 Shakhizat
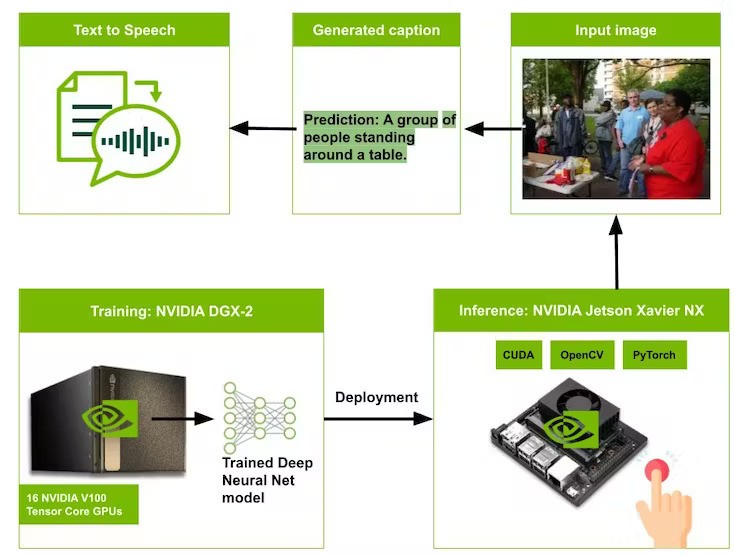
ShakhizatBlind and visually impaired individuals often encounter a variety of socioeconomic challenges that can hinder their ability to live independently and participate fully in society. However, the advent of machine learning has opened up new possibilities for the development of assistive technologies. In this study, we utilized image captioning and text-to-speech technologies to create a device that assists those who are visually impaired or blind. Image captioning combined with text-to-speech technology can serve as an aid for the visually impaired and blind.
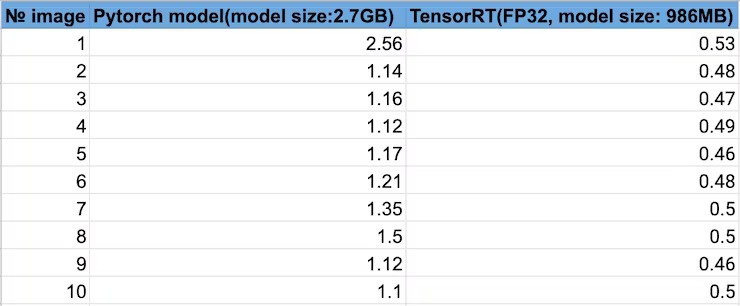
Furthermore, I would like to share my experience on optimizing a deep learning model with TensorRT to improve its inference time.

 Mathias
Mathias
 Jamy Herrmann
Jamy Herrmann
 jlbrian7
jlbrian7