 Tom
TomThe idea for Project Ember came about while watching YouTube videos of all the awesome projects people were doing with breadboard-based computers using 6502 and 6800 CPUs, arcade emulators running in hardware on FPGAs, and old conference videos from Hackaday, GDC (Game Developer Conference), and many local hacker gatherings. The kicker was watching Ben Eater and his videos on 6502 and discrete circuit breadboard computers, timing circuits, and more. He explains things in a way that all the years of formal learning didn’t, this is where it finally clicked.
From there it was just a matter of learning everything there was to know about game and computer system design, programming, and implementation, both in software using emulation and in hardware. Once I felt I had a grasp on how I might accomplish the task, I began researching previous CPU and GPU designs (Though in our case retro ‘GPU’s are more like video chips than what we think of modern GPUs), learning the details of each and every home video game console and computer of the 1970s and 80s, as well as many of the arcade boards of the time.
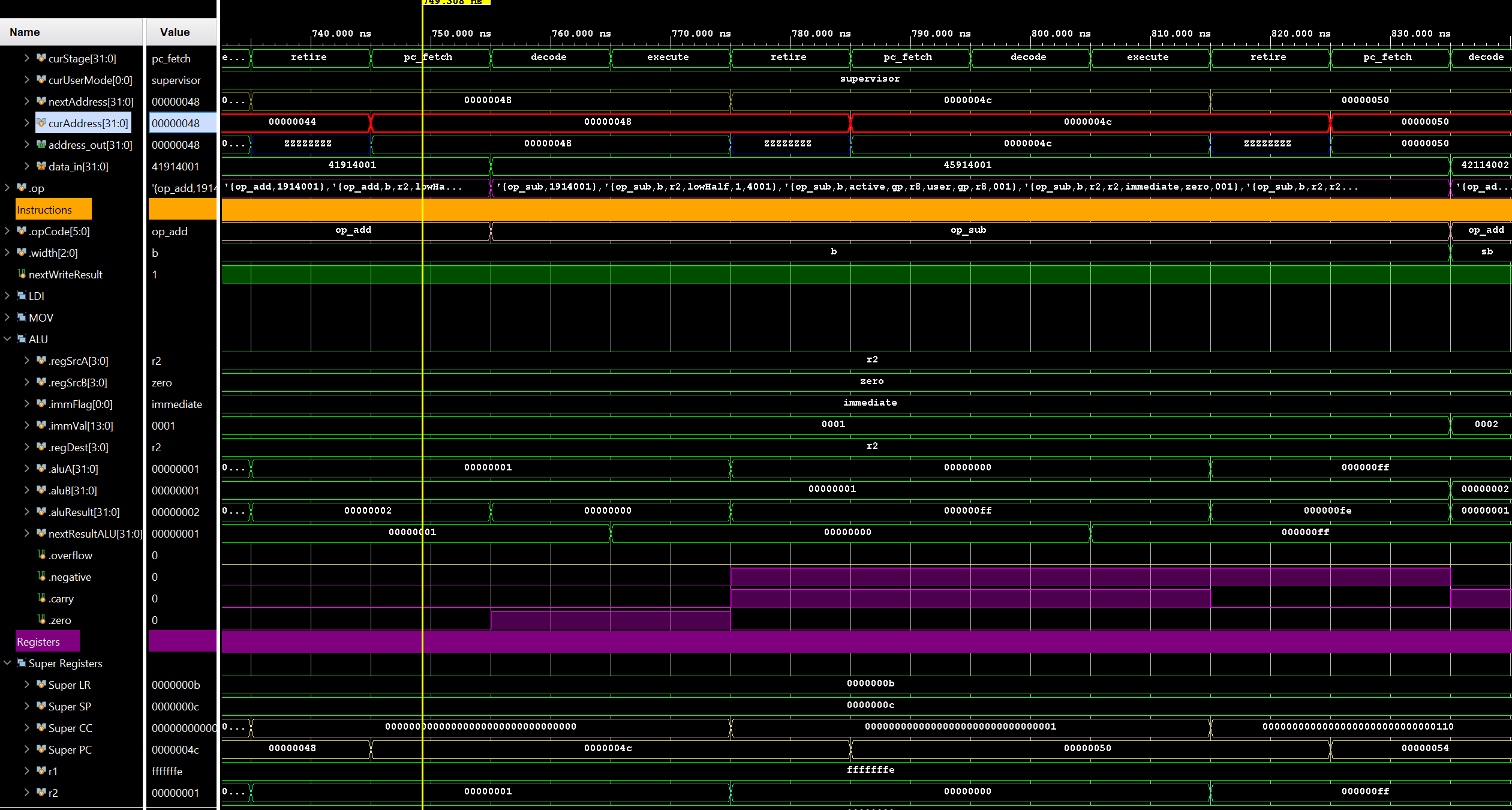
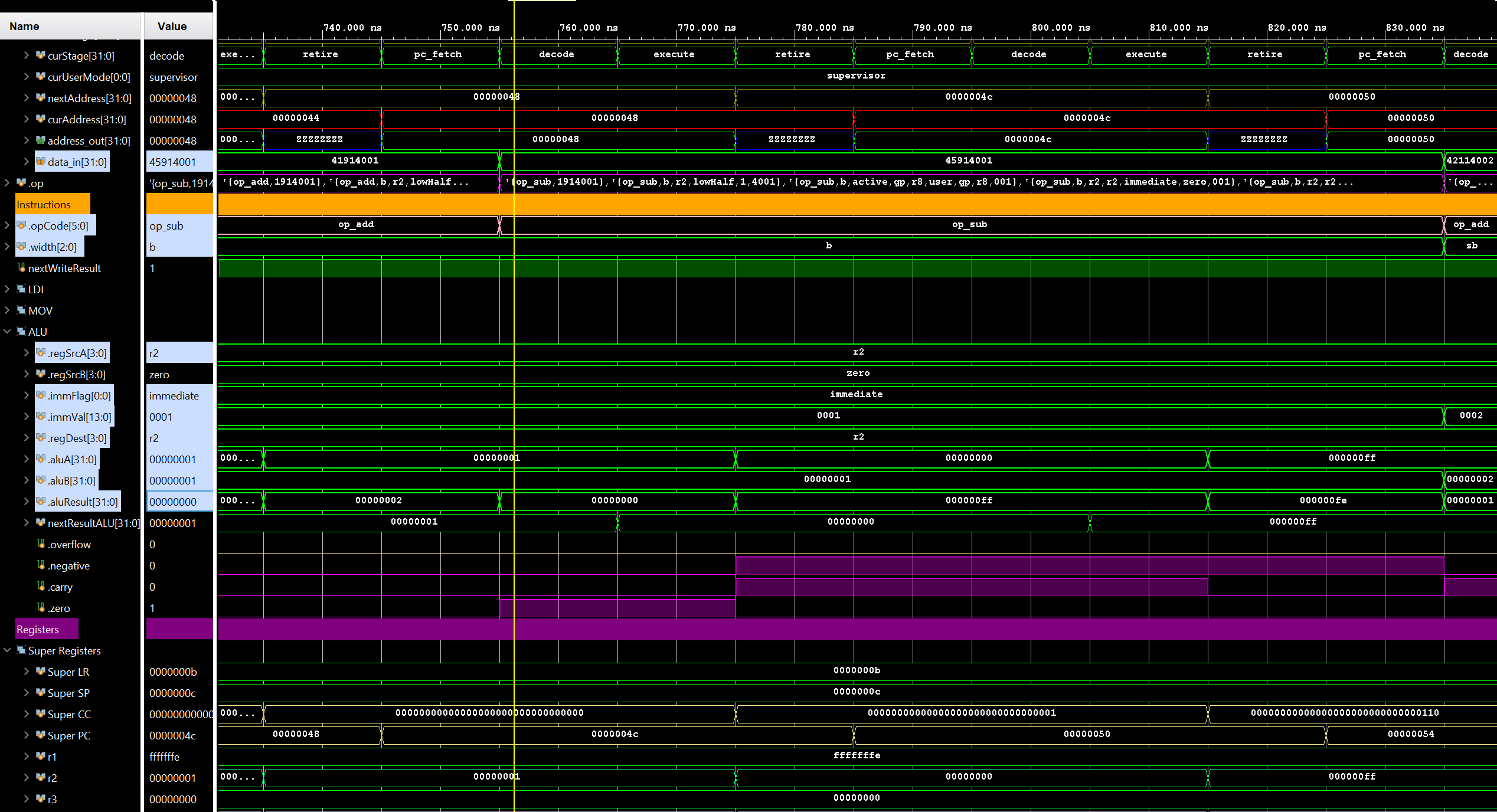
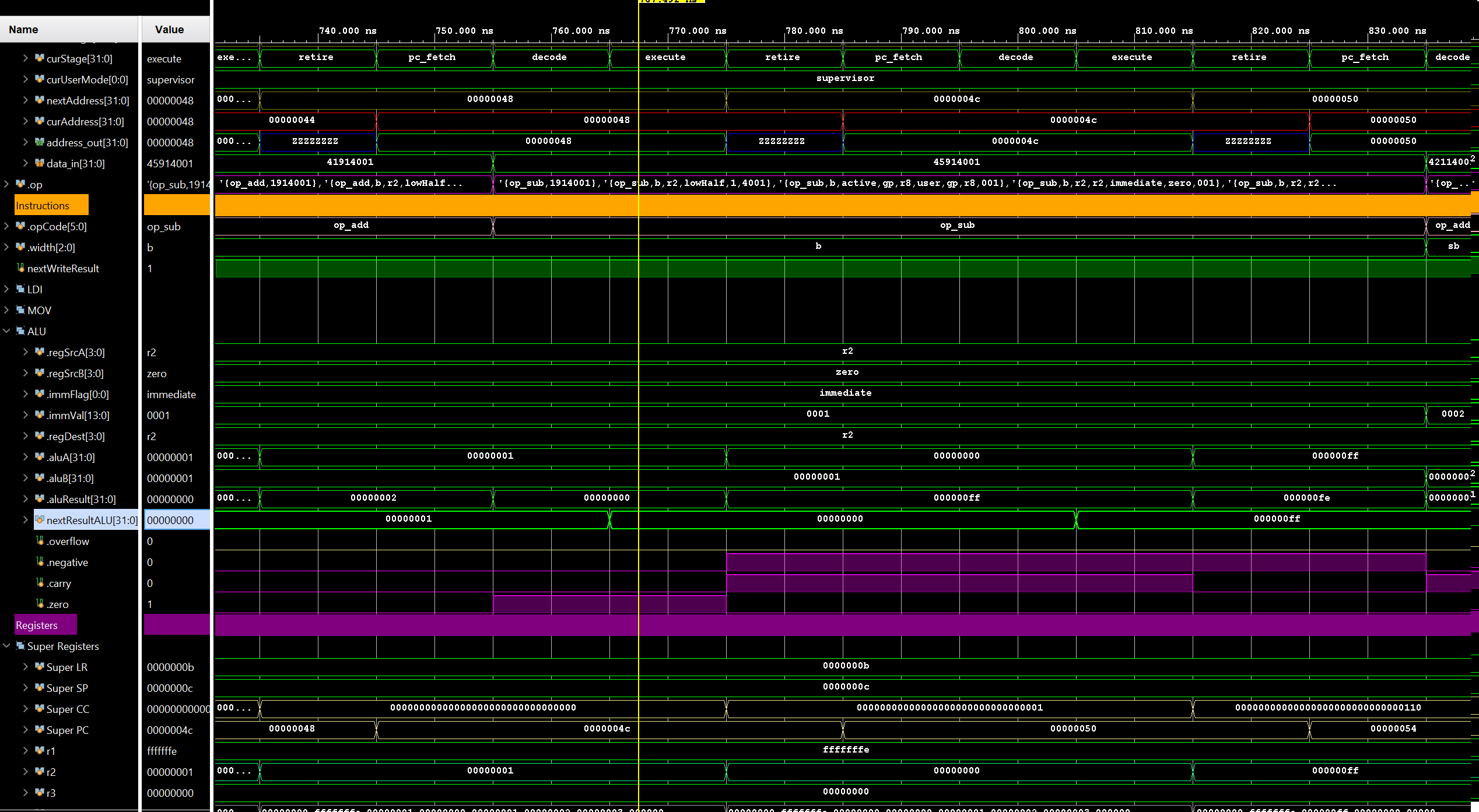
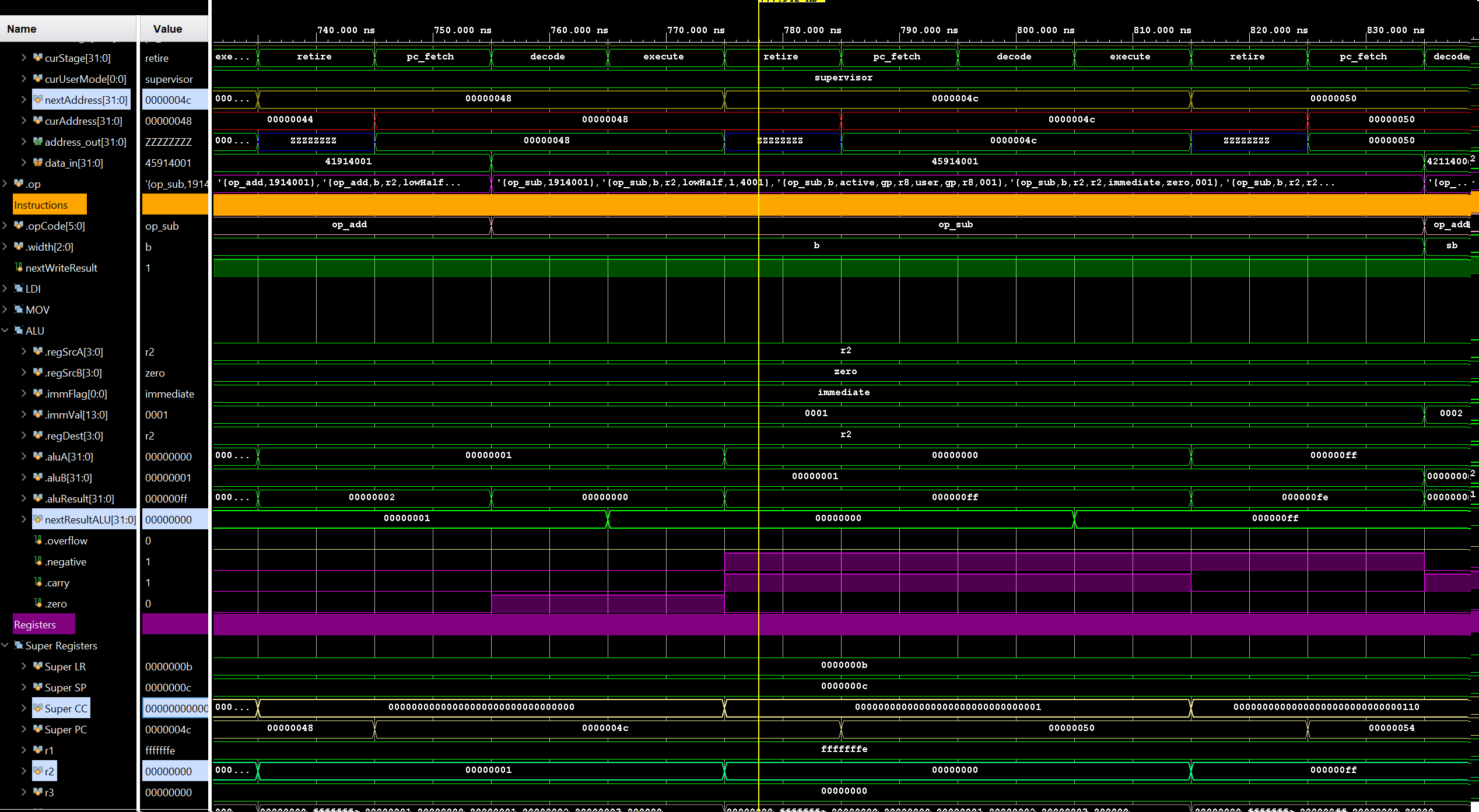
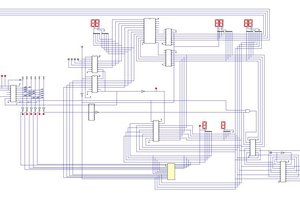
Armed with this newfound knowledge, I set out to design my first CPU. I made some initial executive decisions, like 32-bit, little-endian, load/store RISC architecture, etc. Some of these decisions, like 32-bit, are more for ease of development than historical accuracy, since programming in assembly on 8-bit CPUs was not done for fun back in the day, but because there was no other option for low-cost hardware. If the people programming for the Atari 2600 could have done so on a 32-bit CPU, I’m certain they would have as well! Once I had the basic instruction set designed, I created a very simple assembler and emulator for the CPU to test it out in theory.
The next logical step was to design a video chip. I decided to go with something very similar to the TI 9918 (as many of the systems of the time did) with various tiled display modes and some sprites. Also, since each display mode is a separate entity, I could just implement one at a time, the first being a 80x44 tiled text mode with a 16x16 character 1-bit font containing up to 256 tiles. The first half of the initial font tileset was text and special characters, leaving the second half for graphics characters and other things. Later, I added sprites and other modes which allowed for moving objects on the screen, color tilesets, and scrolling or rotating backgrounds.
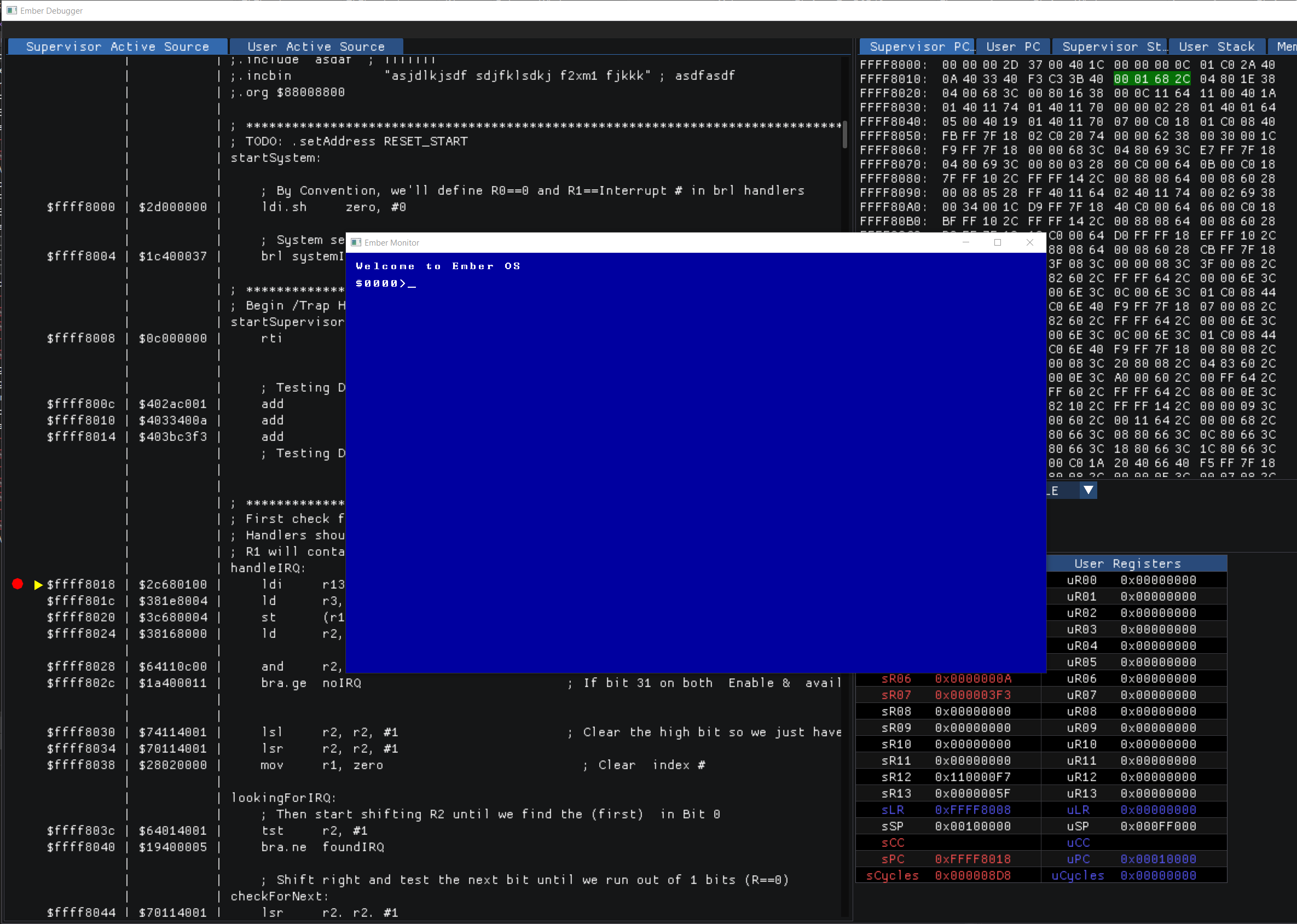
With a basic CPU and GPU implemented in the emulator, I next added an interrupt controller and IO support. This allowed keyboard and gamepad input. Keyboard support meant I could write a basic monitor program to display memory values or run programs, basically allowing interactions with the machine when running in the emulator.
At this point, I had the basics needed to implement simple applications and games, albeit without sound. However, my simple assembler was not up to the task. After some additional research, I decided to implement a native back-end assembler for Ember32 assembly language in LLVM. There were other suites I could have used, like gcc, however, longer-term I wanted to be able to write higher-level language applications for the system. Not only C/C++, but also RUST, Swift, or any number of others. These languages are primarily supported on LLVM, so that is what I decided to use.
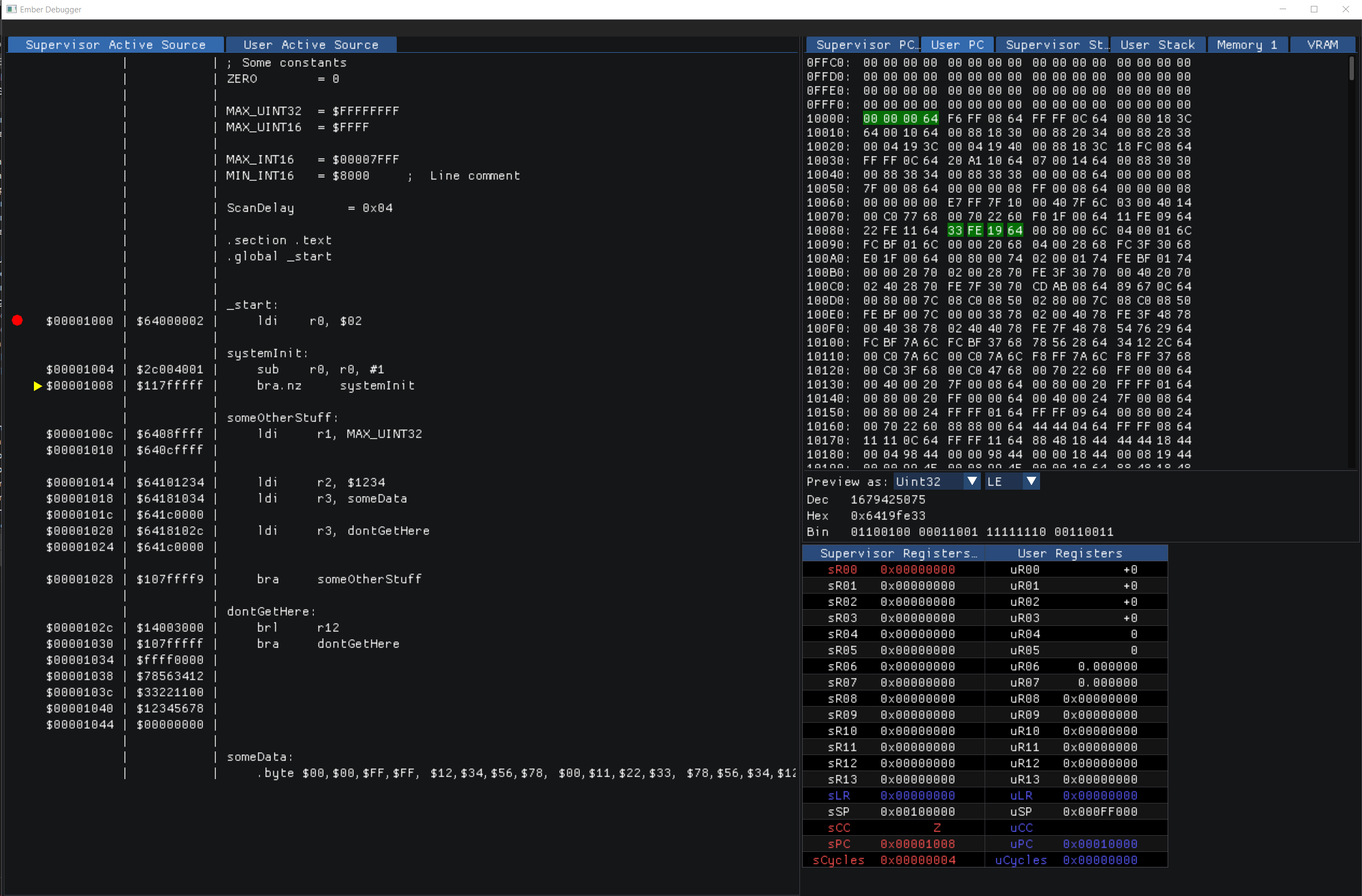
Integrating Ember into an LLVM backend was considerably more complicated than I imagined, based on what little documentation and information I managed to find on the web. What I thought would take a few weekends, ended up taking many weeks of hacking, with my day job and other distractions. However, I did manage to get it working and output Ember32 Elf files.
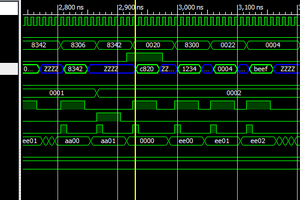
The next step was to implement an ELF loader in the emulator, and also support for DWARF debugging info in the ELF. So now I can load and run LLVM-generated ELF executables in the Ember emulator, and use the runtime debugger to step through the source running on...
Read more »











 Erik Piehl
Erik Piehl