lion mclionhead
lion mclionhead-
efficientdet_lite0 vs face tracking
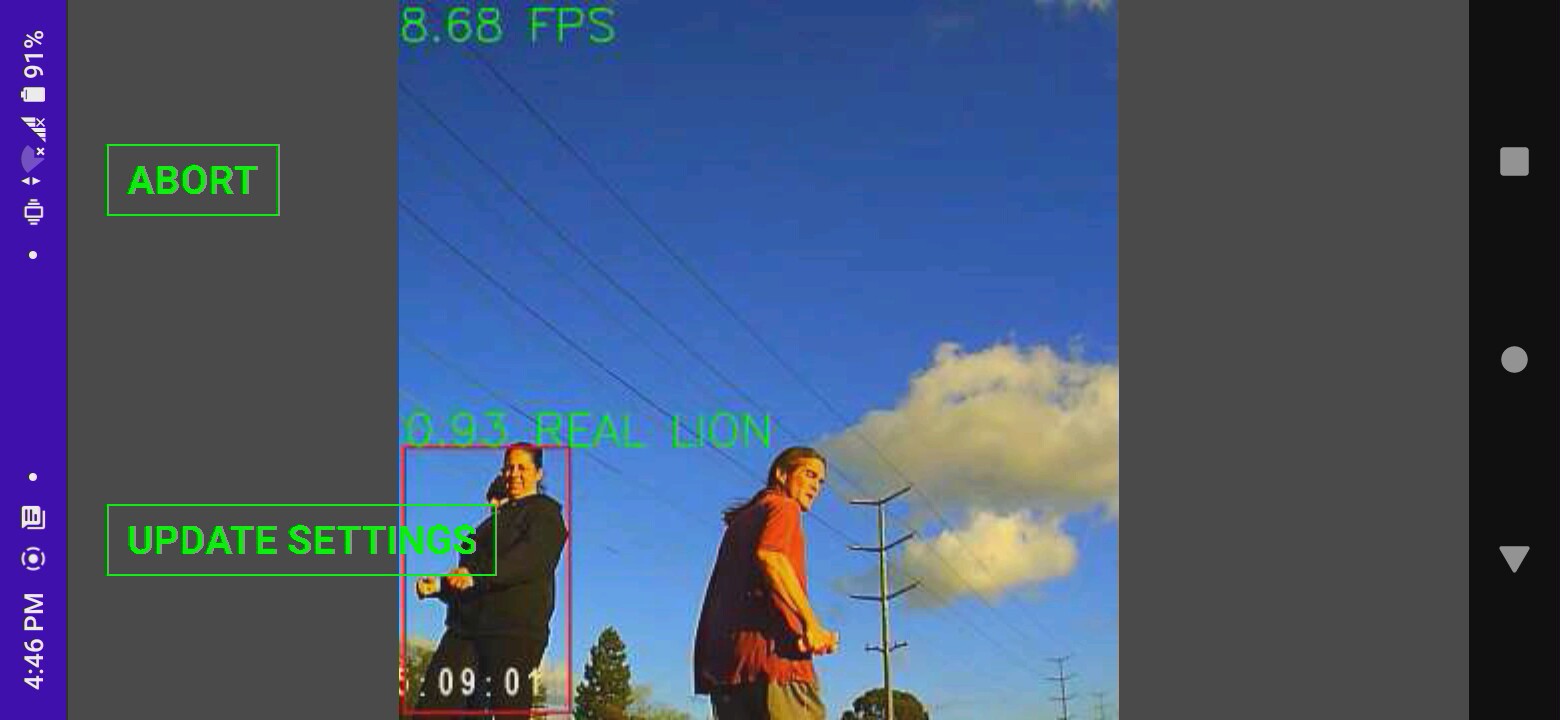
02/22/2022 at 03:29 • 0 commentsIn the field, efficientdet_lite0 was vastly superior to face tracking. The mane problems were trees & skeletal structures.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Trees are the lone bigger problem than face tracking. A higher camera elevation or chroma keying might help with the trees.
![]()
Face tracking couldn't detect lions from behind.
![]()
![]()
Multiple animals were as bad as face tracking.
![]()
It definitely coped with back lighting better than face tracking.
![]()
Range was limited by that 320x320 input layer.
![]()
Most footage with an empty horizon had the lion in the high .9's, but there's little point in having nothing else in frame.
The leading idea is labeling a video of lions with YOLOv5 & using this more advanced detection to train efficientdet_lite0. There's trying a FFT on the detected objects & making a moving average of the lion's average color. Trees should have more high frequency data & should be a different color.
Sadly, there's no easy way to get rid of the time stamp on the 808 keychain cam. Insert an SD card & it automatically writes a configuration file called TAG.txt. The file can be edited to remove the time stamp: StampMode:0 The problem is if the SD card is in the camera during startup, the raspberry pi detects the camera as an SD card instead of a camera. You have to tap the large button on it after booting to change mode. There's no indication of what mode it's in other than a long delayed message on the truckcam app.
Armed with 35,000 frames of lion video, the easiest way to label it was the pytorch installation formerly used to train YOLOv5.
https://hackaday.io/project/183329/log/203055-using-a-custom-yolov5-model
It actually has a detect.py script which takes an mp4 file straight from the camera & a .pt model file.
Yolov5 in pytorch format is downloaded from:
https://github.com/ultralytics/yolov5/releases/tag/v6.1
There are various model sizes with various quality. It begins again with
source YoloV5_VirEnv/bin/activate
python3 detect.py --weights yolov5x6.pt --source lion.mp4
The top end 270MB model burns 1.9GB of GPU memory & goes at 10fps on the GTX 970M. It puts the output in another mp4 file in runs/detect/exp/
![]()
![]()
![]()
![]()
![]()
The big model does a vastly better job discriminating between lions & trees. It still has false hits which seem to be small enough to ignore. The small selection of objects YOLO tracks makes lion wonder what the point is. Maybe self driving relies on labeling objects that move while relying on parallax offsets to determine obstructions.
The size & speed of the big model on a GPU compared to the 4MB tensorflow model on a raspberry pi makes lions appreciate how far computing power has declined.
The next task is selecting 1200 frames to train from, making detect.py output xml files for the training & validation data. There's no way a lion could manually label 1200 images. It's pretty obvious the COCO dataset was labeled by an even bigger model.
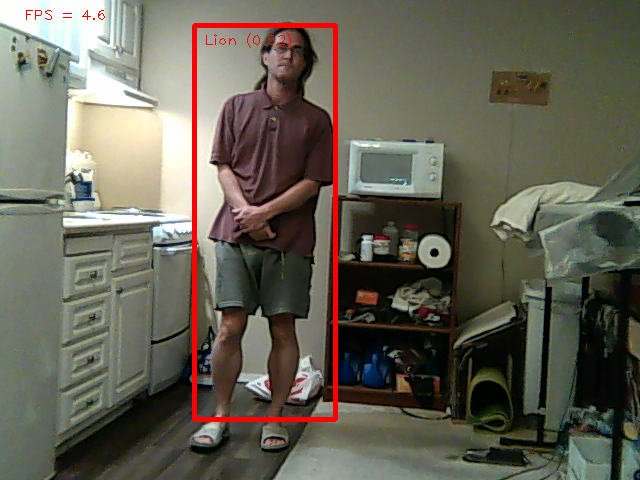
Training a tensorflow model took only 30 epochs before val_loss stopped. The new model was drastically worse than the model trained from COCO. The mane problem was detecting the lion in the sides of the frame & partially obstructed. It also had trouble detecting any poses that weren't trained in.
The mane problem with recursively training a model is there's much less variation in what it's tracking than the COCO data.
-
efficientdet_lite0 with 16:9 video
02/21/2022 at 04:58 • 0 commentsSo squeezing the training data to match animorphic 16:9 video didn't give any hits. When the test video was cropped to 1:1 again, hits bounced back to the same as if the training data was never squeezed. It somehow knew the test video was cropped instead of stretched without any insight from the training data. It is believed animorphic video squeezes the details below the minimum resolution, hence why it fails to track lions facing sideways.
The best option would now be changing the input layer size, but the internet only says not to attempt this. 1 problem is expanding the input layer causes an exponential increase in computations.
Another option could be tiling 2 widened images in the input layer. That would drop the vertical resolution to 160 while increasing the horizontal resolution to 640. It would cause a blind spot in the middle.
The leading idea is panning the 1:1 frame inside the 16:9 frame to follow the hit. It sweeps back & forth when it has no hit.
Object detection has always been dependent on aspect ratio. Openpose only worked with 16:9 video but fell over on 1:1 video. It was always assumed to be the training data being stretched to match the test video.
-
Using tensorflow in a C program
02/16/2022 at 20:24 • 0 commentsTFlite models aren't supported by opencv DNN. Instead, you have to install the tensorflow library for C++. This is another port which seems to have been dropped in favor of focusing on python.
The journey begins by downloading an ARM64 release of bazel. It might work on ARM 32, but the only prebuilt binary is ARM64.
https://github.com/bazelbuild/bazel/releases
It has to be chmod executable & then renamed to /usr/bin/bazel.
Then comes downloading the latest tensorflow release source code from
https://github.com/tensorflow/tensorflow/releases
Then run python3 configure.py, at which point it says you have to downgrade bazel. The lion kingdom tries bazel 3.7.2 instead. Then tensorflow says bazel has to be above 4.2.1, so the lion kingdom tries 4.2.1.
Use the defaults for all the config options.
Then
bazel build -c opt //tensorflow/lite:libtensorflowlite.so
There isn't an install script. It dumps libtensorflowlite.so deep inside /root/.cache/bazel/_bazel_root
It has to be copied somewhere easier to access for the dynamic linker.
Some header files are in tensorflow-2.8.0/tensorflow/lite
Other header files for 3rd party libraries are in ~/.cache/bazel
The example programs are in tensorflow-2.8.0/tensorflow/lite/examples/
It's a much bigger deal to make it work in C than python, partly because there isn't an include & library structure. The images are actually stretched to the 320x320 input layer so unless the model is aspect ratio independent, the training set needs to be similarly stretched. At such low resolution, small objects can be eliminated.
![]()
![]()
![]()
![]()
![]()
The test with the 16:9 cam was nowhere close.
![]()
![]()
![]()
![]()
![]()
Cropping it to 1:1 made it pop, so it is aspect ratio dependent. It was really good at tracking a lion once the aspect ratio matched the input layer. It might even be outdoing face tracking. It even got all the orientations that it couldn't get in 4:3. The task is either stretching the training data or somehow reorganizing the 16:9 video to fill a 1:1 frame.
In other news that surprised no-one, the jetson nano page that everyone has been reloading was changed from being restocked on Feb 19 to being discontinued.
Interestingly, archive.org showed it still in production as recently as May 2021.
Nowdays, it's incomprehensible that an embedded GPU ever existed for such a low price. If embedded GPUs ever come close to that performance again, they're going to be thousands of doll hairs.
-
Training efficientdet_lite1
02/15/2022 at 00:56 • 0 commentsA test model with 100 images showed efficientdet_lite1 runs at 4.5fps on the raspberry pi 4b, which should rise to 5.8 after overclocking. Efficientdet_lite2 runs at 3fps. There is a linear relationship between the size of the .tflite files & speed.
There was a problem where training efficientdet_lite1 with 1000 images made the 3GB GPU run out of memory after performing all the epochs. This didn't happen when training efficientdet_lite0 with 1000 images. Tensorflow's memory usage increases with the dataset size while pytorch only cared about model size. The step which runs out of memory is some kind of validation step & doesn't depend on batch_size.
The solution was to reduce the validation size to 100 images.
![]()
![]()
![]()
![]()
The result of 50 epochs with 1000 images was much lower scores for the real lion & no difference in the number of false positives. So the lower framerate wasn't worth it.
It then spent 2 hours training efficientdet_lite0 on 100 epochs with 5000 images, batch size 4. This degraded results. Too many images with a smaller model might actually be worse.
The best models have been 300 epochs with 1000 images. Fewer or more images with any number of epochs degrade results.
The next step might be manually labeling footage of a lion running, supplimenting the training set with images of lions that it missed, recording lion footage from the field camera.
Since no full body detection is doing a great job, it might be better to go back to face detection. There's still running face detection with recognition at 1fps & using optical flow to fill between frames.
-
Training an efficientdet_lite0 model
02/13/2022 at 08:22 • 0 commentsThe journey began with downloading a new dataset from the goog.
https://voxel51.com/docs/fiftyone/tutorials/open_images.html
For some reason, the data set is intended to be downloaded & viewed by running commands from the python console. Helas, it was a bit convoluted & bloated compared to COCO's category ID's. It would be easier to just convert COCO to the right XML format.
A new truckcam/coco_to_tflow.py script converted the annotations.
Then it was a matter of converting
into a big model making script: truckcam/model_maker.py
The 1st problem was getting tensorflow to use the GPU. Verify GPU detection with:
source yolov5/YoloV5_VirEnv/bin/activate
LD_LIBRARY_PATH=/usr/local/cuda-11.2/targets/x86_64-linux/lib/ python3
import tensorflow as tf
print(tf.__version__)
print(tf.config.list_physical_devices())
This normally fails with libcudart.so.11.0 & libcudnn.so.8 not being found.
The command which works is to install cudnn from
https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html
Get the version from the archive which matches the version of CUDA.
The next problem was unlike pytorch, tensorflow doesn't store the best model & stop training after it hits the best model. You have to review the training printfs & find where val_loss stops decreasing. Then retrain with a different number of epochs.
Finally, if the batch size is too big it'll crash after training is complete. Pytorch would crash before training began.
The model maker doesn't automatically generate any test images with labels, but the model does work when dropped into the example from https://github.com/tensorflow/examples/tree/master/lite/examples/object_detection/raspberry_pi
python3 detect.py --model=model.tflite
![]()
50 epochs with 1000 images gave a fail.
![]()
![]()
![]()
![]()
300 epochs with 1000 images arguably gave better results. It's arguably only slightly worse than openpose at detecting fake lions & arguably comparable to face detection. The score can be tweeked to make it more selective. It's definitely better than the stock efficientdet_lite0 model.
Some other ideas are trying the larger efficientdet models with overclocking or on the odroid, trying more images, using video of just lions.
It runs 8x faster on the raspberry pi than software mode on a Core(TM) i7-6700HQ. No-one is bothering to optimize tensorflow for Intel anymore. The lion kingdom doesn't think Intel should be underestimated, since they're the only ones who have made any chips since 2020.
-
Training a YOLOV5 model
02/12/2022 at 09:17 • 0 commentsAfter extracting just 1 category with truckcam/coco_to_yolo.py, there has to be a data.yaml file to point pytorch at the training data.
train: ../train_person val: ../val_person nc: 1 names: ['person']the training step was done in /root/yolo/yolov5/
source YoloV5_VirEnv/bin/activate
python3 train.py --data data.yaml --cfg yolov5s.yaml --batch-size 8 --name Model
yolov5s.yaml is the model & they say it's the simplest. All the models are in the models directory. They're just text files which describe the neural networks.
This would take many years to finish without CUDA, so some effort is required to get CUDA working. It doesn't work by default. To debug it, we have to limit the size of the dataset by setting max_objects in coco_to_yolo.py
The 1st step is using the right version of CUDA. This one required 11.2
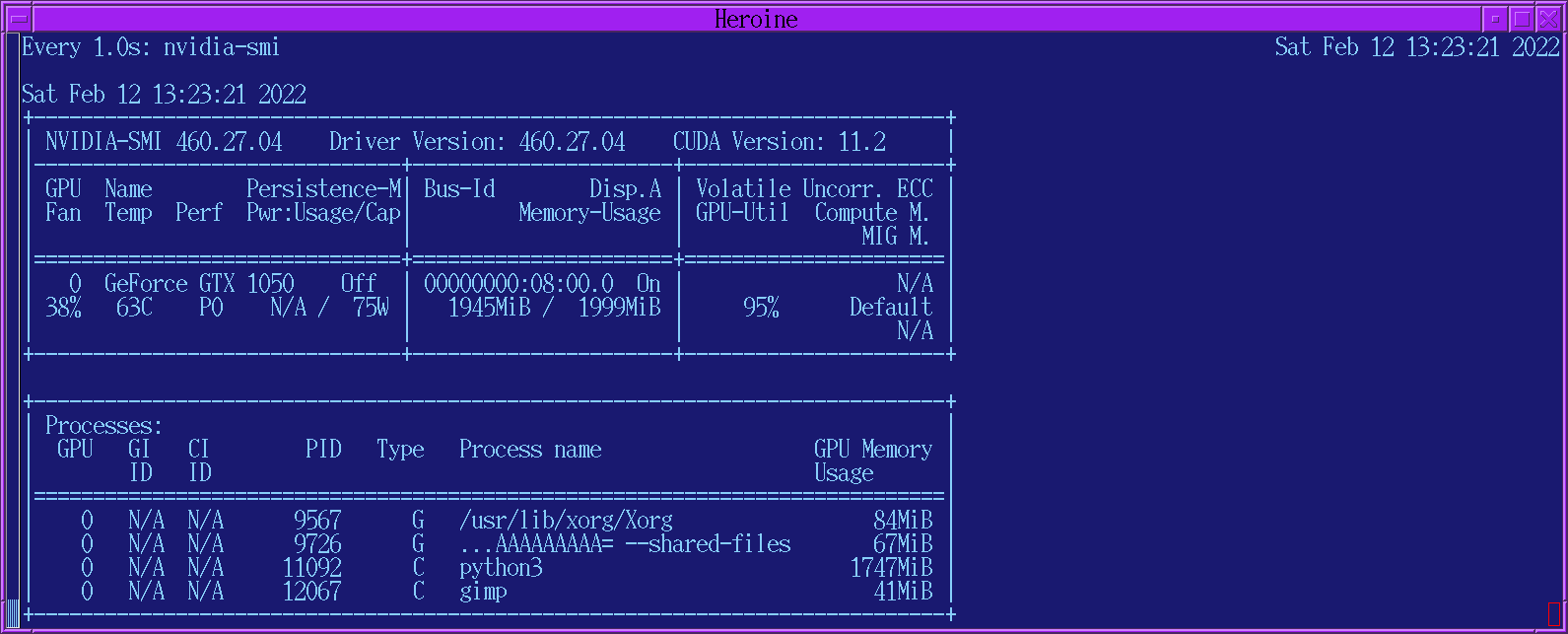
The 2nd step is reducing the amount of GPU memory required. The lion kingdom reduced the batch-size to 4 to get it under 2GB.
![]()
Not sure if it preallocates the memory. Watch a 4K video & it's all over.
![]()
Even with 100 objects & what they term the very simplest model, it took 15 minutes. Then, it created some collages of validation tests on scenes from the 1990's. It's supposed to use the train* files for training & test against the val* files.
![]()
It's almost like the bounding boxes in the training set are offset in the top left.
![]()
A 500 object run took 80 minutes on a GTX1050 with 2 Gig. It said it ran 293 epochs but saved the model from epoch 193. It basically detects the peak model & waits for 100 more epochs before quitting. The validation tests were just as bad.
![]()
In the train_batch files, the labels were all over the place.
![]()
2 discoveries were the .txt files need to contain the center x, center y, width, height in fractions of the image size & you have to delete all the .cache files in order to change the data set. There's no way to get that without downloading the complete 1G example data set for YOLOV5 & reviewing the validation output. The annotation formats are heavily protected bits of intellectual property.
![]()
Much better results from 100 objects. Not good enough for a pan/tilt tracker because it doesn't detect any body parts, but it might be good enough to replace face detection for panning only.
![]()
1000 objects took 2 hours to train on a GTX 970 with 3 Gig. It gave roughly the same results as 100 objects. Suspect spending several years on 1 million objects would do no good. YOLOv5 may be good enough to not need a lot of training or the model may not be big enough to store any more data.
A biologically derived model that detects just the humans instead of the mane subjects in the photos seems like a lonely animal, but it's what tracking cameras are for. Ben Heck would train it to detect just cats. The neural network can't reproduce so it's not alive.
The next step is converting the output into a format for https://github.com/tensorflow/examples/tree/master/lite/examples/object_detection/raspberry_pi
The pytorch output goes into a best.pt file in /root/yolo/yolov5/runs/train/*/weights
There is a script for converting best.pt into tensorflow lite format: /root/yolo/yolov5/export.py
python3 export.py --weights runs/train/Model.../weights/best.pt --include tflite --img 640 --int8
Sadly, this didn't produce the metadata required by https://github.com/tensorflow/examples/tree/master/lite/examples/object_detection/raspberry_pi. It's not obvious that YOLOv5s would ever be a drop in replacement for efficientdet_lite0 or that it would be as fast. Based on anecdotes, conversion from pytorch to tflite isn't officially supported & all the conversion scripts are diabolical hacks.
The next step is to try to use the efficientdet_lite0 model maker described in
This is based on a modern notebook style program https://github.com/freedomwebtech/tensorflow-lite-custom-object
It can do the training on a Goog cloud server with a better GPU, but it'll cost you. You can also cut & paste it into a local python script. The annotation files are in an XML format with only a video example given.
Another model maker program
https://www.tensorflow.org/lite/tutorials/model_maker_object_detection
uses a CSV file with the labels & image filenames, but provides no examples. Suspect the annotation formats are obfuscated to keep people from using goog's dataset with pytorch or the COCO dataset with tensorflow. Pytorch is funded by facebook while tensorflow is funded by the goog.
The tensorflow process is a lot more centralized than digging up a dataset from the COCO archives & running pytorch. There is a much larger database of images on the goog https://storage.googleapis.com/openimages/web/index.html
& the tools are provided to make a custom dataset. It doesn't seem possible to run a model maker on a goog cloud server, making it load its own dataset directly from openimages. The dataset has to be copied to a goog drive because it has to be reloaded for every epoch.
Surprisingly, most of the datasets already built are aimed at self driving cars while there are no datasets for just humans.
-
Using a custom YOLOV5 model
02/10/2022 at 07:46 • 0 commentsThere were attempts at using a bigger target than a face by trying other demos in opencv.
openpose.cpp ran at 1 frame every 30 seconds.
person-reid.cpp ran at 1.6fps. This requires prior detection of a person with openpose or YOLO. Then it tries to match it with a database.
object_detection.cpp ran at 1.8fps with the yolov4-tiny model from https://github.com/AlexeyAB/darknet#pre-trained-models This is a general purpose object detector.
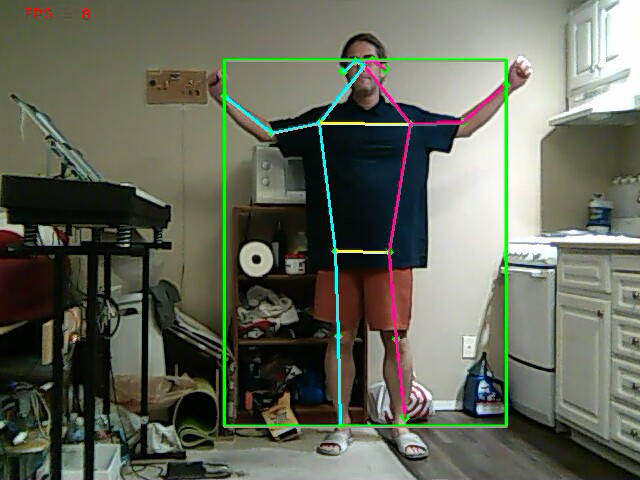
There were promising results with a 64 bit version of pose tracking on the raspberry pi. Instead of using opencv, this used tensorflow lite. It tracks 1 animal at 8fps. The multi animal network goes at 3fps or 4fps with overclocking.
![]()
A 1 animal pose tracker would avoid tracking windows instead of lions & it would have an easier time in difficult lighting, but it would probably have the same problem of tracking the wrong animal in a crowd. It's not clear if it chooses what animal to track based on size, total number of visible body parts, or the score of each body part. It may just be a matter of fully implementing it & trying it in the city.
Maybe compiling opencv for aarch64 would speed up the face recognition because of wider vector instructions. There were some notes about compiling opencv for aarch64
https://github.com/huzz/OpenCV-aarch64
That didn't work. 1st,
-D ENABLE_VFVP3=ON
should be
-D ENABLE_VFPV3=ON
Helas, VFPV3 isn't supported on the raspberry pi 4 in 64 bit mode so this option needs to be completely left out. There's a lot of confusion between raspberry pi's in 32 bit & 64 bit mode.
The mane change is to download the latest HEAD of the 4.x branch so it compiles with Ubunt 21.
Helas, after recompiling opencv for 64 bit mode, the truckcam face tracker still ran at 8.5fps, roughly equivalent to the latest optimizations of the 32 bit version. Any speed improvement was from the tensorflow lite model instead of the instruction set.
![]()
![]()
![]()
![]()
There was an object tracker for tensorflow lite which sometimes worked.
https://github.com/tensorflow/examples/tree/master/lite/examples/object_detection/raspberry_pi
The advantage is it can detect multiple animals at a reasonable framerate, but it was terribly inaccurate.
This led to the idea of training a custom YOLO model on a subset of the data used to train other YOLO models. YOLO is trained using files from
https://cocodataset.org/#download
There are some train & val files which contain just images. There are other files which contain annotations. There was a useful video describing the files & formats on cocodataset.org.
Basically, all of today's pose tracking, face tracking, object tracking models are based on this one dataset. All the images are non copyrighted images from flickr. They've all been scaled to 640 in the longest dimension. All the images were annotated by gig economy workers manually outlining objects for a pittance.
They're all concentrated around the 2005-2010 time frame when flickr peaked & they're concentrated among just people who were technically literate enough to get online in those days. All of the machine vision models of the AI boom live entirely in that 1 point in time.
4:3 monitors, CRT's, flip phones, brick laptops, overweight confuser geeks, & Xena costumes abound.
![]()
![]()
There's a small number of photos from 2012 up to 2017. The increasing monetization options after 2010 probably limited the content.
To create an annotation file with a subset of the annotations in another annotation file, there's a script.
https://github.com/immersive-limit/coco-manager
For most of us, the usage would be:
python3 filter.py --input_json instances_train2017.json --output_json person.json --categories person
There are bits about training a YOLO V5 model & a link to a dropbox with a dataset on https://www.analyticsvidhya.com/blog/2021/12/how-to-use-yolo-v5-object-detection-algorithm-for-custom-object-detection-an-example-use-case/
There is so much bloatware, the virtual environment is definitely required. The command to enter the python virtual environment is
source YoloV5_VirEnv/bin/activate
Most people get an error when installing pytorch. It's not compatible with python 3.10 or other random versions of python. Try downloading & compiling python 3.9
./configure --prefix=/root/yolo/yolov5/YoloV5_VirEnv
Sadly, the instructions for training don't involve the JSON files from cocodataset. Instead, they specifiy a .yaml file with the paths of the images & a .txt file for each image. The .txt format for the annotations is a line for each object. Each line has a category index from the .yaml file & the bounding box of the object. There are no subcategories in YOLOV5, so it couldn't track keypoints inside a person. Obviously, the COCO dataset is intended for more than just YOLOV5. There would have to be a conversion from COCO to YOLO annotations.
-
Alternative face trackers
01/20/2022 at 00:23 • 0 commentsFace tracking based on size alone is pretty bad. It desperately needs a better recognition part.
There is another face detector using haar cascades.
opencv/samples/python/facedetect.py
These guys used a haar cascade with a dlib correlation function to match the most similar region in 2 frames.
https://www.guidodiepen.nl/2017/02/detecting-and-tracking-a-face-with-python-and-opencv/
These guys similarly went with the largest face.
It was nowhere close & ran at 5fps instead of 7.8fps. Obviously the DNN is the latest & greatest.
The Intel Movidius seems to be the only embedded GPU still produced. Intel bought Movidius in 2016. As is typical, they released a revised Compute Stick 2 in 2018 & didn't do anything since then but vest in peace. It's bulky & expensive for what it is. It takes some doing to port any vision model to it.
Raspberry pi tracking cam
Tracking animals on lower speed boards to replace jetson & coral