 Denver
DenverMy first micro-computer was an Explorer 85 kit from Netronics Research, which used standard audio cassette tapes for storage. Other storage methods were available at the time, but were far more expensive than tape. Even floppy drives were beyond my budget back then. Eventually prices came down and I bought a 64K CP/M system with dual 5 1/4 inch floppy drives. The Explorer 85 and some of the cassette tapes got moved from closet to closet and box to box over the years, but never thrown out. I was cleaning out the last closet they were in and thought it would be interesting to see if anything could be recovered from the cassette tapes.

Explorer 85 S100 boards: bus monitor+printer port, bubble memory, 32K static RAM
Although the old Explorer 85 still worked, the cassette recorder didn't. I do have a newer one that works, but there are two major problems with using it to read files with the Explorer 85. The biggest is that the new recorder doesn't have a turns counter like the old one had. All the files on the cassette tapes were indexed and located by the counter. The other problem is that files got recorded with a single character or byte ID, which needed to be supplied when reading that file. If the ID wasn't correct the Explorer 85 would simply report an error just like any other tape error. I always wrote the start and end counter values for each file on each cassette, but I'm not sure about the ID. I was able to successfully save and load data using the new recorder and an old, unused cassette, so I knew all the hardware was working.

Cassette Tape Label
Uncertainty about positioning and ID for each file made it unlikely that I could recover anything using the computer itself. I was also reluctant to put 40 year old cassettes under any more stress than absolutely necessary. So I had to fall back to plan B, which was to digitize the tapes and see if any sense could be made from the digital images. Using an inexpensive analog audio to USB converter, I captured one complete side of one tape. The software I used was Audacity 3 running on a FreeBSD 12.3 system. I used default settings for everything.
At this point I needed to know how Netronics recorded data on tape. There were a lot of different formats in use back then, many of which are well documented, but I couldn't find anything specific to the Explorer 85. However, Netronics also sold an Elf II product with a cassette interface, which is fairly well documented. It seemed reasonable to hope that they would have used a similar scheme for both products, especially since the hardware involved looked similar for both.
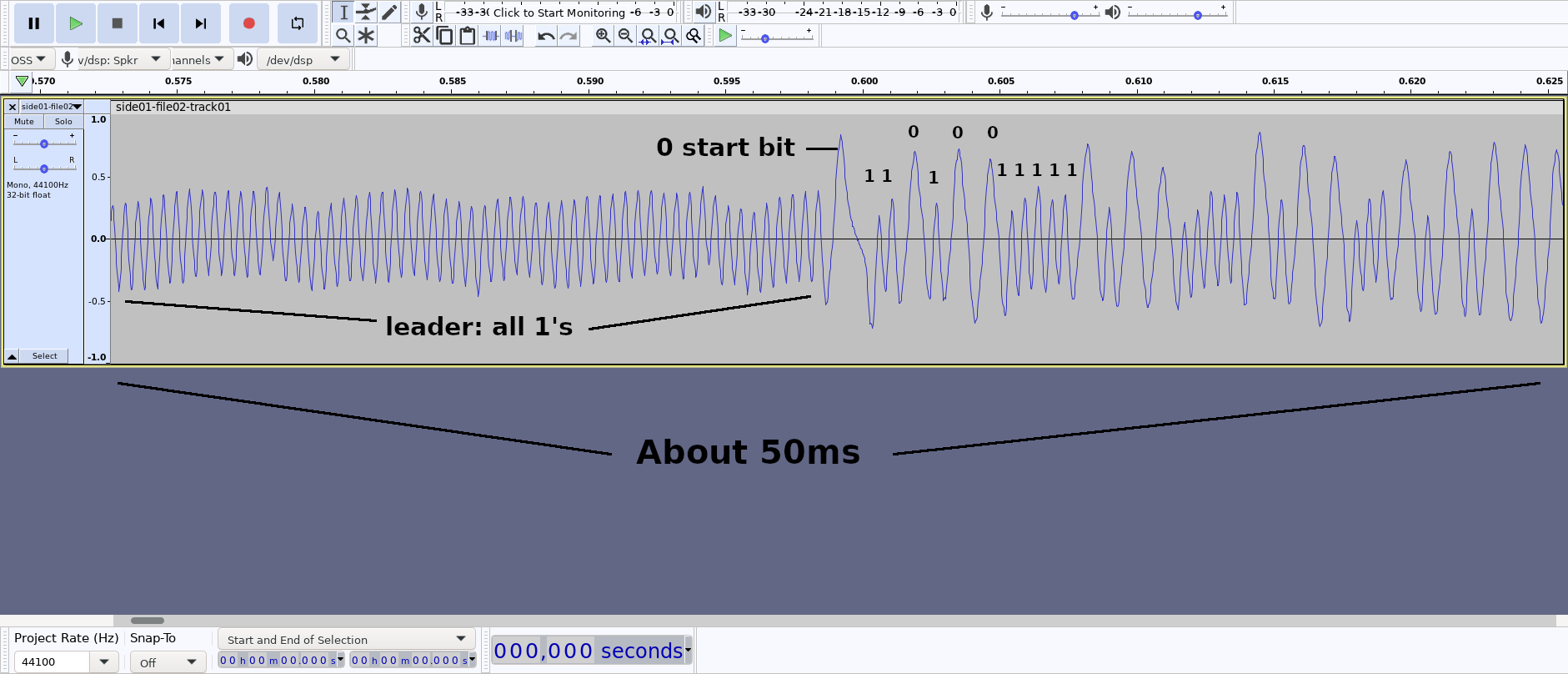
The Elf II used a leader of 1's, followed by a single 0, followed by two bytes of address, fol-
owed by two bytes of size. All bytes were recorded most significant bit first, using even parity. Each bit was represented as a single pulse with 0's being significantly longer than 1's. The exact timing doesn't matter here.
Looking at the captured audio with Audacity, I could clearly see an initial uniform leader, followed by a single longer pulse. When I assumed that short pulses were 1's and long ones were 0's, and each byte was nine pulses with even parity, I could easily figure out the first few bytes. t turned out that the Explorer 85 tape format was very much like the Elf II, except that the Explorer 85 included an ID byte, and used start and end address instead of start address and size.

It now looked like it might actually be possible to recover something useful from those 40 year old tapes, but I needed to understand the WAV file structure first. It turns out that WAV files are pretty simple: there's a 44 byte header containing a variety of information, followed by the actual audio data in the form of samples taken at regular intervals. Since I used signed 16 bit samples, I would need to read them back in that form. I wrote a short test program to extract the original tape header information: ID, start address, end address, and tried...
Read more »


 [skaarj]
[skaarj]
 Muphins
Muphins
 Eric Hertz
Eric Hertz
The manual refers to it as a "program number", and indicates that the tape load function will "scan for a program with the proper number". In practice that's not very practical. I seem to remember always using the same ID for everything after a while. And now that I've said that, I'm not completely sure about whether or not it actually stops if the ID is wrong.