 Gilchrist
GilchristA web browser for the Arduino platform is a silly idea.
The PIP Arduino browser is an on-going project. Parsing HTML code cleanly is not easy. Doing it in under 2KB of RAM is less so. When the code is cleaned up bit more (soon), it will be available on Github.
PIP uses stock parts: Uno, ethernet shield, LCD screen (320x240) and a joystick. The non-stock parts use a prototype shield and resistors to lower the 5v level to 3v for the LCD.
And when my ESP8266 WiFi module arrives, PIP is going wireless. Oh, yeah.
In the mean time, I'll be adding project logs regularly, backdated to the start of this project in February 2014. First log entry.
Viewing web pages is a multi-step process:
- The raw HTML is parsed as it is downloaded and all the verbose HTML text tags are converted to single byte binary tags. The HTML tag text is hashed to compactly recognise tags.
- A state-based algorithm is used for tag parsing. The rules for spaces, CRs, LFs, Tabs, etc. are applied at this stage. Unimplemented tags and data are discarded.
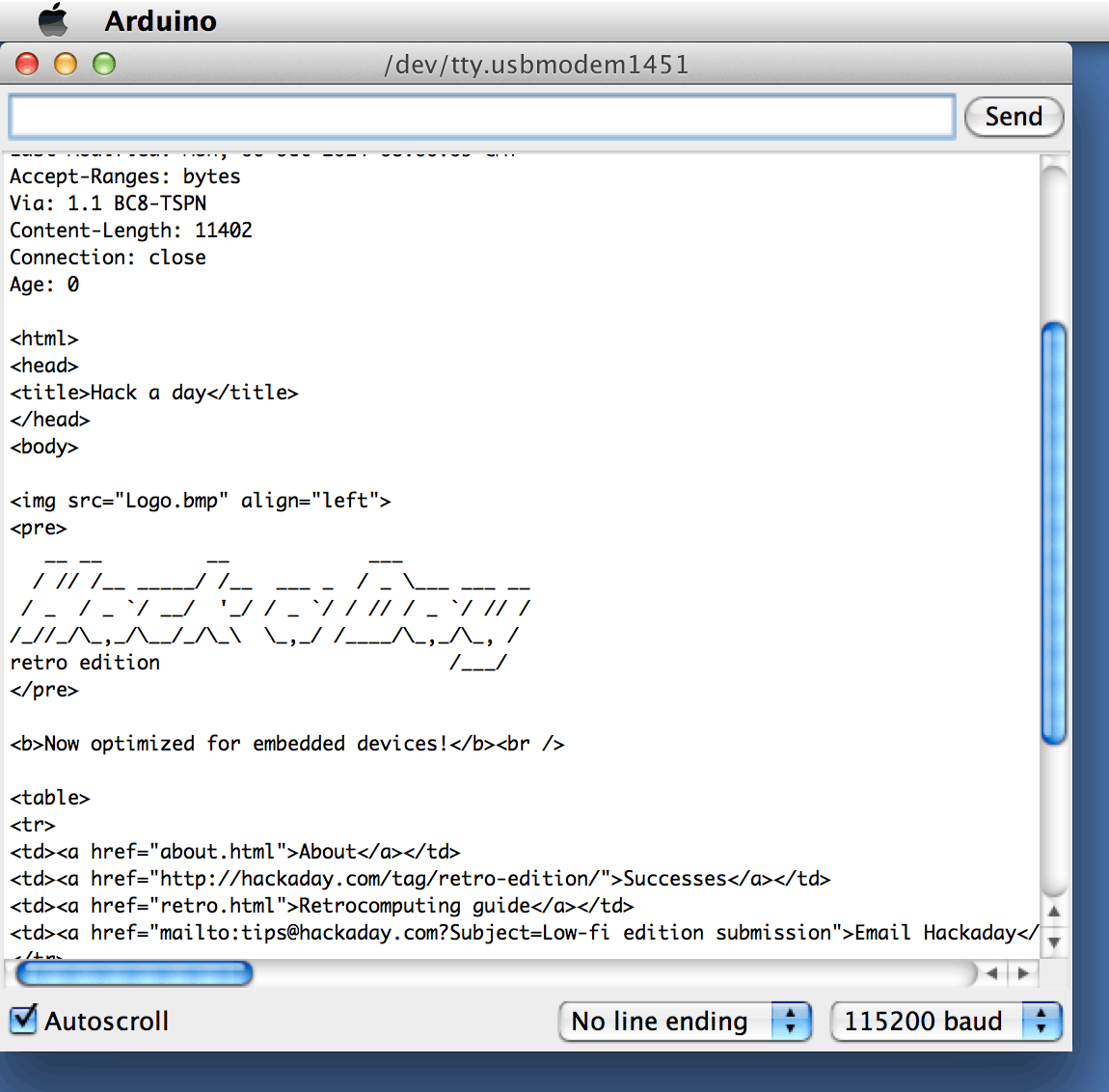
- This data is cached on the SD card. It generally results in a 50% smaller file that the original HTML file. As a format HTML sure has a low signal to noise ratio.
- When the download completes, the cached data is pulled off the card and rendered to the LCD screen in page chunks. The screen can display 53x30 characters (with the top line being reserved for status and the URL).
- A page index for the cache file is built as the pages are displayed. Similarly, a URL table is built for each page as it's rendered. Heading, bold and link tags use colour coded text.
- The user can page through the HTML document using the joystick up/down, or step through all the embedded URLs left/right. Clicking the joystick button opens the highlighted link and initiates the new page downloading.
This could be considered inspiration:

Source: http://dilbert.com/strips/comic/1998-09-12/
Still to do:
- Increase robustness for poorly coded HTML pages. Probably requires the item below.
- Rebuild the state machine so all states and associated info can be encoded in data, rather than code to increase extensibility.
- Implement pretty-printing again, so words aren't broken over two lines.
- Fix the page rendering so that HTML states broken over a page boundary are still honoured on the next page.
- Add WiFi! By dumping the data to SD card via SPI and not through another serial connection, PIP should be able to keep pace with WiFI download speed and not blow the buffers.
- Build a daft terminal style box to put this in. Retro.

 This library didn't do anything except draw rectangles or characters. I figured I could do without diagonal lines and things to save space. And 53 x 30 characters per page would have to do.
This library didn't do anything except draw rectangles or characters. I figured I could do without diagonal lines and things to save space. And 53 x 30 characters per page would have to do.










 Hugh Darrow
Hugh Darrow
 Mike Szczys
Mike Szczys
 Mark VandeWettering
Mark VandeWettering
 Mark Henderson
Mark Henderson
I was wondering if Jexcel would fit into PiP. Arduino Mega have up to 50mb memory, how much would we need?