 michal.nand
michal.nandvideo of experiment
robot
stm32f303 : 72MHz cortex M4 with FPU (avr can be used too, for slow robots ^_^)
line sensor APDS9950 : digital i2c RGB output, each have the some address, so
Iam using software i2c (with common scl)
line follower problem
common linefollower consist of line position sensor, PD controller for turning, some speed controller (PID can be used) and motors :

in this solution, reinforcement learning is used :
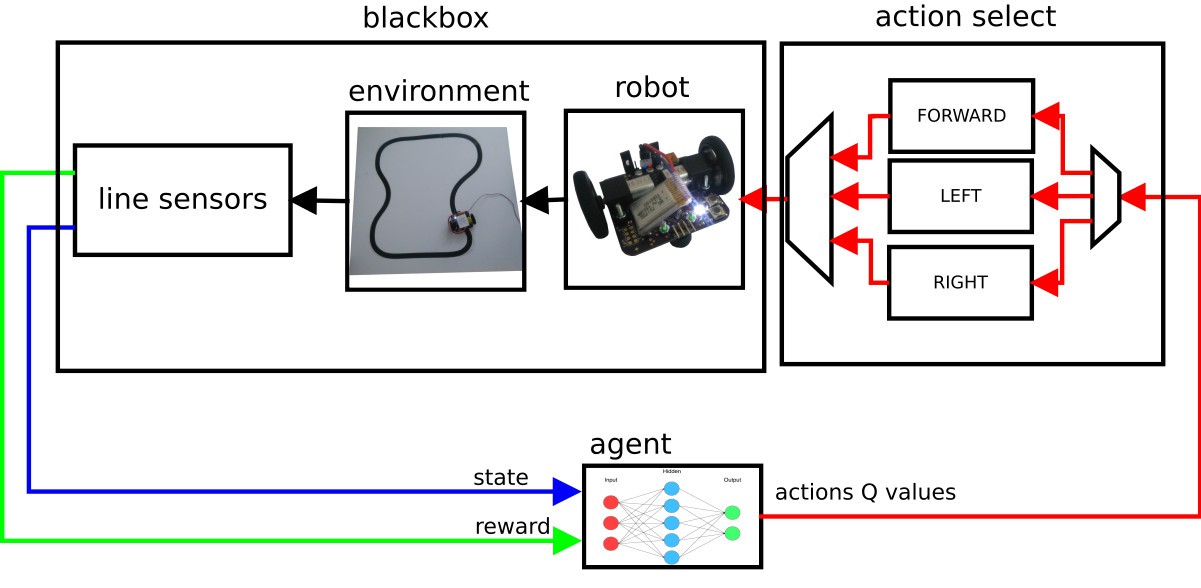
agent is obtaining only current state and reward, and choosing actions - but don't
know what is action doing;
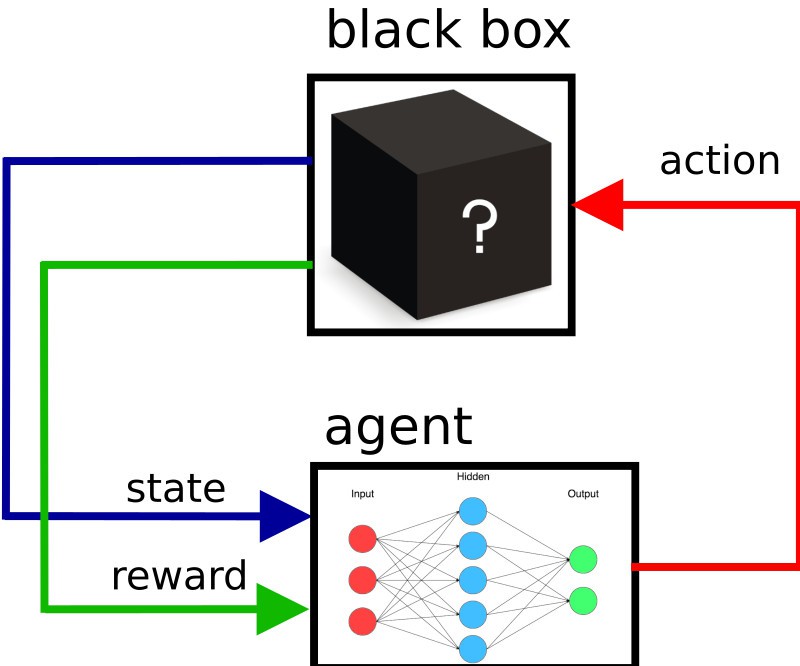
reward is how good is robot following line - how far it is from middle (middle is "0")
reinforcement learning
consist of four basic steps :
1) obtain state
2) execute action
3) obtain reward
4) learn from reward
system is handling "table" of values Q(s, a) : how good was action "a" in state "s"
Q(s, a) can be computed using Q-learning
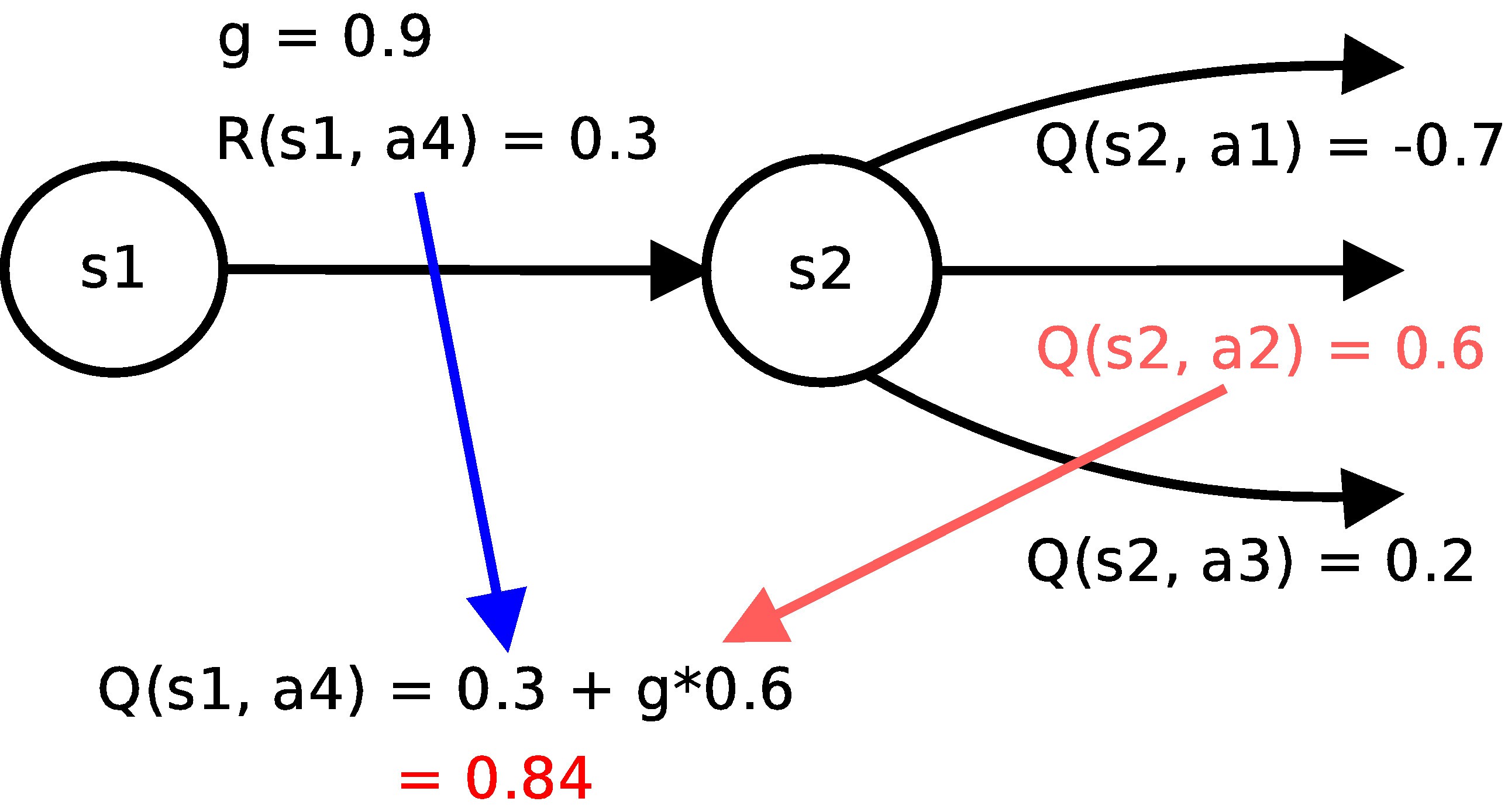
in human words (look for picture)
to compute Q value consider agent is in state S1 and doing action A4, after
this it is now in state S2; following these steps Q value can be calculated
1) look for obtained reward : R(s1, a4) = 0.3
2) look for state where this action leaded you, (into S2)
3) choose the highest Q value in current state : Q(s2, a2) = 0.6, and multiply it with gamma = 0.9
4) sum reward and this value for Q(s1, a4)
note : there is no need to know into which state chosen action leads - agent learn from what really is
function approximation
for small count of states, a pure table for storing Q(s, a) can be used;
I'am using associative neural network (description will be in few days)

 int-smart
int-smart
 Al Williams
Al Williams
 Anmol Chopra
Anmol Chopra
 Alexander Kirillov
Alexander Kirillov