 Gene Foxwell
Gene FoxwellThis project is about building a model of a machine that is in principle simple to build, and capable of co-operating with other similar machines to complete a wide variety of real world tasks. As I am interested in the behavioral aspects of this system this project will concentrate on a simulated model. In order to keep the overhead low, and allow as many people as possible to run the simulation on their own local machines I've chosen the write the simulation in javaScript. This does put certain performance limitations on the simulation (realistically it seems to only work about 25-50 virtual drones, after which performance begins to noticeable degrade in some cases).
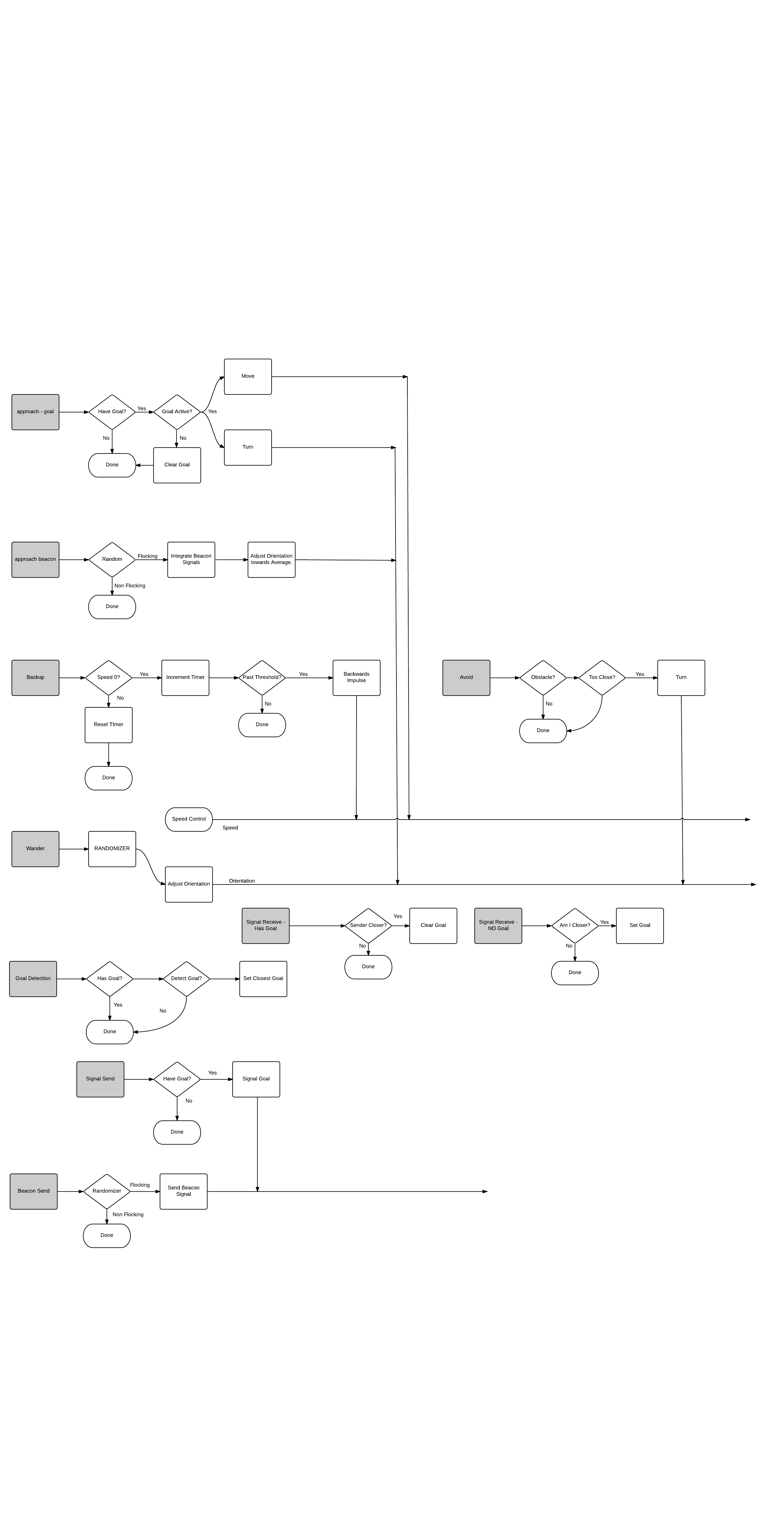
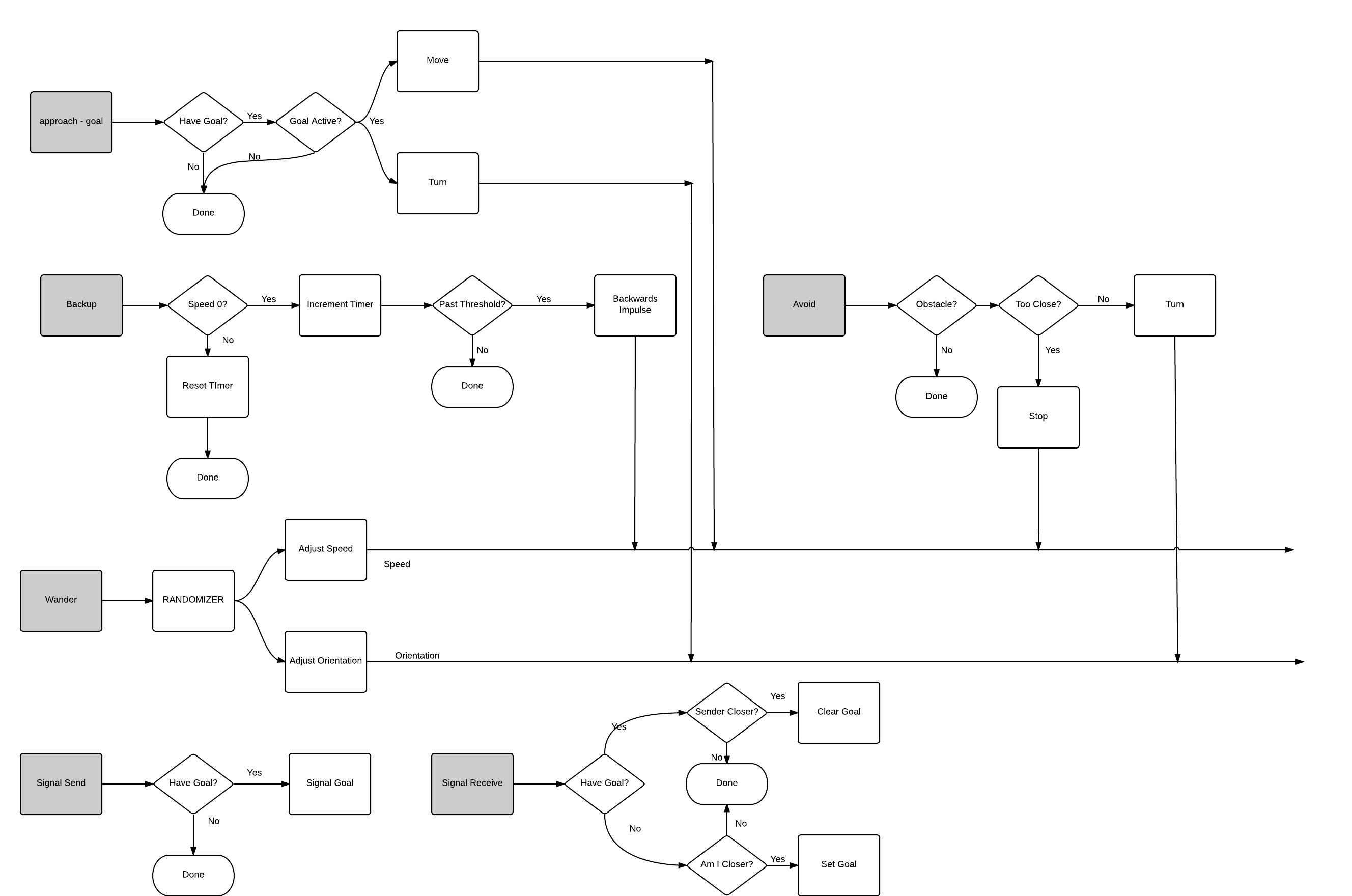
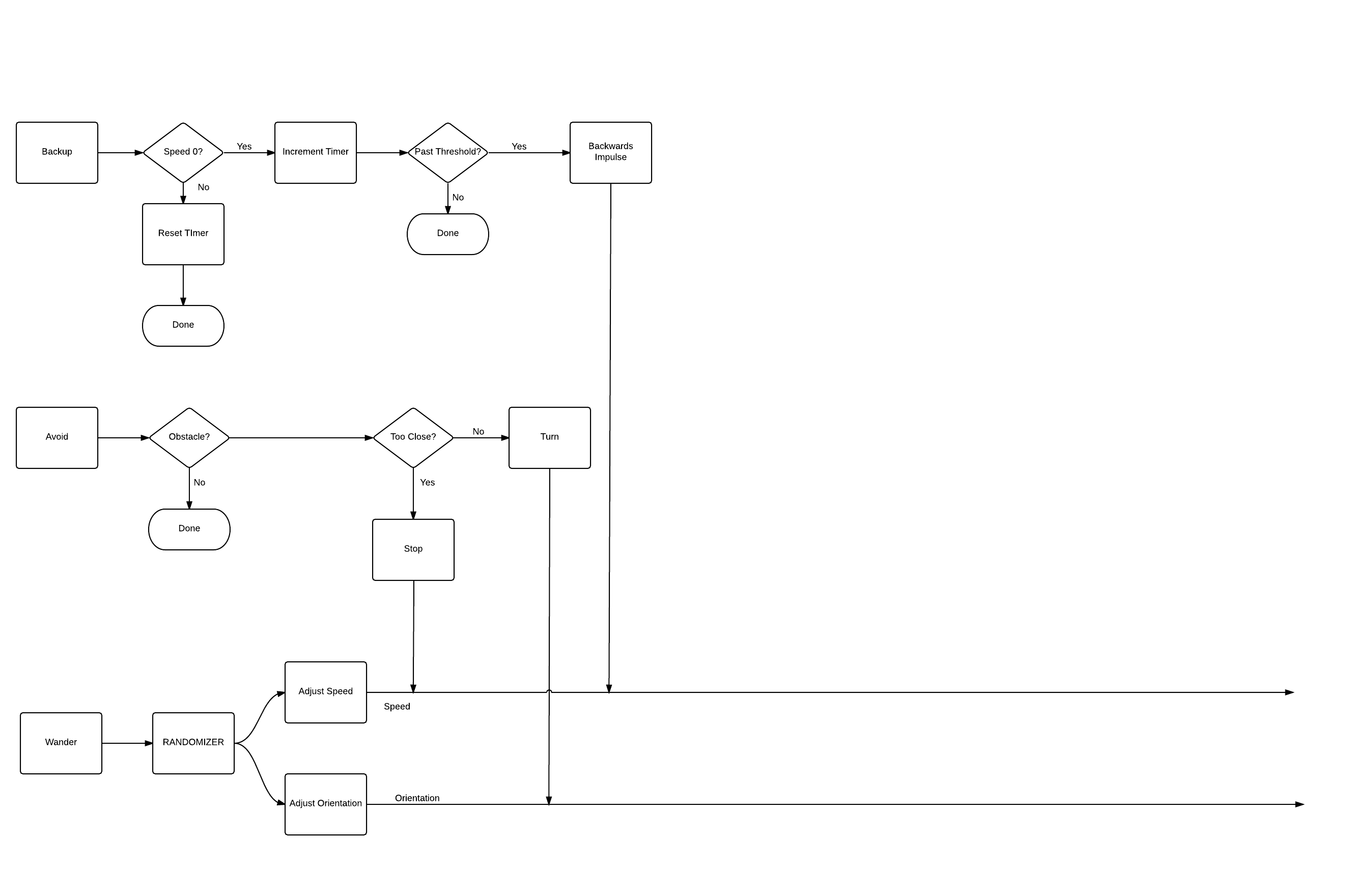
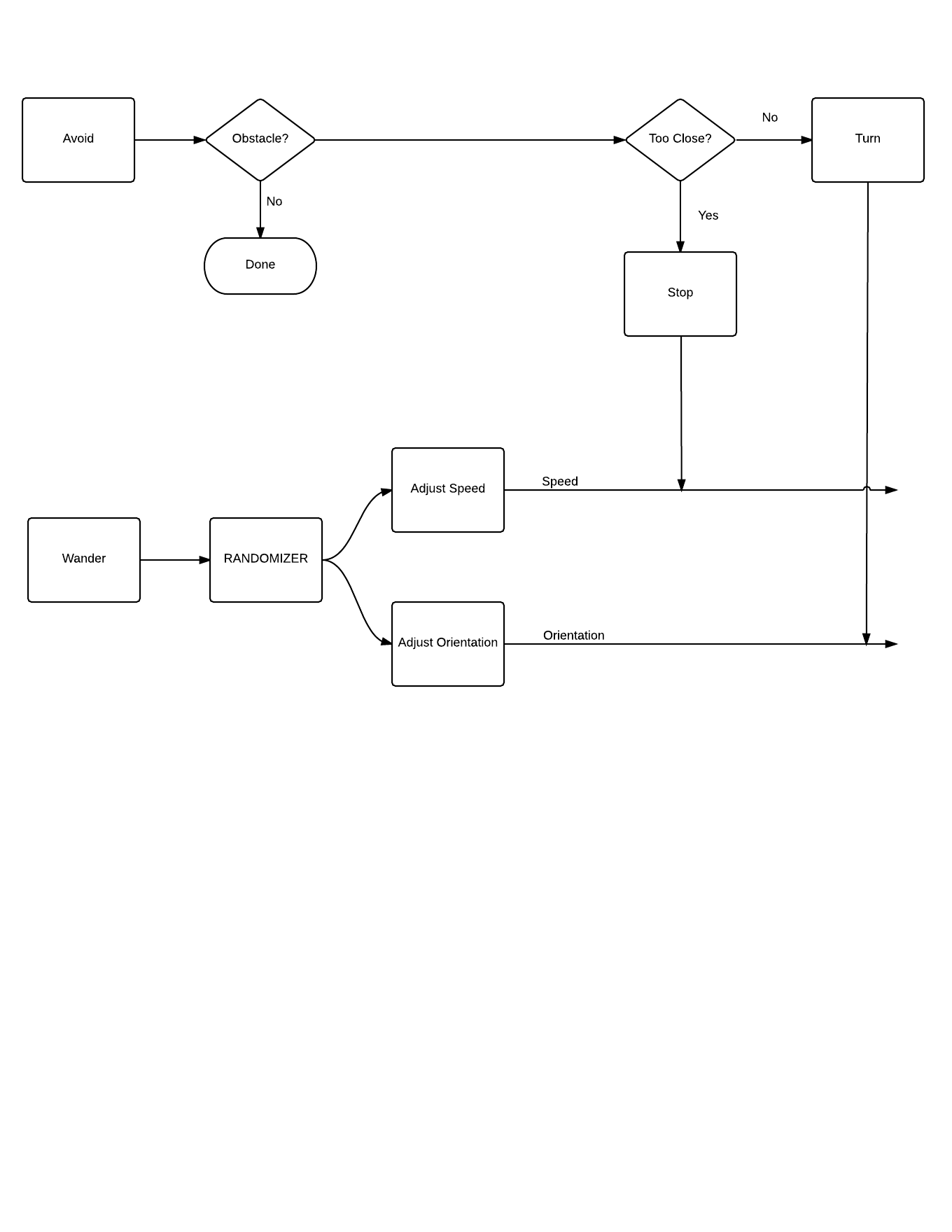
In order to ensure that the individual members of the swarm are in principle physically realizable machines I am modeling them off a real world robotics approach first suggested by Dr. Rodney Brooks. The behaviour of drone is modeled to simulate a "subsumption" approach. In this approach the machines will have different sets of behaviors which can subsume lower level behaviors. The simplest example of this will be the wander / avoid behaviors.
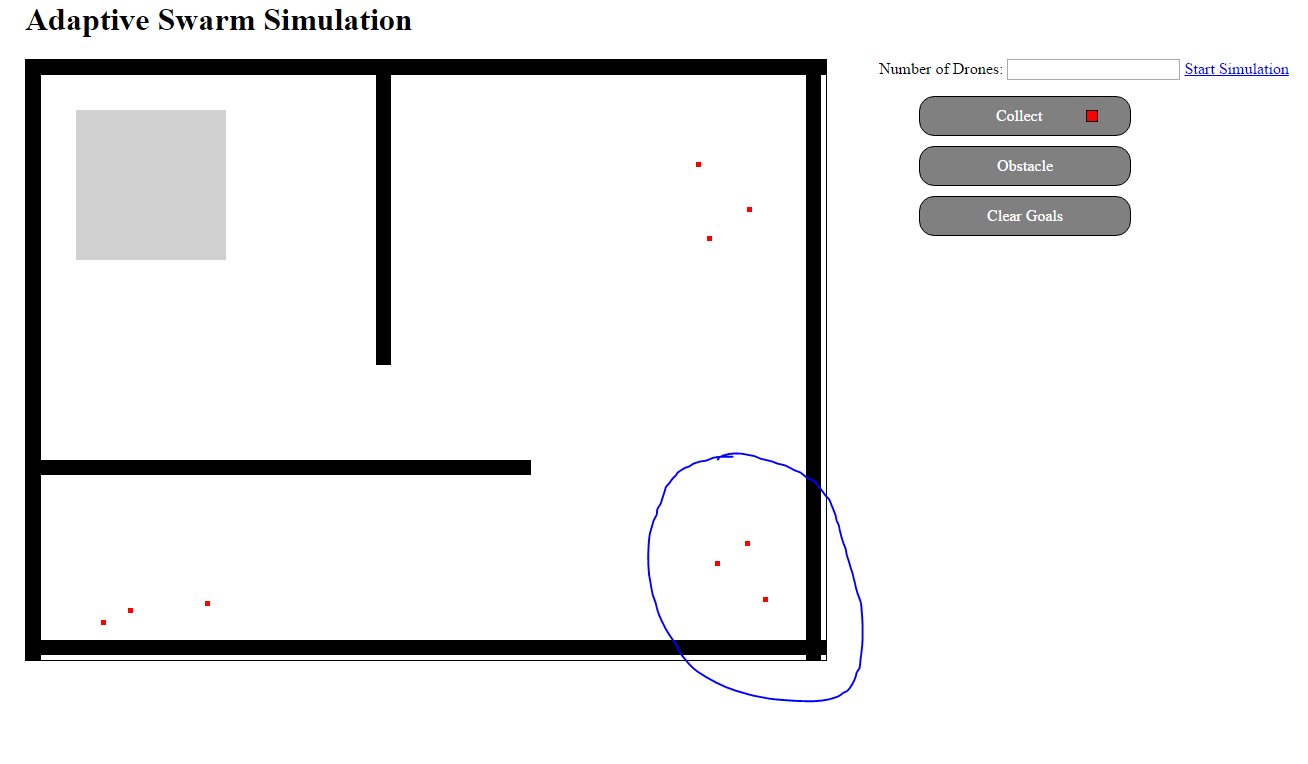
In the wander behavior machines will randomly move about the environment - searching for something to do. Avoid behavior moves the machine away from any obstacles in the environment. Rather than altering the course directly, the avoid behavior simply overwrites the output of wander any time an obstacle is in play. This will be made more clear in the diagrams I've included in the logs (and future ones as I modify the design).
Control of the swarm will be done by means of settings Goals. In the first stage these goals will merely be positions in the environment that must be visited by at least one individual. In a real world application these goals would either be preset before the start of the simulation, or broadcasted in realtime as the user clicks on their interface.
Each virtual drone is assumed to have some minimum equipment available.
- Distance sensors (for example any $10 Ultrasonic range sensor) suitable arranged around the exterior for obstacle detection.
- A radio / other wireless communication device for communicating with other drones. (This can also be used for receiving goals from some central computer).
- Some form of locomotion.
- An optional camera/other detector for recognizing goal materials / collecting images.
- An optional gripper for collect / deposit type goals.
- Any optional equipment that might be useful for a time related task. For example firefighting drones may have an additional add on for fire suppression.
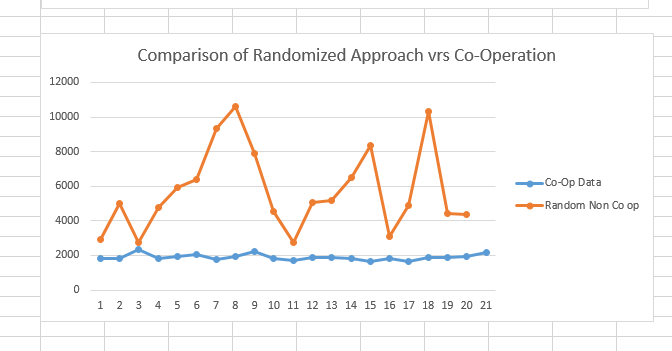
Co-operation among members of the swarm will be achieved by the use of a signal behavior built into each machine. This will allow each machine to compare its stored state with the signals provided and decide if it should relinquish a specific task to a better suited member of the swarm (and thus go back to wandering), or take on the task itself.
Subsumption will be used in combination with the signal behavior for more complicated choices involving tasks. For example tasks that have a pre-requisite such as drop the box on the floor at the given point would override the machine from accepting the drop task in cases where it has not yet picked up the box.
Simulation will be built and tested in stages. Stage 1 is currently complete.
- Basic subsumption system for simple goals.
- Introduction of complex environments for simple goals.
- Complex Goals.
- Simulated failure of various subsystems on random drones.
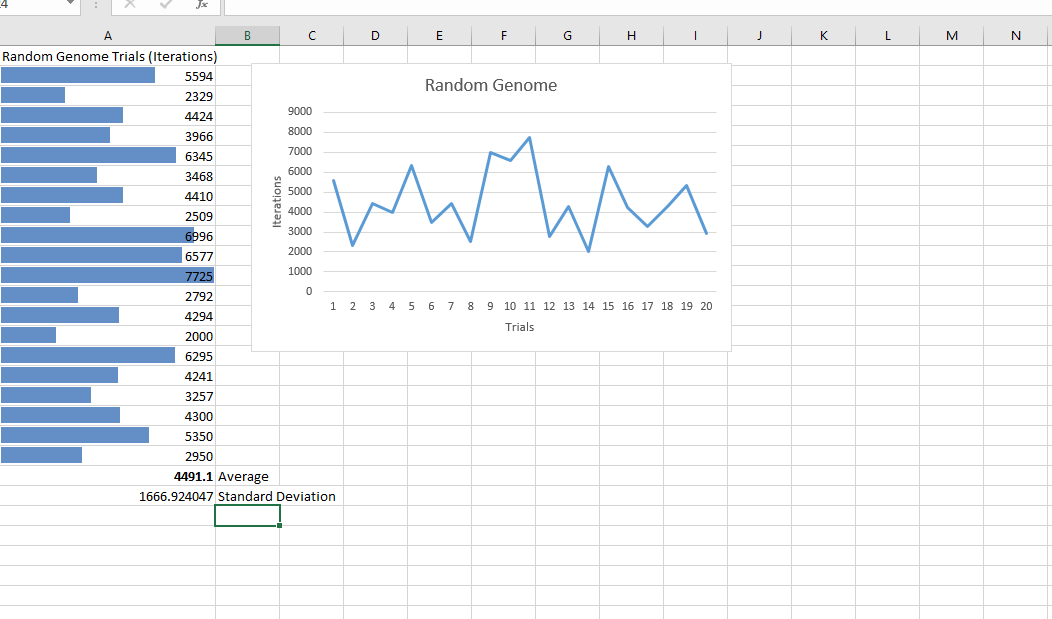
- Examination of the different behaviors as I vary the parameters both globally for all drones, and by choosing random parameters for each drone.
As this is a simulation certain simplifications are being made.
- Noise is being ignored. Real robots experience noise in both their actuators, and detection systems. To save computational resources I am ignoring this. Methods for dealing with noise in robotics applications exist - notably the field of Probabilistic Robotics - and may need to be considered when building real world models....



 Crypto [Neo]
Crypto [Neo]
 Dimitar Tomov
Dimitar Tomov
 Chuck Buckley
Chuck Buckley
 int-smart
int-smart