Yann Guidon / YGDES
Yann Guidon / YGDES-
Fuzzing and safety
03/22/2024 at 01:14 • 0 commentsThe aligned format is great, while it remains used inside a safe and controlled context.
It can get ugly though when an "aligned string" pointer is transmitted through an untrusted piece of code. This unsafe code could be prevented from dereferencing the string's value but this is not enough. If the pointer itself is modified, all kinds of problems arise.
Receiving a pointer to an aligned string from a dubious source can be less dangerous if the type is restricted. The type 2 (16-bit length) is the safest and it's easy to filter. The Type 3 creates indirect (de)references and the flexible types should be cast back to constant strings (it might not be possible to modify or reallocate the target anyway).
Use Type 2.
-
More than an error
03/11/2024 at 03:04 • 0 commentsType 0 is NULL/Error and detected from the three LSB.
But the remaining MSB are not checked...
So if the MSB are not cleared, this could lead to yet another type, 8-byte aligned. What could it be ?
-
Another possible extension
09/25/2023 at 01:12 • 0 commentsThe recent article Faster String Processing With Bloom Filters got my attention. It refers to https://codeconfessions.substack.com/p/cpython-bloom-filter-usage. And I thought: What if...
It is possible to create a larger structure that contains an even larger field, to hold either a Bloom sieve or a hash/signature, for 2 use cases : sub-string search or string matching. For example, if a string is determined to be tested for equality at some later point, a programming language / Compiler would "tag" the string so the hash is created once the value is assigned. Then the actual test becomes a simple scalar value comparison, followed by a real comparison in case of a hit, which might save some CPU cycles when misses are likely.
Similarly, before performing a sub-string search, the strings (possibly many, again) can be pre-processed so only the 64-bit Bloom filter is used at first, to sieve candidates faster than the naïve method.
However, with already 3 LSB used, such an extension is impractical. The memory losses from alignment might become ridiculous. The hash or sieve values would be handled by the programmer, case-by-case at first, in a separate structure.
And speaking of hashes, I might have another trick up my sleeve, look up #PEAC Pisano with End-Around Carry algorithm !
-
Article !
07/01/2023 at 17:25 • 0 commentsI have published a thorough article on this subject in GNU/Linux Magazine France: "Sus à l’ASCIIZ, vive les chaînes alignées !" in March 2023, with a summary of all the design decisions and more.
![]()
-
More food for thoughts
01/17/2023 at 02:59 • 1 commentI have to credit @Gravis for challenging me in the comments. Even though it does not go in the direction he seems to want, feedback is progress and this has brought some indirect useful bits. Even though the broad lines are defined, there are still details to perfect.
A quirky little detail I didn't properly consider before is how to manage or handle the NULL value. It belongs to the type 0 so the 2 LSB are cleared. There is no incentive to swap it with type 3 again, as type 0 is not dereferenced (so no risk of a NULL pointer crashing the program) and type 3 has an easy mask-based routine to fetch the total length up to 24 bits.
However type 0 gives code points and NULL translates to a character of value 0. This potentially causes confusion in cases where a pointer is returned as an error code, like malloc() failing. It shouldn't insert a 0 in the stream (eventually a Unicode glyph that says "error").
Furthermore a "placeholder" value is defined to indicate that the entry in the list must be skipped. Currently this is defined as value 4 (100b).
Something has to be shuffled around to make the whole thing safer. It is easier to re-attribute the less-used placeholder value, giving the following table :
Attribution MSB other bits b2 b1-b0 NULL 0 00 Unicode point (including value 0) 0 Unicode value 1 00 Placeholder / skip marker 1 1 00
The value of the placeholder/skip can now be -4 because Unicode values can't affect the MSB.I don't know yet how to display a NULL value. Maybe ⚠ - U+26A0 - ⚠ ? The Replacement character U+FFFD � is already used for a different purpose and should be avoided to prevent confusion. U+1F6AB 🚫 or U+1F5F2 🗲 could also represent an error.
The summary of this change is below:
![]()
Type UP means "Unicode Point or Placeholder". Now let's transform the specification into working code.
-
Holding back a bit
01/13/2023 at 03:02 • 0 commentsThese have been awesome 2 weeks of development and maturation of this project that languished for 2 years already. I now have to take a step back for a while because it uncovered another C flaw that is at least as important.
So I just started another project #A software stack..
It will help with dynamic allocation without a garbage collector for a lightweight framework. This will in turn solve quite a few issues with memory allocation I encountered during the design of this code.
I'll have to implement the lists (type 3) (it's pretty easy now since merge() implements most of the logic already) and some printf-like features (school-level number conversion stuff) but they'll depend on the above stack mechanism, so be patient. Meanwhile, enjoy AS20230112.tgz !
-
Merge works
01/10/2023 at 13:53 • 0 commentsI just uploaded a new version ! AS20230110.tgz can now merge strings of types 1 and 2, even multiple in a row. This involved solving many programming challenges and overcoming the reticence of the compiler. For example, declaring and allocating a string is a crazy mess and it is still far from perfect.
But the basic features are functional. -
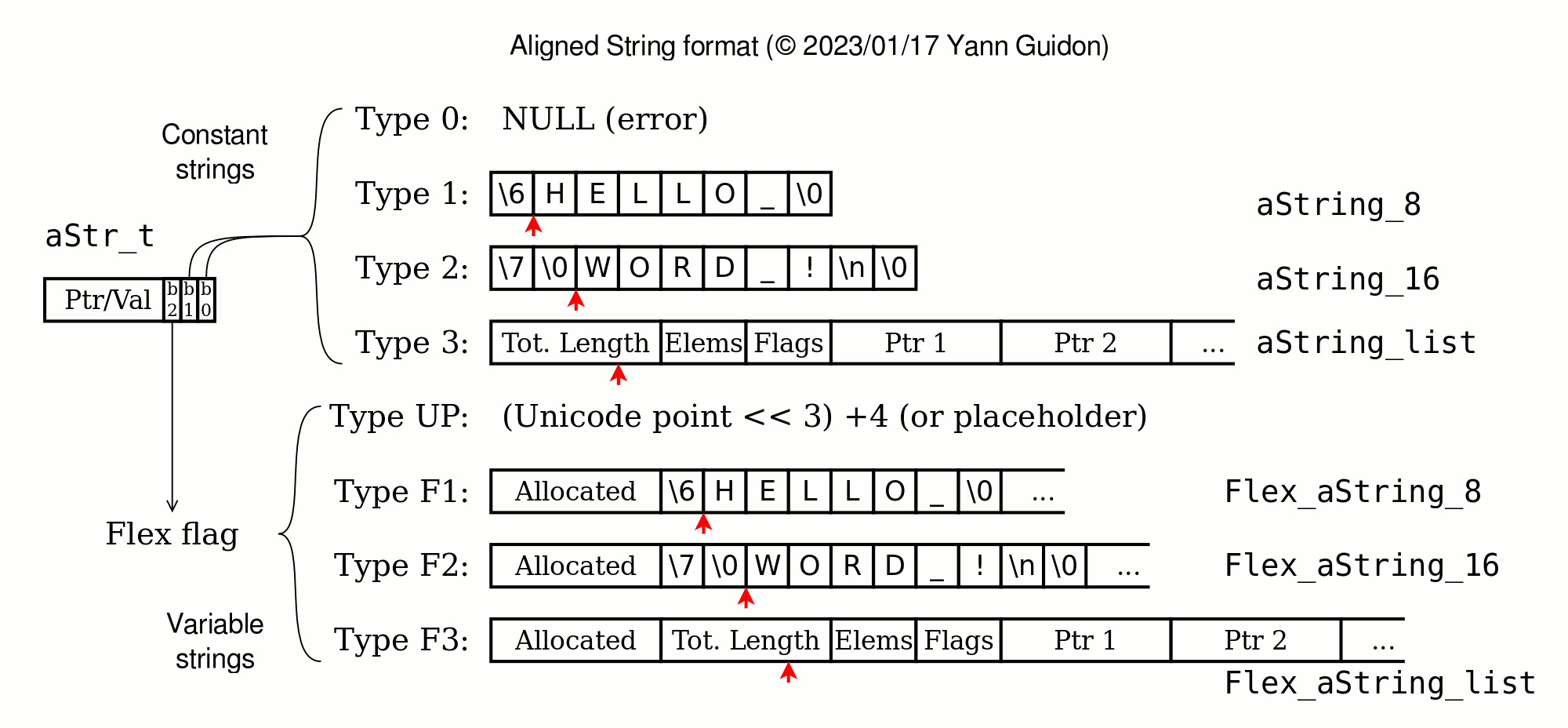
Evolution...
01/09/2023 at 18:15 • 0 commentsProgress is strong these days.
I shuffled things around : types 0 and 3 are swapped so optimised code can more easily read the size of lists.
The Flexible strings are also adapted a bit.
The whole thing is now defined as a "descriptor" or "handler" type, called aStr_t and declared in C as uintptr_t
As a result we get this new map :
![]()
Type F0 is undefined and should be congruent with type 0 "points".
I uploaded the latest aligned_strings.h here.
I now move on to implement the required support functions.
-
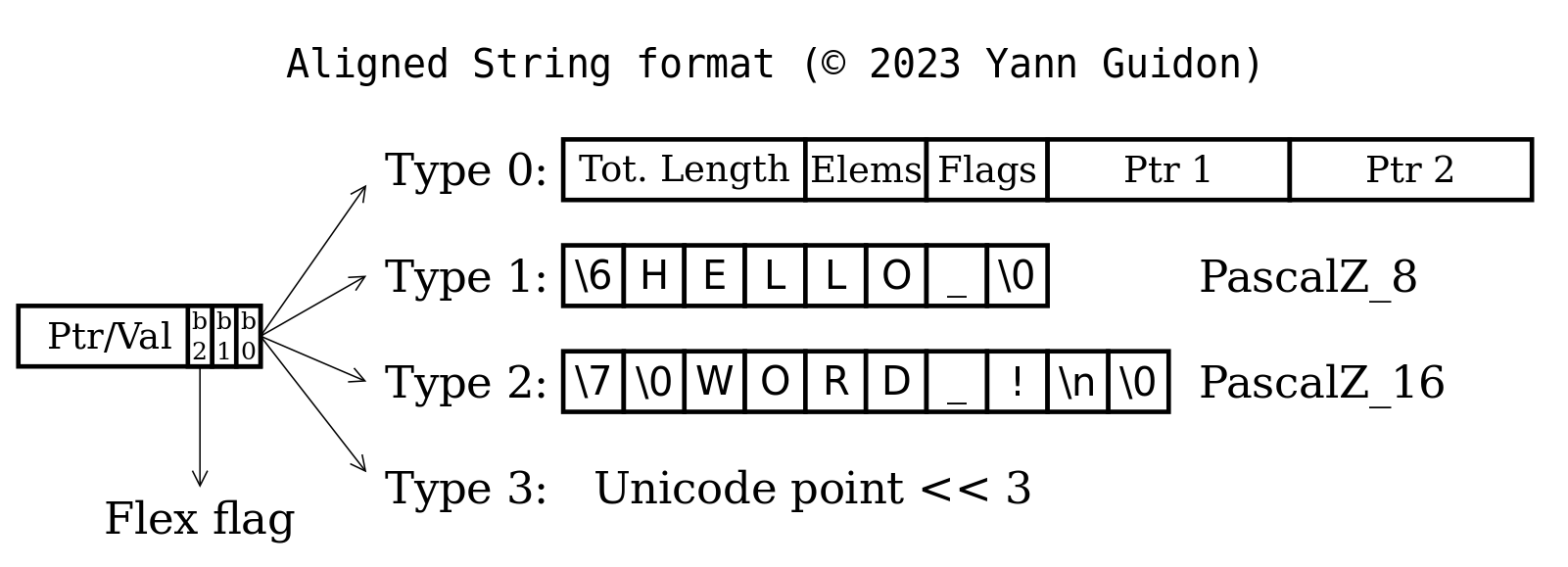
2023 : a new version
01/04/2023 at 17:40 • 0 commentsI have explored the whole system again these last days and came to a new definition and allocation. So you can scrap parts of the 2 year old versions and take this instead:
![]()
We have new and refined features, such as an optional "Flexible" flag and a direct Unicode point (shifted) to be used in the type 0 lists !
I have uploaded a first definition at PascalZ.h though it's still preliminary.
-
Context
05/19/2020 at 16:31 • 0 commentsAny technology has a "preferred" or "appropriate" application domain/range. The aligned string format has been thought to address needs that arise when dealing with ASCII-Z strings during mundane operations, mainly POSIX API and other low level operations that must remain lightweight.
It is meant to be "somewhat" compatible with POSIX but would ideally replace it (if I had the chance to redo it all over). This is why the trailing NUL is "optional" : recommended for ease and compatibility for working with Linux for example, but would be dropped in later implementations.
It is not meant as an internal representation format for language because memory management is not considered (though it could be used when encapsulated with pointers, reference counts and other necessary attributes)
The fundamental element is the 8-bits byte, or uint8_t in today's C. This deals with ASCII and UTF-8 only. But since the proposed format deals nicely with NUL chars inside the string, this is not inherently limited to text.
The "lightweight" aspect is important : the code must run on microcontrollers (where the usual POSIX string.h is considered a nuisance)
The most frequently used string function is xxprintf() which internally often performs string concatenation with variable formats. Otherwise we would use write() directly, right ?
strlen() is a nuisance : it shouldn't have to exist, at least as an O(n) function.
To prevent buffer overflows, sprintf() must not be used when coding defensively (the default approach, normally). This is why we have the snprintf() variant and its siblings, but they give the result after the fact ! So we must allocate a potentially large buffer, check the result and eventually resize the buffer. If we had the length before the concatenation, we would check early for overflow then directly allocate the right buffer size.
Concatenation is one of the most frequent operations on strings because we often need to join several fields to create a message, for example to display the respective value of several numbers or even build the header of a HTTP packet.
Wikipedia describes many operations :
- 2.1 Index ...
- 2.2 Concat ...
- 2.3 Split ...
- 2.4 Insert ...
- 2.5 Delete ...
but their significance differs substantially from a text processor for example. The typical POSIX functions perform them with close O(n) costs but a binary tree structure is naturally a more appropriate higher-level representation. This is why the aligned strings are only the lower layer of a string system and only few operations are performed on them (those that allow the above list to be implemented).
To conserve memory and speed, operations must be performed in place as much as possible. Moving blocks around is painful. With the aligned strings, it's even more important because the alignment is critical. Fortunately it is easy to re-align the start of a string by splitting it and fixing/using the appropriate alignment and size in the small prefix block that is generated.
Str8 and Str16 are a subset of the 4 possible LSB codes. If we want to design a practical binary tree system, the pointer itself must say if it points to a node or a leaf... so we then have 2 variants :
- aligned aStr8 and aStr16, that can also encode aStr24 and aStrNode
- unaligned uStr8 and uStr16 that may not be directly pointed to by aStrNode in one half of the cases. If there are 2 unallocated bytes in front of a uStr8, the prefix can be turned into aStr24, otherwise the string would be realigned with a split and the pointer would point to a aStrNode that points to the moved first part and the remaining part of the original string.
The difference between aStr and uStr is only at the syntactical level because the representation is the same but it prevents confusion and hints the type checker of the compiler that there is a potential incompatibility (that can be bypassed by a cast if needed).
To be continued...
...
Aligned Strings format
Developing a more flexible pointer and structure format that keeps some POSIX compatibility without the hassles