 Yann Guidon / YGDES
Yann Guidon / YGDES Dr. Cockroach
Dr. Cockroach Alex
Alex Arya
Arya Morning.Star
Morning.Star-
LibreSOC & TinyTapeout pictures @FSiC2024
06/23/2024 at 01:36 • 6 commentsWe talk a lot about architectures and semiconductors.
At the FSiC2024 conference in Paris, I saw real integrated circuits and took pictures, including TinyTapeout chips and the LibreSOC samples/prototypes.
I have uploaded some of them on Wikipedia to contribute to the Libre-SOC page.
![]()
![]()
![]()
And here Thorsten showing some TT samples in bare die and QFN package.
![]()
![]()
And one board demonstrated by @matt venn !
![]()
.
-
More operator symbols
11/24/2023 at 14:51 • 0 commentsTo say that I am frustrated by the vocabulary of some common languages is an understatement. JavaScript introduced the ">>>" symbol for the arithmetic (sign-preserving) shift but we're still far from satisfaction.
The Pascal family of languages don't bother with such details because operators use all-letters operators : sll, shl... But the C-like syntax is preferred today so I need to be creative.
Carry-related operations are traditionally absent, which is a shame. So let's skip directly to the rotations : there is no direct symbol for this, but I have long wanted to modify the shift symbols:
<<@ rotate left >>@ rotate right
Or maybe a shorter version:
<@ rotate left @> rotate right
which is less effort than having to analyse the syntax tree and look for a compound operation (OR of two SHIFTs with the same arguments and the shift amounts sum up to 32 or 64).
Now there is an even trickier symbol to choose : I need UMIN, UMAX, SMIN and SMAX (unsigned and signed minimum and maximum) The < and > symbols will be used but how to discern between signed and non signed operations ?
<? MIN ?> MAX
The Dollar symbol looks like a S so
<$ SMIN $> SMAX
could do the trick.
Any advice or prior art is welcome !
-
Addendum ABCE
09/26/2023 at 06:43 • 0 commentsI have covered permutations of control signals in binary trees many years ago, I have even published 2 articles:
And I recently became aware that I am only a rediscoverer, as there are 2 patents:
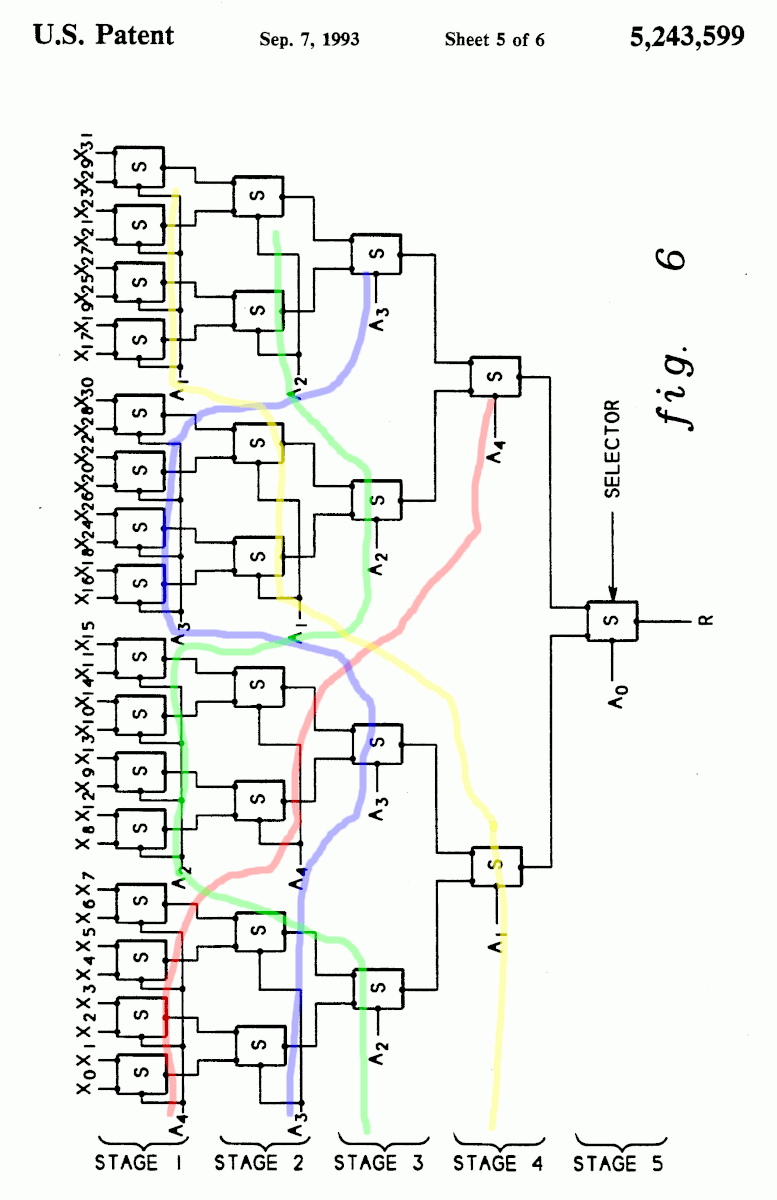
https://patents.google.com/patent/US5243599A/en by IBM, expired in 2011
"Tree-type multiplexers and methods for configuring the same"
Figure 6 is clearly a balanced tree (32 leaves, 1,7,7,8,8 configuration)
![]()
https://patents.google.com/patent/US20120194250 AMD, seems identical but expires in 2031 ???
I have not been able to understand the difference between the two patents but this would explain why the technique has not appeared on my radar before : who wants to walk on IBM's toes ? However its validity is gone since a dozen years now so why restrain ourselves ?
Addendum to the addendum :
https://arxiv.org/abs/2405.16938
https://arxiv.org/abs/2405.16968
The subject is still alive !
My Projects
Projects I Contribute To
My Pages






Things I've Built
1KW LED lighting
2006: I designed and built all the electronics of a store's architectural element. 432 3W Luxeon LEDs split in 9 sectors with independent dimming with my first HTTP-based remote controller...
Lambda
LED desk lamp concept design. 2008
Drosephyia
Working as SubFlower, Igor & I built a sort of electronic plant in 2005 for an exhibition at Biche de Bere art gallery.
Projects I Like & Follow
 Vijay
Vijay Kn/vD
Kn/vD Peter
Peter Marcin Saj
Marcin Saj Joël de Kanter
Joël de Kanter Mitsuru Yamada
Mitsuru Yamada Paul Kocyla
Paul Kocyla Andrey Kalmatskiy
Andrey Kalmatskiy SHAOS
SHAOS Dave Collins
Dave Collins Tim
TimShare this profile
ShareBits

Hey !!!
thanks back roelh :-)
I thought it was way over 9000 ;-)

Thank you for liking, following and my #CMOS Homemade Operational Amplifier ! The offset adjustment is subtle, but ultra-high input impedance characteristics have been achieved. I am planning to conduct further operational experiments from now.
You're welcome ! I appreciate your works a lot !
Thank you for following me ! Recently, while verifying an application for calculating the position of a planet with a homemade floating-point interpreter, I found a case where the calculation stack operation was incorrect, so I updated the interpreter's code.

Hi Yann,
Merci for liking and following #MINITEL + ESP32 :))
Thank you for liking and following my #Homemade Operational Amplifier !
You're welcome !
You made me want to try this with Germanium transistors ;-)
This one looks pretty good: http://abload.de/img/je-918_documentation_9ab6k.jpg
That's a good idea! Please let me know if you get any results.

Thanks for following #But How Do It Know? 8-bit CPU Build !


Hey Yann, Thank you for the follow/like of #Starburst :-)
Thank you kindly Yann for the like/follow for #LLTP - Light Logic Transistorless Processor :-)
Like LEGO, synth design is something i'll never be able to rid my brain of.
IKR, I wake up sometimes after dreaming of stuff like this ;-)

You're welcome !
Designing crystal oscillators is a kind of dark magic so any help is welcome :-)

Hi Yann, thank you for liking and following the #Kobold K2 - RISC TTL Computer !
Hi Yann, thanks for liking and following the Kobold computer project !
Yann, thanks for re-liking #1 Square Inch TTL CPU. Did you see my new Kobold computer project ?

Damn, do I have to build EVERYTHING myself? :-D
Thanks for another, #The House Of Fun

Hi Yann, I'm glad my project #RELAY COMPUTING is of interest to you. I hope you will find my project #SANX-I MICROCOMPUTER interesting as well. Best regards, Javier
Hey there Yann, thanks for the Christmas Like and I feel that the new year will be great for all of us :-D Yes the scope will be a big player to my fun and learning in 2019 :-)
Hi Yann, thank you for following and liking my project #Isetta TTL computer ! Did you notice that you are following 1001 projects (or is that binary) ?