 Jack Qiao
Jack QiaoGoals
- The robot should autonomously navigate, avoid obstacles and interact with objects using a gripper.
- Aside from an initial mapping phase, not require teleoperation or manual user input.
- Be multi-purpose, performing a number of common tasks
License
BSD license on the code and design files unless otherwise specified (eg. apriltags nodelet is GPL)
Overall design
The core function of the robot is to move objects from one point to another. The object may be a target to be transported or a tool that performs some task (eg. a cleaning pad, dusting tool etc). The robot should contain the minimum hardware required to accomplish this.
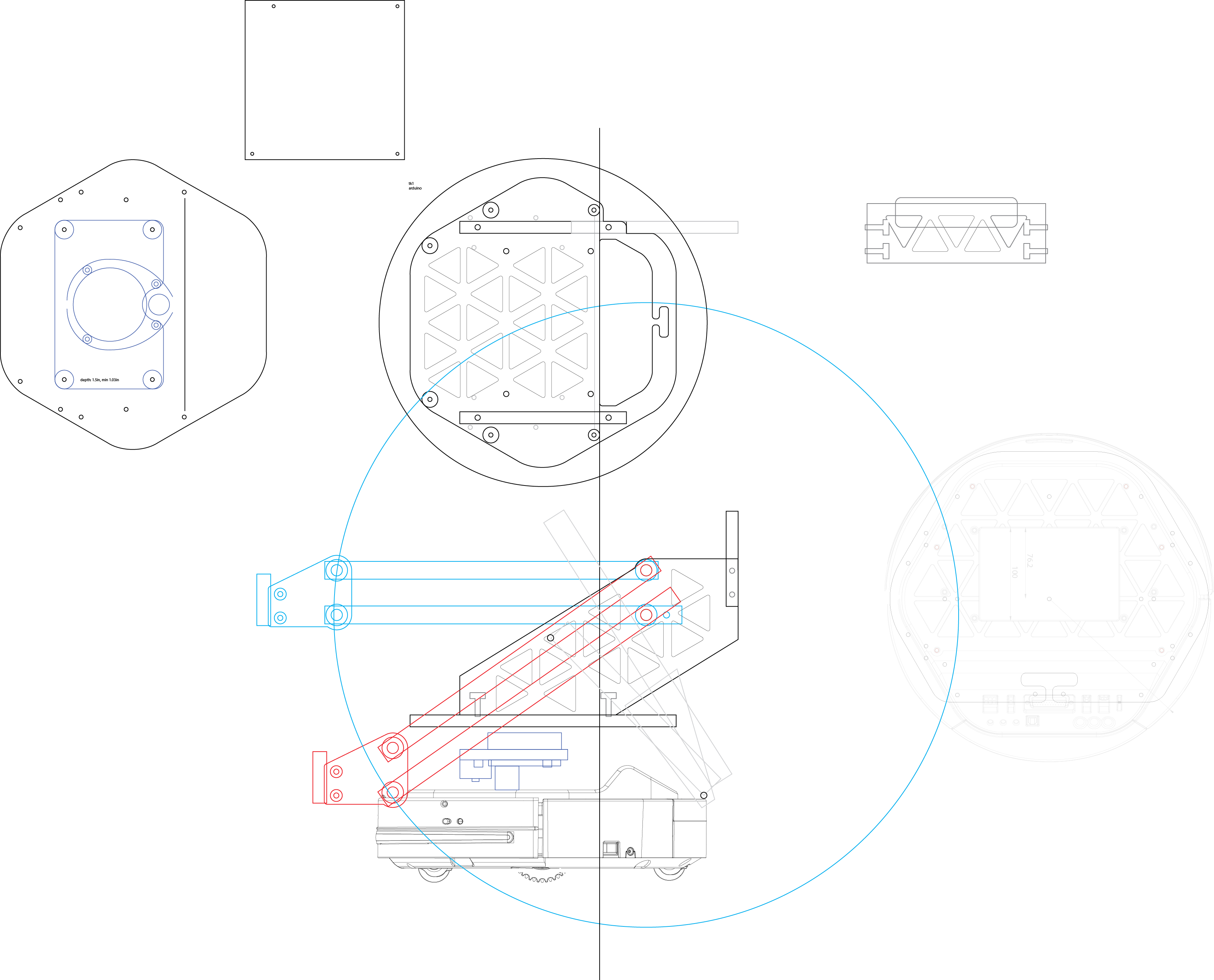
Mechanical design
I'm using a single DoF arm and simple planar gripper. This has a few advantages over more complex arm/gripper setups:
- can be produced fairly cheaply using 3d printers
- no need for complex inverse kinematics
- reduces flex from joint backlash, higher load capacity, lower weight
The depth camera is mounted at the back to minimize its detection deadzone. As a result, the body of the robot is wedge-shaped so that when the arm is lowered the camera has an unobstructed view. The right side of the robot has a triangular tessellation pattern, this is to somewhat offset the increased weight on that side due to the arm.
Hardware
I've experimented with several iterations of hardware setups and settled on this:
- neato xv11 LIDAR for localization
- intel realsense R200 depth sensor. This provides a depth stream for object detection as well as a 1080p RGB stream to detect fiducials
- Nvidia Jetson TK1 as the main computer. This board has CUDA support, which makes it much easier to deal with computer vision
- Kobuki base robot platform. This is the same base used by the Turtlebot. The base provides gyro, odometry and other sensor output through its USB interface, which runs ROS right out of the box.
- Arduino uno to drive the arm/gripper. Although the TK1 technically has GPIO, linux is not a realtime OS and not really suited to driving motors with PWM.
- Actuonix/Fergelli P16 150mm 22:1 linear actuator to drive the arm
- Polulu VNH5019 motor driver to drive the linear actuator
- MXL AC-404 microphone. I got this one mainly because of the recommendation from the ROS website
Software
I used ROS for the software framework. Most of the really difficult problems for this project has already been solved by various ROS packages. Here are the stock ROS nodes that I used, along with the high-level task that it performs:
gmapping - build a map of the environment using SLAM
robot localization, AMCL - localize within the map via sensor fusion of LIDAR data, wheel odometry and gyro readings
ROS navigation - plan a path to a waypoint on the map
RTAB-map obstacle detection - detect obstacles and plan around them
pi_trees - behaviour tree implementation for high-level decision making
pocket sphinx - speech recognition
and many others.. check out the launch file on github for more.
There are some tasks for which no off-the-shelf package exists, or requires refactoring for speed improvements. In these cases I wrote my own ROS nodes:
gpu_robot_vision - uses the TK1's GPU to perform simple CV tasks, including: image rectification, BW/color conversion, scaling and noise reduction filter
apriltags_nodelet - a nodelet that outputs a list of fiducial markers from the rectified and denoised RGB stream
april_tf - takes those markers as input and outputs the same markers transformed in the map frame. Persist observations by writing them to a file, and outputs a target pose for ROS navigation to plan a path to the marker
april_planner - issue precise movements to the robot based on the relative movement of the detected markers
depth_object_detection - this is mainly used to detect my hand, to open/close the gripper
Installation
- get a spare machine and install ubuntu 14.04
- flash your TK1 and ensure wifi is working
- load custom kernel with UVC for the realsense
- install ROS and realsense drivers (install ROS indigo)
- install these ROS nodes (available via...
Read more »











 EK
EK
 Ted Huntington
Ted Huntington
 Piotr Sokólski
Piotr Sokólski
 maks.przybylski
maks.przybylski
Most impressive work done! Your BunnyBot should do quite well in the commercial market. Awesome demonstration shown on the video. Thanks.