 Yann Guidon / YGDES
Yann Guidon / YGDES@llo couldn't wait to put the YGREC8 in a #ProAsic3-Stamp ! So a VHDL version seems to be required pretty fast.
The core itself is quite trivial to write in VHDL : the datapath is a bunch of MUX. There is close to no sequencing going on, except to access memory. Actually the only part that requires care is the ALU, which is not well defined in detail.
Yet.
In the first iteration, I'll just ignore the shifter unit, though it's easy to make a 8-bits version from the 16-bits version designed for the #Discrete YASEP. We're left with the ROP2 and ADD/SUB units, plus the PASS function (required by CALL and MOV).
ROP2/ADD is not black magic either. MOV is tricky though because it's mainly some kind of operation with DST disabled. Or I could pull the old MUX trick but to save gates, the XOR, AND and OR are used by the Generate/Propagate logic of the adder... and it's good to save gates.
I'm trying to optimise the logic so I move the opcodes around and I get this :
| F1, F0 \ F3, F2 | ROP2 (00) | ADD (01) |
|---|---|---|
| 00 | OR | CMPU |
| 01 | XOR | CMPS |
| 10 | AND | SUB |
| 11 | ANDN | ADD |
The BOLD opcodes are those that use the inverter on the DST operand. I moved them so the boolean equation that triggers the DST XOR layer is : (F1 and F0) XOR F2. The resulting diagram :
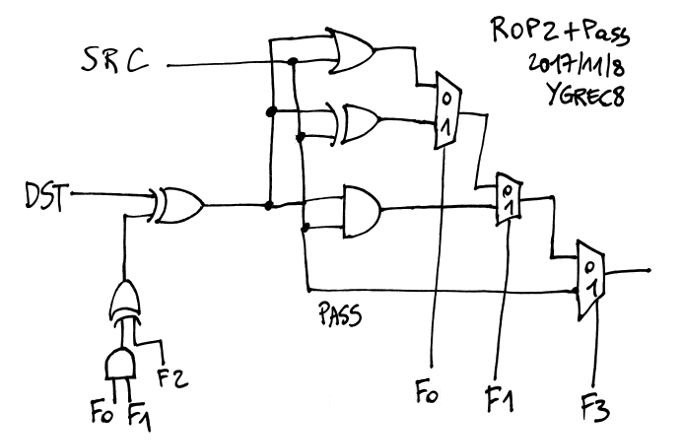
This logic covers all the ROP2 and PASS functions, as well as the initial parts of the ADD/SUB logic (the DST XOR layer and the carry/propagate gates AND and OR).
There is still some headroom for the PASS branch to add a MUX that brings data in the pipeline from the input ports, for example.
Now, to get the adder, some Carry LookAhead logic is required, and it's already covered in A reasonable discrete ALU. Since we use ProASIC3's 3-input "tiles", and the width is only 8 bits, it makes sense to partition the CLA into 3-bits blocks, made of some repetitive logic. According to this simulator at http://www.ecs.umass.edu/ece/koren/arith/simulator/Add/lookahead/ the CLA3 approach seems to be the fastest, which indeed is the closest to sqrt(8). The interactive script even generates a diagram:
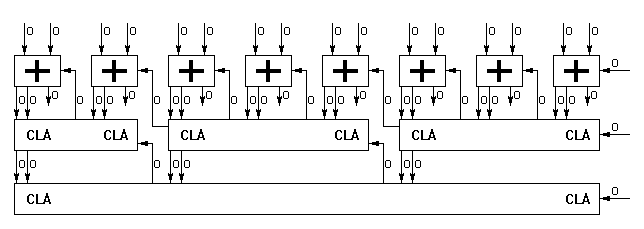
The carry-out is not shown but not hard to figure out: it's a simple use of the input-less MSB of the CLA2. A CLA3 is shown here:
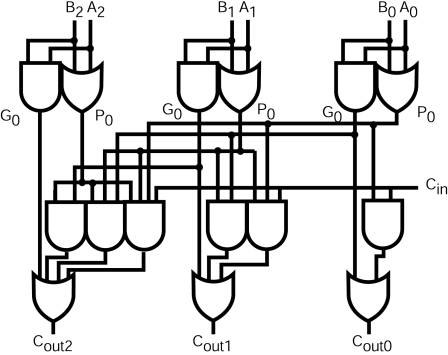
(Oh, do you see the typos ?)
The equations for the CLA3 units are:
inputs: Cin, G0, G1, G2, P0, P1, P2; C0 = G0 OR (Cin AND P0); C1 = G1 OR (Cin AND P0 AND P1) OR (G0 AND P1); C2 = G2 OR (Cin AND P0 AND P1 AND P2) OR (G0 AND P1 and P2) OR (G1 AND P2);
The single-bit adders are like a full-adder but with the Propagate and Generate outputs added:
Inputs: Cin, A, B; P = A OR B; (already computed for ROP2) G = A AND B; (done too) S = P XOR Cin;
Here is the result so far:
-- YGREC8/ALU8.vhdl
-- created mer. nov. 8 07:21:19 CET 2017 by Yann Guidon (whygee@f-cpu.org)
-- Released under the GNU AGPLv3 license
--
-- This is the arithmetic and logic unit of YGREC8,
-- performing the add/sub and ROP2 operations on 8 bits.
--
--
-- OPCODES:
-- F3 F2 F1 F0
-- 0 0 0 0 OR
-- 0 0 0 1 XOR
-- 0 0 1 0 AND
-- 0 0 1 1 ANDN
-- 0 1 0 0 CMPU
-- 0 1 0 1 CMPS
-- 0 1 1 0 SUB
-- 0 1 1 1 ADD
-- 1 0 0 0
-- 1 0 0 1
-- 1 0 1 0
-- 1 0 1 1
-- 1 1 0 0
-- 1 1 0 1
-- 1 1 1 0 CALL (PASS)
-- 1 1 1 1 MOV (PASS)
Library ieee;
use ieee.std_logic_1164.all;
entity ALU8 is
port( F0, F1, F2, F3, Cin : in std_logic;
SRC, DST : in std_logic_vector(7 downto 0);
RESULT : out std_logic_vector(7 downto 0);
Cout : out std_logic);
end ALU8;
architecture rtl of ALU8 is
Signal ALU_XOR, P, G, S, C,
ALU_ORXOR, ALU_ORXORAND, ALU_ROP2,
DSTX, Complement
: std_logic_vector(7 downto 0);
Signal P2, G2 : std_logic_vector(1 downto 0);
Signal C2 : std_logic;
begin
-- initial XOR of the operand
Complement <= (others => (F0 AND F1) XOR F2);
DSTX <= DST XOR Complement;
-- ROP2
ALU_XOR <= SRC XOR DSTX;
G <= SRC AND DSTX;
P <= SRC OR DSTX;
ALU_ORXOR <= P when F0='0'
else ALU_XOR;
ALU_ORXORAND <= G when F1='1'
else ALU_ORXOR;
ALU_ROP2 <= ALU_ORXORAND when F3='0'
else SRC;
-- ADD/SUB, Carry-Lookahead adder with 2-levels of CLA3 blocks
C(0) <= Cin;
--inputs: Cin, G0, G1, G2, P0, P1, P2
C(1) <= G(0) OR (Cin AND P(0));
C(2) <= G(1) OR (Cin AND P(0) AND P(1)) OR (G(0) AND P(1));
C(3) <= G(2) OR (Cin AND P(0) AND P(1) AND P(2)) OR (G(0) AND P(1) and P(2)) OR (G(1) AND P(2));
P2(0) <= P(0) AND P(1) AND P(2);
G2(0) <= G(2) OR (G(0) AND P(1) and P(2)) OR (G(1) AND P(2));
--inputs: C3, G3, G4, G5, P3, P4, P5
C(4) <= G(3) OR (C(3) AND P(3));
C(5) <= G(4) OR (C(3) AND P(3) AND P(4)) OR (G(3) AND P(4));
C(6) <= G(5) OR (C(3) AND P(3) AND P(4) AND P(5)) OR (G(3) AND P(4) and P(5)) OR (G(4) AND P(5));
P2(1) <= P(3) AND P(4) AND P(5);
G2(1) <= G(5) OR (G(3) AND P(4) and P(5)) OR (G(4) AND P(5));
-- -- 2nd level of CLA
--C2(0) <= G2(0) OR (Cin AND P2(0)); == C(3)
C2 <= G2(1) OR (Cin AND P2(0) AND P2(1)) OR (G2(0) AND P2(1));
--inputs: C2, G6, G7, P6, P7
C(7) <= G(6) OR (C2 AND P(6));
Cout <= G(7) OR (C2 AND P(6) AND P(7)) OR (G(6) AND P(7));
S <= ALU_XOR XOR C;
RESULT <= S when F3='0' and F2='1' -- ADD/SUB group
else ALU_ROP2;
end rtl;
I couldn't make it without the help of https://en.wikipedia.org/wiki/Lookahead_carry_unit. It compiles and runs with GHDL but no testbench yet.
Actually, it compiled on the first attempt. No error. Highly suspicious !
See the log Netlist and structure of the adder for more up-to-date details.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.