 Reed Foster
Reed Foster(I will be updating this at https://github.com/reed-foster/uCPUvhdl/wiki and eventually will remove this section)
Designing a CPU:
In this section, I will describe how the muCPU was designed and how it works. Any blocks of text in italics is information to explain why I made a certain decision; it does not need to be read to understand how the muCPU works.
Step One: Instruction Set
When designing a CPU, the first thing to consider is what features/capabilities you want it to support. There are two main design philosophies when it comes to designing instructions for an architecture. Originally, when computers first emerged, memory was very expensive, so data and instruction widths were kept to a minimum in order to reduce cost. In addition, processors supported a wide variety of simple to complex instructions; they supported memory addressing for arithmetic operations, and some instructions executed multiple steps. Programmers used a small amount of complex instructions to minimize memory usage. However, with technological advancements and shrinking transistor sizes, manufacturers could fit more and more transistors onto integrated circuits, improving the storage capacity and processing power of computers. With an increase in storage capacity, programmers didn't have to worry as much about how many bytes their code took up; instead, they could focus on the speed of their code. With this increase of memory came the second design philosophy known as RISC, for Reduced Instruction Set Computing (while the previously mentioned design philosophy came to be known as CISC, or Complex Instruction Set Computing) . RISC processors are designed based on the idea of executing many very simple instructions very quickly, rather than a few complex instructions that each take a while to execute. Since CISC style processors are inherently more complicated to design, often times with multiple instruction bit widths and very complicated decoding circuitry, I decided to base the muCPU design off of a very simple (in some aspects) RISC style instruction set: MIPS. The MIPS Instruction Set consists of three types of operations: r-type, i-type, and j-type. As one might suspect, the "r" in r-type is for register, while the "i" and "j" in i-type and j-type are for immediate and jump.
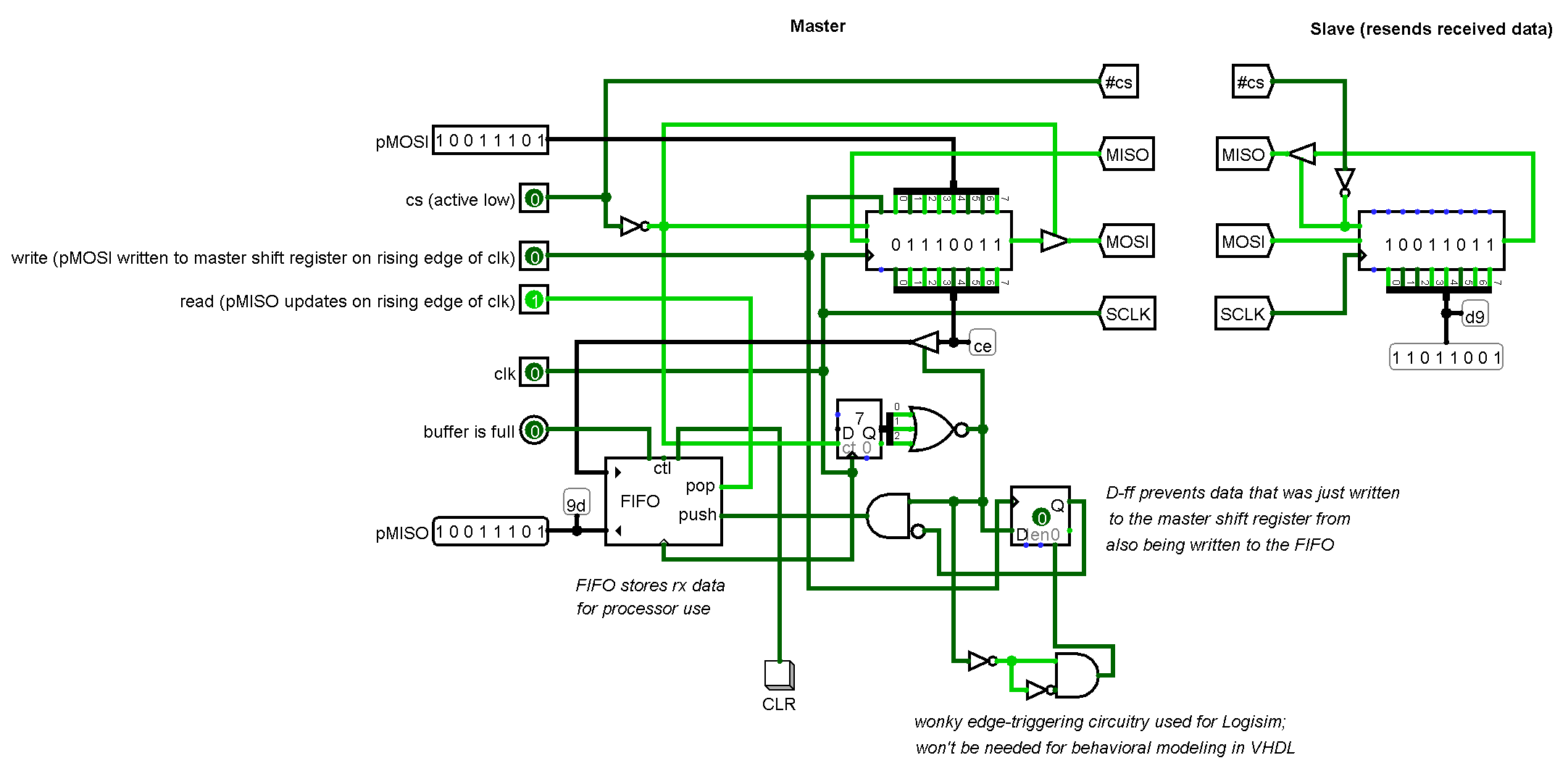
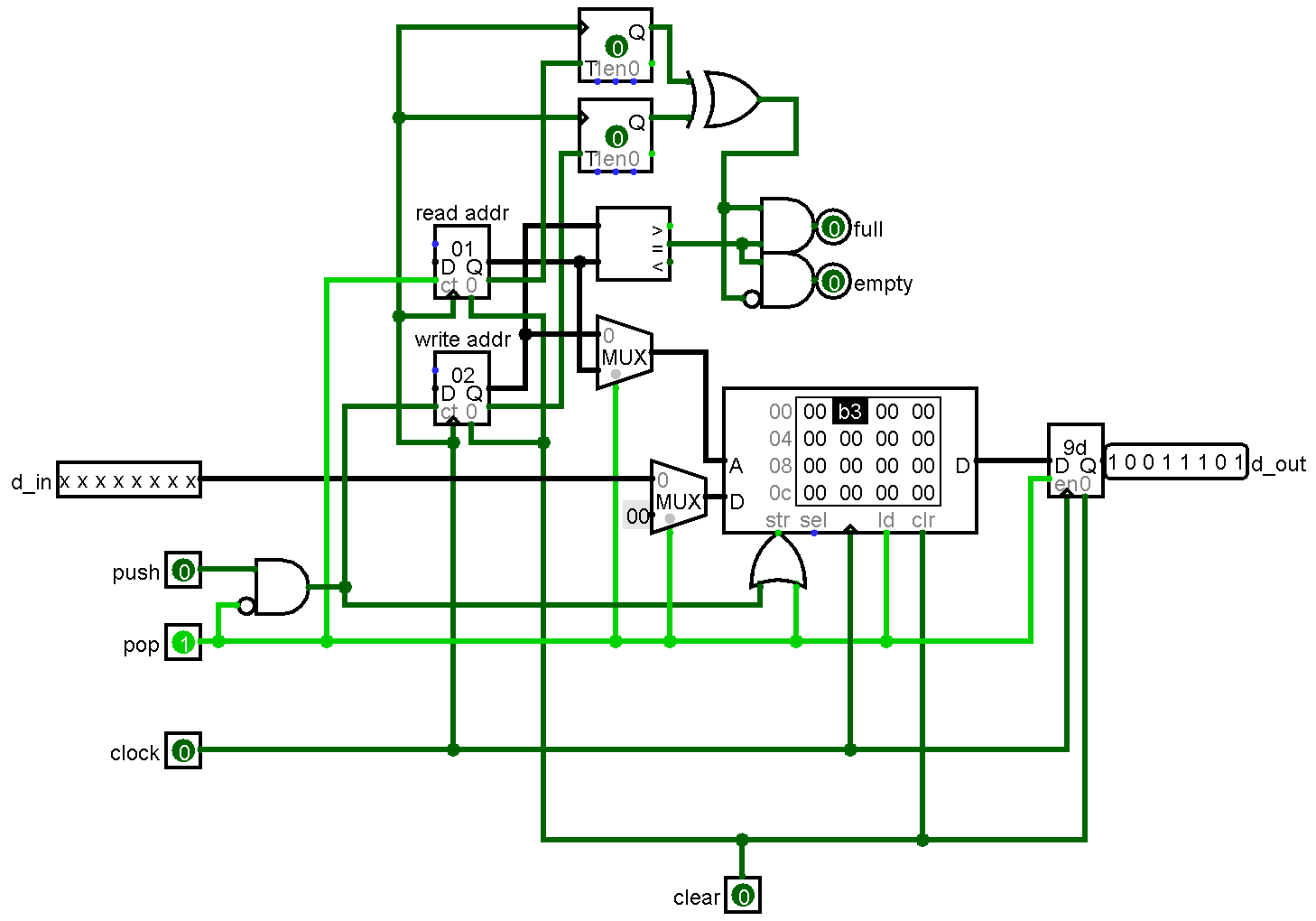
MIPS is a load-store architecture (meaning that memory is only accessed through load and store operations; arithmetic is done with a register file, a small bank of very fast memory) implemented with a pipeline, in fact, its name used to stand for Microprocessor without Interlocked Pipeline Stages. This basically means that each section of the pipeline takes one clock cycle to execute. MIPS uses a classic five-stage RISC pipeline consisting of the following stages: Instruction Fetch, Instruction Decode (and usually operand fetch), Execute, Memory Access, and Write Back. One of the problems with pipelining is that it introduces situations known as hazards. Hazards include structural, data, and branch hazards. Structural hazards are usually eliminated fairly easily; insert another adder here or there and usually all structural hazards are eliminated. Sometimes more complicated methods (such as register renaming) are required. Data hazards can occur when an instruction operates on data that has not yet been written back to the register file. Here's an example:
lb r2, 126(r5) ;load byte located in memory location (126 + contents of r5) into r2 add r2, r3, r4 ;add r3 and r4, storing the result in r2
The first instruction loads a byte from memory into r2, however, it takes 5 clock cycles for the instruction to be completed, so the second instruction will use an old value in r2, which is not what the programmer expects. One of the methods to negate this hazard is forwarding, a strategy that I used in my 32 bit MIPS CPU. In my implementation for that project, I save a small list of values and their corresponding register addresses that they are intended for. This list is located in the...
Read more »




 kaimac
kaimac

Very nice description of the architecture :-)