 Arya
AryaIntroduction:
When I started developing pyLCI, it was meant to be an interface for 2x16 character displays. Therefore, it was optimised for having only two lines of text on the screen and 5 buttons. I'm not aiming to maintain backwards compatibility between pyLCI for character displays and ZeroPhone pyLCI. In fact, the ZeroPhone version of pyLCI might as well be renamed to signify the fact that it's a similar, yet different version of software.
Right now, ZeroPhone pyLCI is not too far from original pyLCI in terms of capabilites. I'm listing those problems so that there's a list of problems that currently interfere with pyLCI being a good ZeroPhone interface.
The problems listed are either finished, WIP or still waiting to be solved - I encourage you to help me solve them by either helping me find a good solution, or contributing to the development (I've opened GitHub issues to keep track of problems, they're linked in the titles and sometimes in the text.)
Naming
pyLCI is Python-based Linux Control Interface. However, right now it's becoming ZeroPhone-specific and moving further from pyLCI concept. I'll be thinking of a better name - it obviously has a low priority, but if you have some ideas, please throw them here.
Text-based UI elements
As pyLCI was character display-based, it mainly operated with text. Right now, ZeroPhone uses a display which actually allows setting individual pixels, and there's much more screen real estate - but pyLCI still uses text in UI elements, using the display_data function which is limited to text. In fact, there's so much more ways a simple menu could look like, but it still does same old stuff it did before. Granted, it's going to be harder to test graphical views than it'd have been with text, but I don't have tests anyway, so maybe it doesn't matter ;-)
UI is mostly 5-key based
pyLCI was designed for as less keys as possible, and back then I decided that 5 keys should be enough for everyb^W basic interfacing needs. There were other keys, yeah, but I didn't have a good purpose for them at that time. Those keys are UP, DOWN, LEFT, RIGHT and ENTER - on default ZeroPhone keypad board, they form a cross in the upper center, it's easy to spot them. The problem is - right now, there are some other keys, and they aren't used, even though in many places they are the intuitive choice. For example, C1 and C2 (top left and top right corners) could easily be used for "Back" and "Options" choices in menus - but that's not yet the case. This is going to be fixed - but it's not as simple as updating the mapping because display also has to reflect the key purpose with some kind of labels right on top of the keys.
Also, the interface, as well as drivers, doesn't yet report type of keypress, as well as the fact that a key is held, though there's going to be a mechanism for it sooner or later.
Lack of tests
I never really taught myself TDD - my main software project for the last year has been pyLCI, and I often didn't know how the thing I'd have had implemented would behave like until I implemented it, so writing tests before adding functionality would never work for me =) However, right now there actually are things that could benefit from tests - mainly UI elements, and I do believe my programming style could benefit from getting used to TDD. The main obstacle (though a small one, admittedly), that was preventing me from just adding tests as I go, is mainly the setup cost - picking one of the testing frameworks and writing a base of tests for the most important things. Fortunately, this February, the project was joined by a person that is currently working on project's code infrastructure, as well as helping refactor the code. Shout out to [unnamed contributor], he's doing work that's vital for ZeroPhone success!
Division of apps by processes
Right now, pyLCI apps are more like plugins. You add them in a folder and they get auto-detected and added to main menu at pyLCI startup. This lacks all the flexibility that apps have, like "restarting/installing/uninstalling apps on the fly", but also adds security problems - now, each app can basically access any app's namespace and do whatever. Security is lacking, and so is usability. So, the outline of my idea is - run pyLCI core, with all its hardware drivers and context switching logic, as root, or maybe even as a low-privilege user added to groups having access to hardware. Then, make input and output proxies that'd run over local sockets, basically, make them RPC-enabled, and pass input and output events from/to apps that'd run as separate processes. It seems like a reasonable way, and, once there are input and output proxies, it should be easy as well. However, one challenge that comes to mind is running many, many apps under many different users. Like, if each app is going to need a Python interpreter and there are 20 of them, CPU and RAM consumption is going to be horrible. If that can be gotten down to even 5 processes of different levels of security, that would be awesome. The way to decrease process count, assuming most apps are stock and more or less trusted, is to have a process that could run multiple pyLCI apps with one Python interpreter, more or less how pyLCI does it with plugins, but have it over sockets and as a separate user. Say, we have a calculator app, a stopwatch/timer app, an app to fetch RSS from the internet and an app to control the music player - it's not unreasonable to launch them together in one interpreter, especially when they're trusted and more or less need the same privileges.
With the structure I'm describing, there's some good news, too - it's going to create pyLCI bindings for different languages, like, say, JavaScript - no matter what people talk about it, it's insanely popular. The downside would be having to reimplement all UI elements along with creating bindings for each language - UI elements are one thing that need to be in app-side code =(
One more obvious thing to point out - I don't know how much security could launching apps as different users give, there's certainly some but I can't tell if it's going to be secure enough to, say, eliminate any data leaks from a secure messenger when there's at least one untrusted third-party app. It's entirely possible there could be encrypted RPC and everything, but at this point I'm sure I'm missing something I'll discover while actually implementing this. Of course, this is a necessary feature and we'll have to figure that out.
Context switching - input/output proxies?
From the beginning, pyLCI is single-context - no multitasking, the workflow is menu-driven, you need to go back in a menu if you want to exit the current application and go to another. No notification support - the problem is that UI elements wouldn't know if they lost context, so if screen contents were suddenly changed, a menu wouldn't know that they did, and if input callbacks were set by something that popped on the screen, the UI element would never know it happened. The whole flow is quite linear, and one step throwing an exception, or an UI element accidentally setting callbacks at the wrong time, would make the interface not respond. This means that there can be no notifications, no hotkeys to switch to another app instantly, no "press call button to get to call menu", and this obviosly suc^W isn't a good architecture for phone UI, where any app could be requested at any moment. One of the main problems is that InputListener and Screen objects (i and o) speak to hardware directly, there's no object that could be passed to UI elements so that they wouldn't have to distinguish between "app active" and "app not active" states while operating, which IMO is more of a hack- compared to just having proxy objects that'd also save input/output state and be able to restore it instantly when the app is activated. For now, it's going to need some hacks (mainly because of the thread problem, described right below), but it looks very doable (apart from the fact I'll need to somehow save active PIL canvases from output device), and I've already started a small rewrite.
Threads constantly spawned - better idle loop? Idle loop managed by pyLCI?
When I started developing pyLCI, a long long time ago, I didn't know as much of programming architectures as I know today - and even what I know today isn't that much. In the beginning, pyLCI was basically menu code, horrible input/output drivers and some hard-coded functions. Even at that point, menu actions (move up/down, select element, exit menu) were callbacks. One of problems I stumbled upon at that time was that menus couldn't be nested because the input listener thread (the one to execute callbacks), being busy with the first menu, never got to callbacks of second menu. I solved it, but I didn't understand how - for a year and a half, I was occasionally thinking "It works, but I actually don't know why". Then, after a year and a half, when I was reducing pyLCI CPU consumption, I added some debugging statements to input listener threads and understood that, for each nested menu, a separate thread is started.
Say, we have menu A and its idle loop is run by Thread number 1, and there's input thread (Thread 2) that's executing menu A callbacks. ENTER key is pressed, and select_entry callback is executed from Thread 2. The callback is another menu's (Menu B) activate() method, so it, after setting things up, moves on to another idle loop. However, before that idle loop, menu calls InputListener's listen() method, which basically makes the InputListener forget about the currently running listener thread and launch a new one, Thread 3, which will then execute the Menu B callbacks.
I think this is a problem, but I'm not sure why - I had some points against that approach, but I have too much stuff in my head to remember them now. Also, I don't know how to actually solve it - now, all those threads help preserve UI element execution contexts, so that you can actually go back in a menu. If I were to remove the threads, I'd need to invent another way to store execution contexts, and a lot of stuff which, frankly, doesn't completely fit in my head. For now, having a context actually means any step in UI is done by an object - so all UI elements are objects (and Printer is trying hard to look like one). A context-less approach might yield some nice usage scenarios, but I can't imagine any good scenarios yet. Anyway, sometime this year I'll be looking into how other UI libraries implement it - and if somebody has a better plan, or is even willing to implement a new execution context scheme, that would help. For now, I'll probably make this behaviour more explicitly expressed in the code - and even after refactoring I might leave this "feature" in InputListener anyway, as long as it doesn't break anything, it could be useful in some apps.
CPU load
You've read about the thread problem, right? While UI elements run in background, they basically run an idle loop which sleep()'s. I'm guessing this isn't the best use of CPU time and could probably be done with something less CPU-consuming. There aren't useful things that UI elements could run while in background, but I guess there could still be a way to decrease CPU consumption - it might very well be that time.sleep()s could be replaced by something like select().
UI element rewrite - was it worth it?
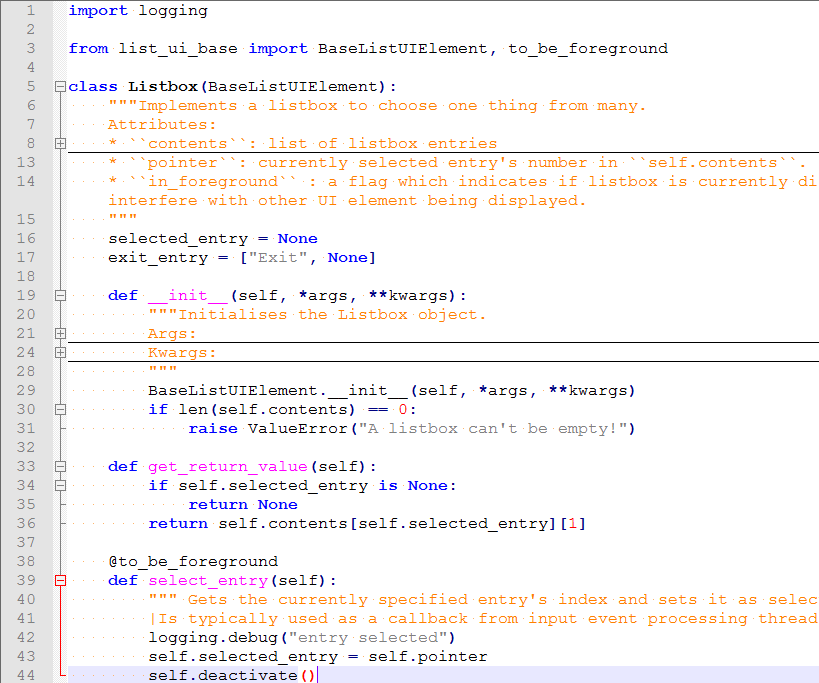
While looking for ideas to solve thread problem, I decided to make an UI element rewrite and, possibly, also cover them with tests. The problem is - there are multiple UI elements that give a list of entries that you can scroll through - Listbox, PathPicker, Menu and Checkbox elements. PathPicker and Listbox were based off Menu UI element, but Checkbox wasn't - for some reason, I just copied the menu.py file to checkbox.py while creating the UI element. Considering that I was in a hospital because of some inflammation when I was writing the Checkbox element, I'm not going to question my motives =) However, the lack of an unified interface caused multiple inconsistencies when adding features - for example, Checkbox element didn't have "page up/down" or scrolling through elements, and PathPicker had some hacks due to the way it was overriding Menu functions. This all needed a better base class, that would contain all the repeating code. What I did was - print out the code, and then go through it with a marker. This is a way I use to refactor code, and while I'm guessing IDEs are much more effective at this, I've never been good with IDEs =)
I understood there are two kinds of UI elements - those that can be nested, and those that can't. For example, Menus can't be nested, which is one of their main features, PathPicker has a right button menu that lets you select a directory (instead of entering it, which is what ENTER key is going to do) and see its path. On the other hand, Listbox lets you select one element out of many and Checkbox lets you enable/disable things. First group has in_background property and will use that to know when to get deactivated, second group just uses in_foreground. After looking through the documents, I understood that second group can easily have the same base, and first group can re-use that base with some features added and one or two functions overriden, so that's what I did. For example, here's the Listbox inheritance chain:
Listbox <- BaseListUIElement
- and here's a Menu inheritance chain -
Menu <- BaseListBackgroundableUIElement <- BaseListUIElement
At the moment, the code pushed to GitHub, but is not finished. Hopefully I upstream the changes soon. There are also no tests now, I might need one more day just to make them - but I do want to test this through, since I was finishing the rewrite while being quite sleep-deprived, and I fucked up a couple more things that same day =) I do think it would be very unfair for me to not make tests after the test coverage effort a project's contributor started, though.
More code was deleted than added, this is a good sign IMO
Was there a benefit? I'm not sure anymore. On one hand, now the code doesn't repeat, it's likely going to be easier to write new UI elements, add features to existing ones and surround them with tests - especially since UI elements are the thing that needs testing the most, it's basically what the user interacts with, and where most of the logic happens. On the other hand, I can't imagine many list-like UI elements that could be added - there could be some that will be added once there's a need and a vision, but the question is - are they going to fit in the scheme that I created? Also, instead of understanding one Python object, you now need to understand a chain of two or three objects in two separate files. IMO, now the UI objects need much better documentation, with some graphs to show which functions are used and when, and how to override them to achieve whatever is necessary. Moreover, I didn't get a better insight into "new threads spawning" problem while refactoring, even though I hoped to - though I'm starting to get some ideas while writing this worklog =)
This is more or less all about pyLCI problems. Later on, there'll be a new installation of "ZeroPhone software": about APIs, power consumption, scripting interfaces and UI standartization.
P.S. I just saw that there's a "Project boards" feature on GitHub, and maybe these kind of issues could be better tracked by these. Does anybody have a good example of a project that uses GitHub Project Boards?
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.