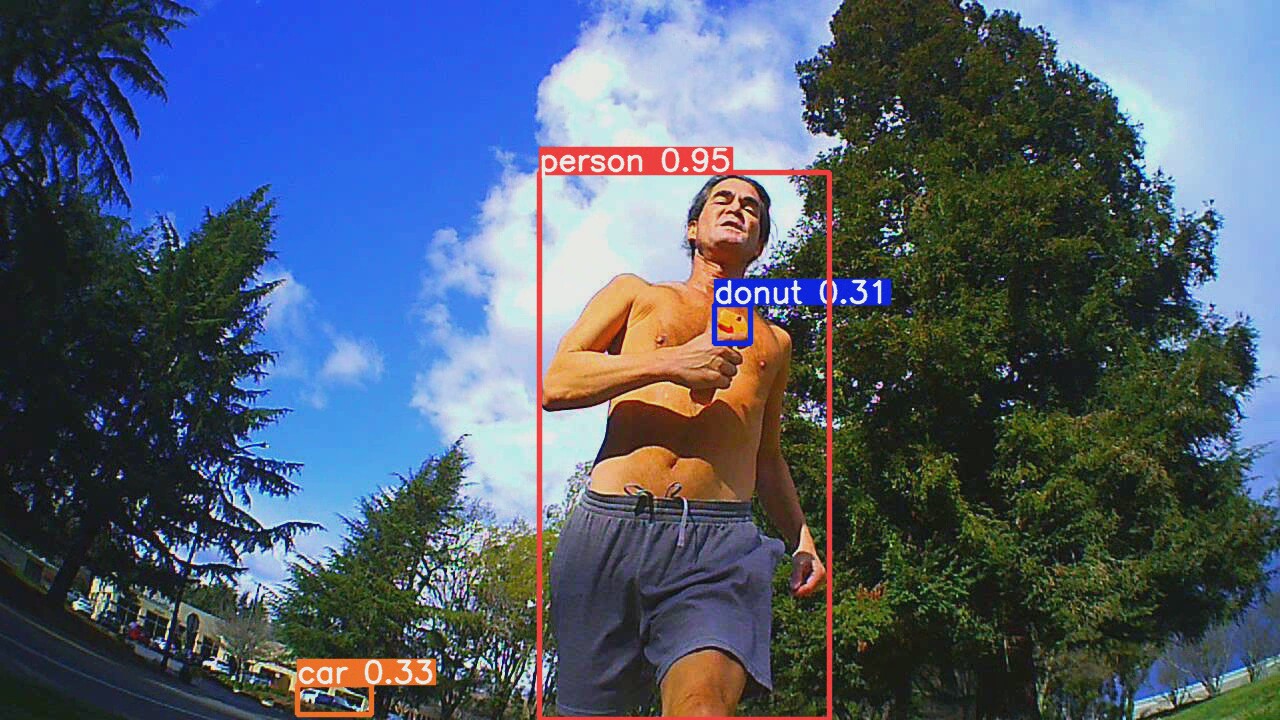




The big model does a vastly better job discriminating between lions & trees. It still has false hits which seem to be small enough to ignore. The small selection of objects YOLO tracks makes lion wonder what the point is. Maybe self driving relies on labeling objects that move while relying on parallax offsets to determine obstructions.
The size & speed of the big model on a GPU compared to the 4MB tensorflow model on a raspberry pi makes lions appreciate how far computing power has declined.
The next task is selecting 1200 frames to train from, making detect.py output xml files for the training & validation data. There's no way a lion could manually label 1200 images. It's pretty obvious the COCO dataset was labeled by an even bigger model.
Training a tensorflow model took only 30 epochs before val_loss stopped. The new model was drastically worse than the model trained from COCO. The mane problem was detecting the lion in the sides of the frame & partially obstructed. It also had trouble detecting any poses that weren't trained in.
The mane problem with recursively training a model is there's much less variation in what it's tracking than the COCO data.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.