 Yann Guidon / YGDES
Yann Guidon / YGDESOne BIG conceptual challenge with sorting algorithms is to put each new datum as close to the right place as possible on the first try, so the actual running time gets closer to O(n). The n×log(n) part comes from recursively handling more and larger buffers so the smaller and the fewer, the better and faster.
If one datum is placed at the other side of the range, then it will usually perform log(n) operations to reach the final position, by leaps and bounds of more refined lengths.
That's why hash-tables and radix/bucket sorts are so efficient (on top of having no comparison with the neighbours) : Data are placed as close as possible to their definitive location, so there are fewer comparisons and moves to perform.
But in a hybrid sort algo, this is less obvious.
....
I was looking at the "shared stack" system and beyond its allure, I found that there is a deeper structure and organisation that needed to be addressed, as it seems even more promising.
Do you remember 2s complement signed numbers, and how they map to unsigned integers ? Also, look at ring buffers and how they can wrap around integer indices, using modulo addressing. Look also at how we can take one problem from both ends, as we did just before with the basic merge sort turned into a 2-way merge sort.
Shake it well and serve with an ice cube.
So this gives a "working area" that wraps around, with modulo addressing. Start by putting the first data run in the middle of the working area but since this is modulo, there is no middle anyway. So we start with a point, an origin, and we can work with data on both ends of the dataset mapped to the working area.
And this brilliantly solves a BIG problem of fragmentation I had with the merge sort, which is not usually "in place". If I want to merge sort 2 runs that sit on the "free end" of the data set. Usually, the "other end" sits at address 0 and is stuck there. One needs to allocate room "after"/"beyond" the "free end" of the data set, perform the merge there and move the merged-sorted block back to the origin.
Forget that now !
Since the "modulo addressing" doesn't care where the start is, there are two ends, and we'll use the FIFO/ring buffer terminology : tail and head. These numbers/pointers respectively point to the lower and higher limits of the dataset in the working area. Memory allocation becomes trivial and there is no need to move an allocated block back in place : just allocate it at the "other end" !
Let's say we have 2 runs at the head of the data set: we "allocate" enough room at the tail and merge from the head to the tail. And head and tail could be swapped. The dataset always remains contiguous and there is no fragmentation to care about ! When the whole dataset must be flushed to disk for example, it requires 2 successive operations to rebuild the proper data ordering, but this is not a critical issue.
Which end to merge first ? This will depend on the properties of the 2 runs at both ends. Simply merge the smallest ones, or the pair of runs that have the smallest aggregated size.
This changes something though : the "stack" must be moved away from the main working area, and since it will be addressed from both ends (base and top), it too must be a circular buffer.
What is the worst case memory overhead ? It's when the sort is almost complete/full, and a tiny run is added and merged, thus requiring 2x the size of the largest run due to the temporary area. In a pathological case, if memory is really short, a smarter insertion sort would work, but it would still be slow...
This can work because the main data set is a collection of monotonic runs. They are longer "in the middle" but are not in a particular order. Thus there are in fact 4 combinations possible :
- 2 heads to the tail
- 2 tails to the head
- 1 head added to the tail
- 1 tail added to the head
This is much more flexible, thus efficient than the "single-ended" traditional algorithms, because we can look at 4 runs at a time, with simpler heuristics than Timsort, thus fewer chances to mess the rules.
___________________________________________________________
Here is how the previous iteration of the algo worked/looked:
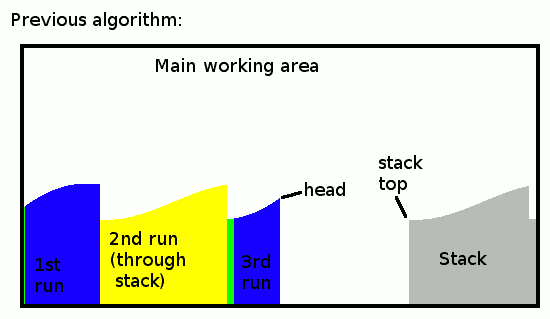
New runs are added to the head when an ascending run was detected, or to the stack when a descending run is found. When the run ends, if it's a descending one, the stack is copied/moved to the head to reverse its direction. This last operation becomes pointless if we organise the runs differently.
Let's simply remove the stack. Instead we add the runs in the middle of "nowhere" so there is no base, instead a void the left and to the right of the collection of concatenated runs.
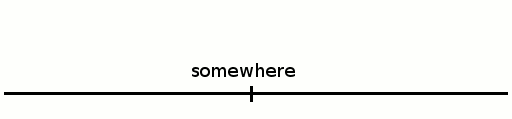
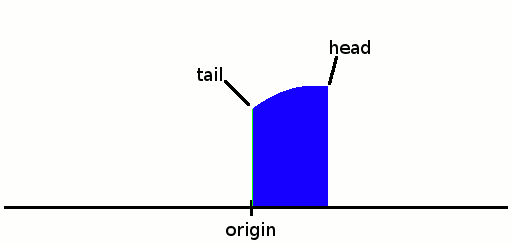
We put the first run there. The first/lowest occupied index is the tail, the higher/last is the head.
The "horizontal" parts (in green) are first written after the head. But if the slope is found to be downwards, this part is moved to the tail after the remaining data are reverse-accumulated from there (because we can't know in advance the length of the run). Usually, there are rarely more than a few identical data so the move is negligible. It could be avoided but the game is to get the longest run possible so this is fair game, as this block would be moved later anyway.
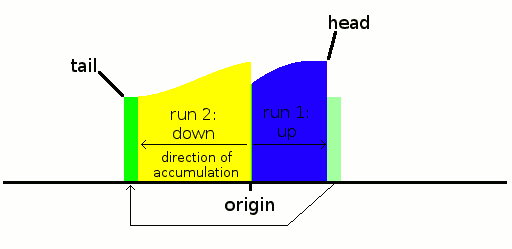
We could start to merge here but we can select a more favourable set of candidates if we have more data, like at least 4 runs, so let's continue accumulating. The next run goes up so it's accumulated on the head side.
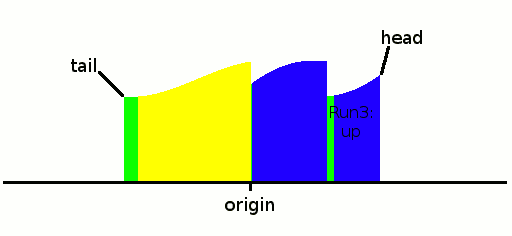
OK the stream ends here and we only have 3 runs, but we can already select the first pair to be merged: run1 and run3 are the smallest so let's merge them. Since they are on the head side, let's "allocate" room on the tail side:
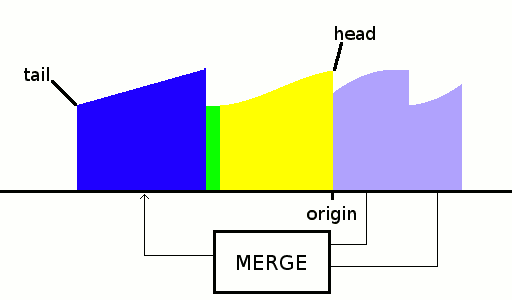
And now we can merge the final run to build the result, and since there are only 2 runs to merge, the result can go either on the tail or the head:
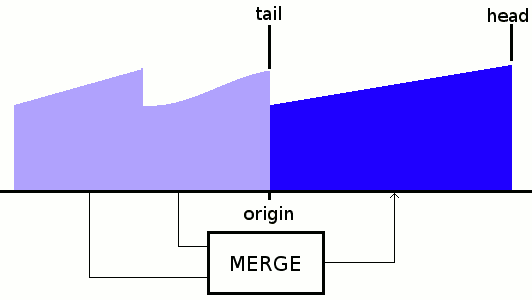
Here we see that the merge sort has an inherent space constraint, so the final merge requires at least 2× the total space overall.
This example used a 2-way merge operation, but ideally more ways (4?) would be better.
The great aspect of using wrap-around addressing is that it can handle any combination and worst-case situation, like when there are only up-runs, down-runs and even alternating runs. The origin does not matter so the whole contiguous block could move around at will with no consequence.
...........
.
.
Edit:
OK there might be a small limitation to the scheme I presented above. Ideally we would want to merge more than 2 runs at a time to save time, using 2 ends of each run to parallelise the process, but this is possible only when all runs are on one side, putting the result to the other side. Otherwise, that is : if 2 blocks are at opposite sides, then one of the blocks will already take the place of the merged result, for an in-place merge. This means that the merge sort can't use 2 sides of the runs, or it would overwrite the overlapping original run.
It's a bit less efficient but not critical.
This means I have to program several variations of the merge algorithms : one for sorting from the lower end first, another to sort from the higher end first, another to sort from both ends at the same time, and an extension to 3 or 4 runs at once. Selecting which one to use will require some heuristics, for sure... For example : if I merge 2 runs on opposite ends, which end should I favour ?
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.
Damnit I made a little mistake in one of the illustrations. But that's not a severe one.
Are you sure? yes | no