 lion mclionhead
lion mclionheadAfter years of waiting for Nvidia confusers to come under $100, the cost of embedded GPU's instead rose to thousands of doll hairs, putting embedded neural networks on a trajectory of being permanently out of reach. Both goog coral & Nvidia jetsons ceased production in 2021.
Theories range on why embedded GPUs went the way of smart glasses, but lions suspect it's a repeat of the "RAM shortages" 40 years ago. They might be practical in a $140,000 car, but they're just too expensive to make.
If embedded neural networks ever become a thing again, they'll be on completely different platforms & much more expensive. Suddenly, the lion kingdom's stash of obsolete single board confusers was a lot more appealing.
Having said that, the lion kingdom did once spend $300 on a measly 600Mhz gumstix which promptly got destroyed in a crash. Flying machines burned through a lot of cash by default, so losing $300-$500 on avionics wasn't a disaster.
The fastest embedded confuser in the lion kingdom is an Odroid XU4 from 2015. It was $100 in those days, now $50. It was enough for deterministic vision algorithms of the time but not convolutional neural networks.
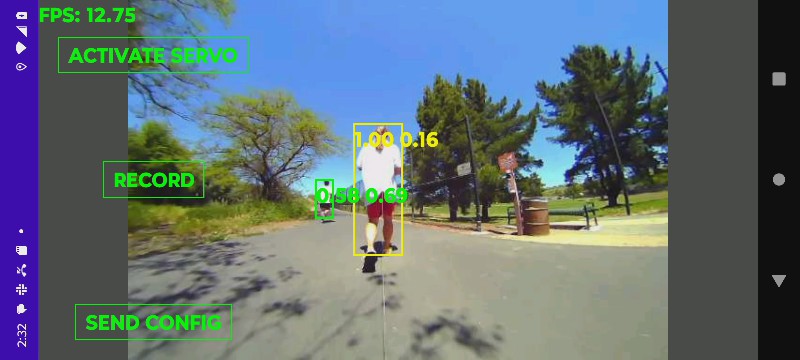
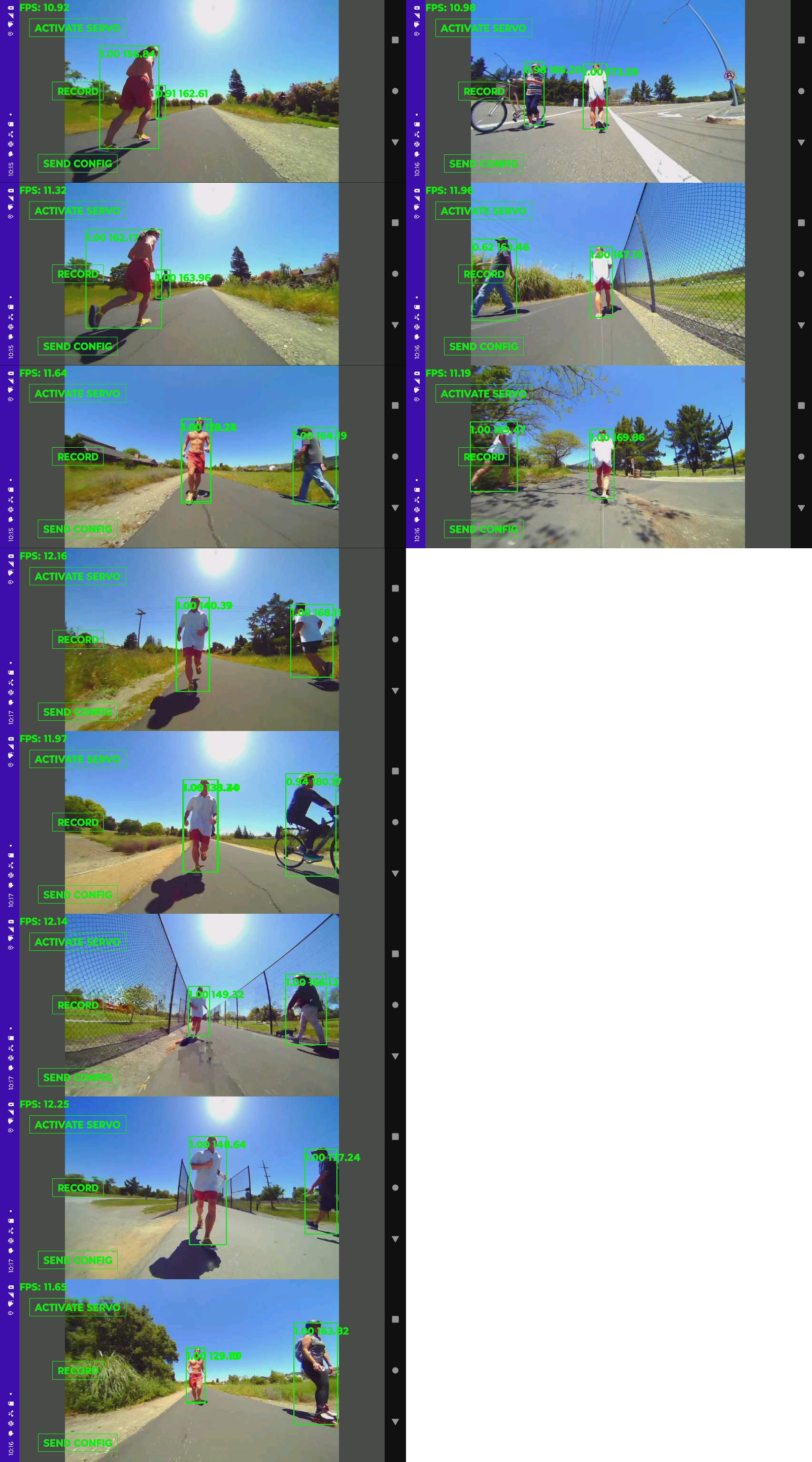
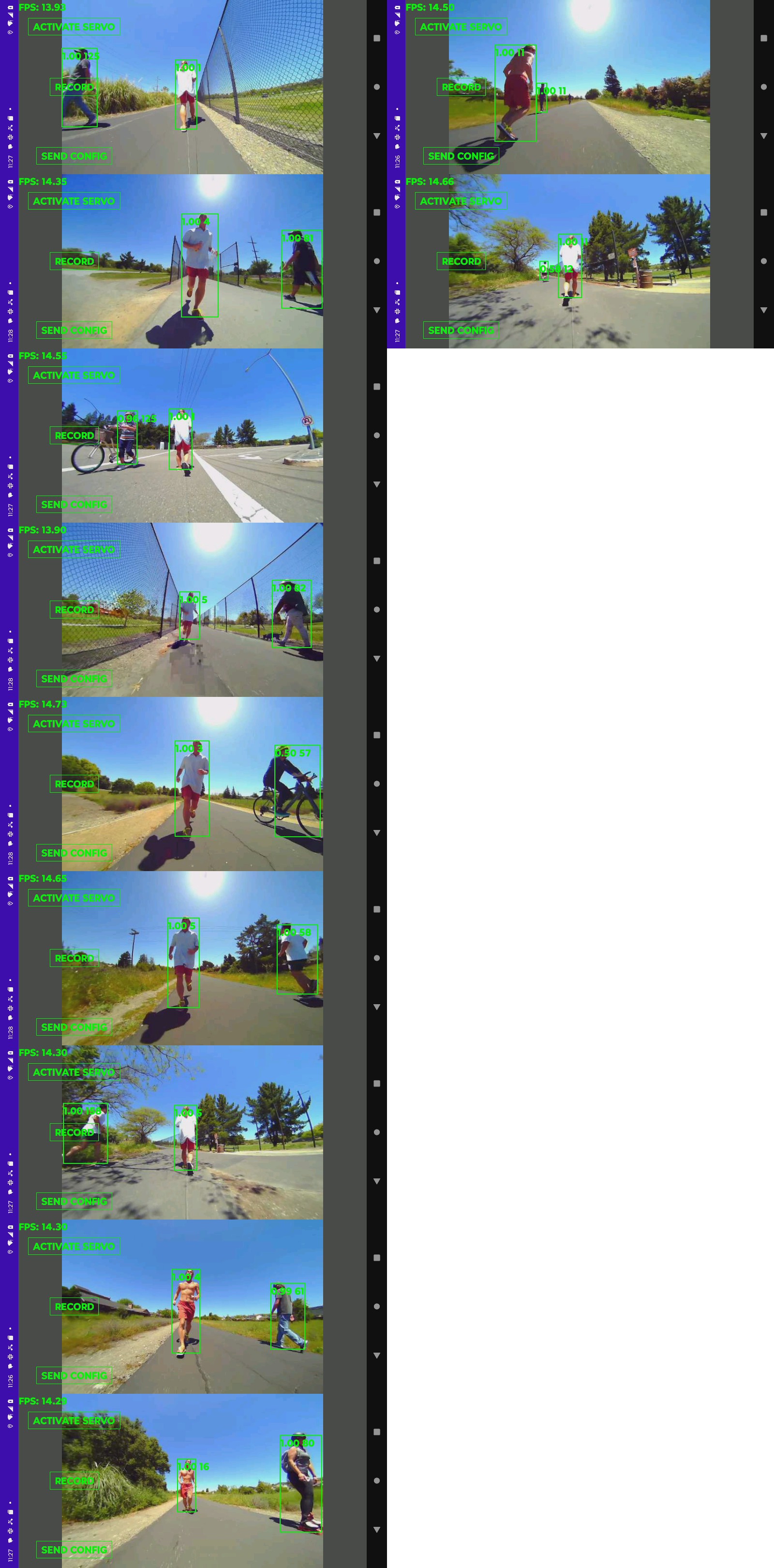
No-one really knows how a Skydio tracks subjects. No-one reverse engineers anymore. They just accept what they're told. Instead of tracking generic skeletons the way the lion kingdom's studio camera does, a Skydio achieves the magic of tracking a specific person in a crowd. Reviewing some unsponsored vijeos,
it does resort to GPS if the subject gets too far away, but it doesn't lose track when the subject faces away. It's not using face tracking.
The next theory is it's using a pose tracker to identify all the skeletons. The subject's skeleton defines a region of interest to test against a color histogram. Then it identifies all the skeletons in subsequent frames, uses the histogram to find a best match & possibly recalibrates the histogram. It's the only way the subject could be obstructed & viewed from behind without being lost. The most robust tracker would throw face tracking on top of that. It could prioritize pose tracking, face matching, & histogram matching.
The pose tracker burns at least 4GB & is very slow. A face tracker & histogram burn under 300MB & are faster. Openpose can be configured to run in 2GB, but it becomes less accurate.
The lion kingdom had been throwing around the idea of face tracking on opencv for a while. Given the usage case of a manually driven truck, the face is never going to be obscured from the camera like it is from an autonomous copter, so a face tracker became the leading idea.
There are some quirks in bringing up the odroid. The lion kingdom used the minimal Ubunt 20 image.
ubuntu-20.04-5.4-minimal-odroid-xu4-20210112.img
There's a hidden page of every odroid image
https://dn.odroid.com/5422/ODROID-XU3/Ubuntu/
The odroid has a bad habit of spitting out dcache parity errors & crashing. It seems to be difficulty with the power supply & the connector. The easiest solution was soldering the 5V leads rather than using a connector.
That gives 4 cores at 2Ghz & 4 cores at 1.5Ghz, compared to the raspberry pi's 4 cores at 1.5Ghz. The odroid has only 2GB of RAM compared to the pi's 4 GB.
In recent years, ifconfig has proven not a valuation boosting enough command, so the droid requires a new dance to bring up networking.
ip addr add 10.0.0.17/24 dev eth0
ip link set eth0 up
ip route add default via 10.0.0.1 dev eth0
Then disable the network manager.
mv /usr/sbin/NetworkManager /usr/sbin/NetworkManager.bak
mv /sbin/dhclient /sbin/dhclient.bak
There's a note about installing opencv on the odroid.
https://github.com/nikmart/sketching-with-NN/wiki/ODROID-XU4
The only opencv which supports face tracking is 4.x. The 4.x bits...
Read more »




















































 Tim
Tim

 Nick Bild
Nick Bild