Yolo v5 Autonomous Driving Scenario
ROS projects by Hiwonder.
We have launched our JetAuto ROS robot car and create some amazing functions. Autonomous driving scenario is one of them. We use Yolo v5 to train robots and test it.
1. Yolo Series Models Introduction
1.1 YOLO Series
YOLO (You Only Look Once) is an one-stage regression algorithm based on deep learning.
R-CNN series algorithm dominates target detection domain before YOLOv1 is released. It has higher detection accuracy, but cannot achieve real-time detection due to its limited detection speed engendered by its two-stage network structure.
To tackle this problem, YOLO is released. Its core idea is to redefine target detection as a regression problem, use the entire image as network input, and directly return position and category of Bounding Box at output layer. Compared with traditional methods for target detection, it distinguishes itself in high detection speed and high average accuracy.
1.2 YOLOv5
YOLOv5 is an optimized version based on previous YOLO models, whose detection speed and accuracy is greatly improved.
In general, a target detection algorithm is divided into 4 modules, namely input end, reference network, Neck network and Head output end. The following analysis of improvements in YOLOv5 rests on these four modules.
1) Input end: YOLOv5 employs Mosaic data enhancement method to increase model training speed and network accuracy at the stage of model training. Meanwhile, adaptive anchor box calculation and adaptive image scaling methods are proposed.
2) Reference network: Focus structure and CPS structure are introduced in YOLOv5.
3) Neck network: same as YOLOv4, Neck network of YOLOv5 adopts FPN+PAN structure, but they differ in implementation details.
4) Head output layer: YOLOv5 inherits anchor box mechanism of output layer from YOLOv4. The main improvement is that loss function GIOU_Loss, and DIOU_nms for prediction box screening are adopted.
2. YOLOv5 Workflow
2.1 Priori box
When inputting image into model, we need to provide the target area of the image to be recognized. Priori box is a box used to mark the target recognition area on image.

2.2 Prediction box
Prediction box generates automatically, which is the output of model. As the first batch of training data is fed into model, prediction box will generate automatically. The position where same kind of objects appear in high frequency will be set as the center of prediction box.
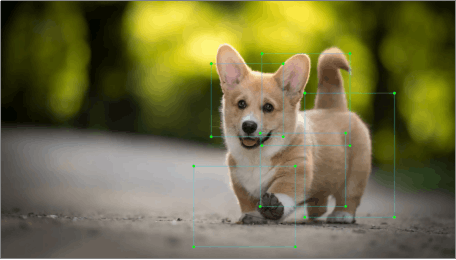
2.3 Anchor box
The generated prediction box’s size and position may deviate, and anchor box plays a role in calibrating prediction box’s size and position.
Prediction box determines where anchor box is generated. In order to interfere the position of next generated prediction box, anchor box will be placed at the relative center of prediction box.

2.4 Implementation Process
After data is calibrated, a priori box occur on the image. Next, model generates a prediction box subjecting to the position of priori box. Anchor box is generated whenever prediction box is generated. Lastly, the weight of this training is updated to the model.
Each newly generated prediction box is affected by the last generated anchor box. The above operation will be repeated to eliminate deviation in prediction box’s size and position till the prediction box and priori box coincide.

3. YOLOv5 Data Collecting
3.1 Image Collecting
We need to collect and label data first, since training yolov5 models requires large amount of data.
1) Start JetAuto, then connect it to NoMachine.
2) Run command to stop APP service.
jetauto@jetauto-desktop:~$ sudo systemctl stop start_app_node.service
4) Input command to enable camera service.
jetauto@jetauto-desktop:~$ roslaunch jetauto_peripherals astrapro.launch
5) Double click 📷 on the desktop to open image acquisition tool.

“save number” refers to picture ID i.e....
Read more »
 Johanna Shi
Johanna Shi
 kutluhan_aktar
kutluhan_aktar

Are you for in a situation where too exhausted to drive back to home like returning home from a party, long work schedule? Safe driver Dubai is ready to help you…
https://safedriverdubai.ae/