 Shah Selbe
Shah SelbeThe FieldKit team is incredibly honored to be one of the 20 finalists in the 2019 Hackaday Prize!

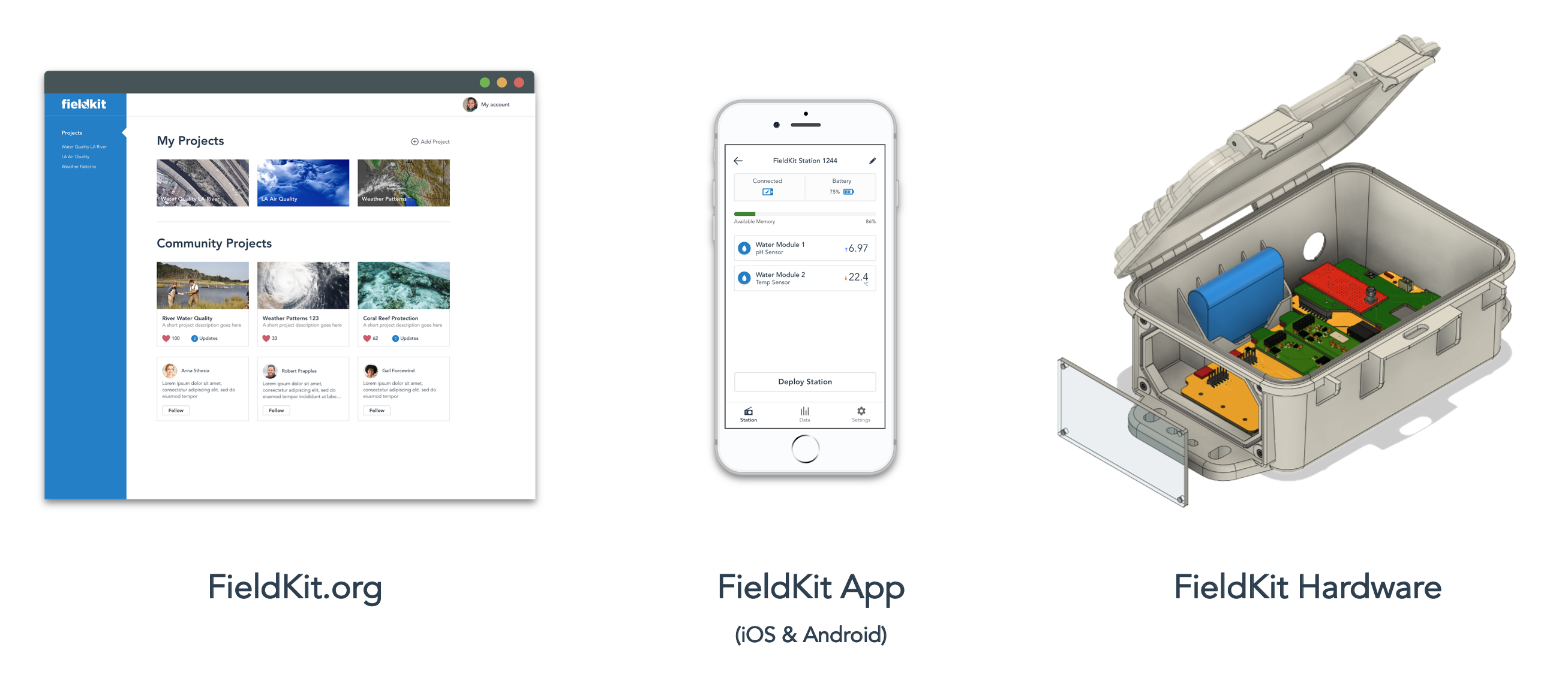
The Problem
Our understanding of this planet and how it changes has always been driven by our ability to measure and monitor key environmental parameters. In the past, this was a very labor intensive process where scientists would use custom specialized equipment to make observations over time. As technology advanced, so did our ability to make those observations. It allowed us to measure more areas, gather data at a greater frequency, switch over to digital methods, and measure with greater accuracy and precision than generations before.
These advances have allowed scientists (and now naturalists or citizen scientists) to monitor our changing planet in new and exciting ways. Up until very recently, those tools were produced by only a handful of for-profit organizations using proprietary designs at expensive price points. More often than not, those tools often lacked a strong software component to complement the hardware. This availability problem has created a rift, where the ability to do good science or effective environmental monitoring was only available to those with the most resources. In our experience working in the field outside of the United States, we’ve found that these tools are very rare and increasingly difficult to obtain.
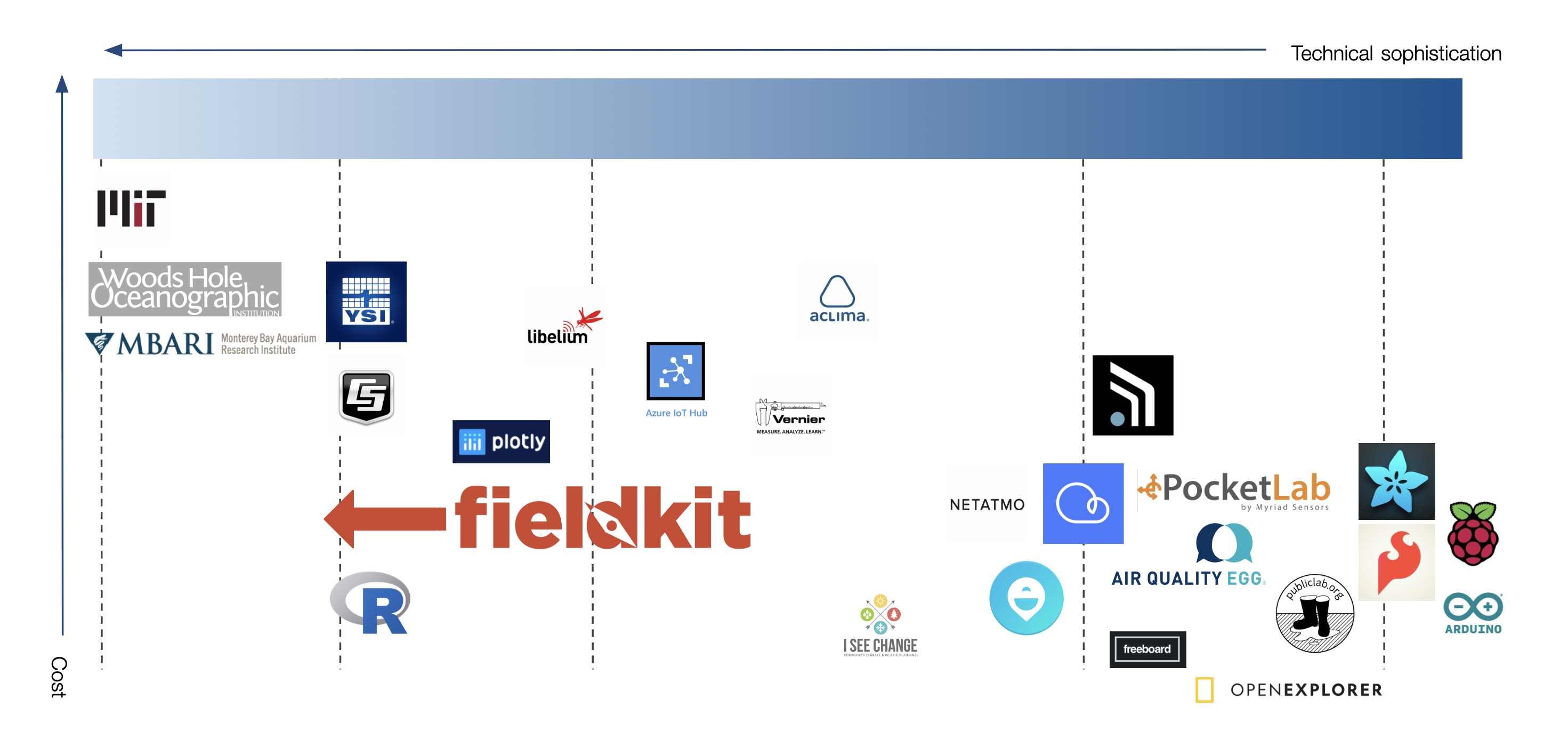
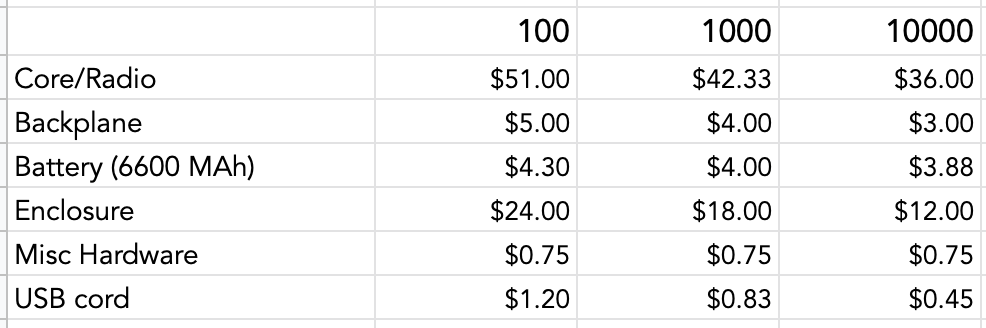
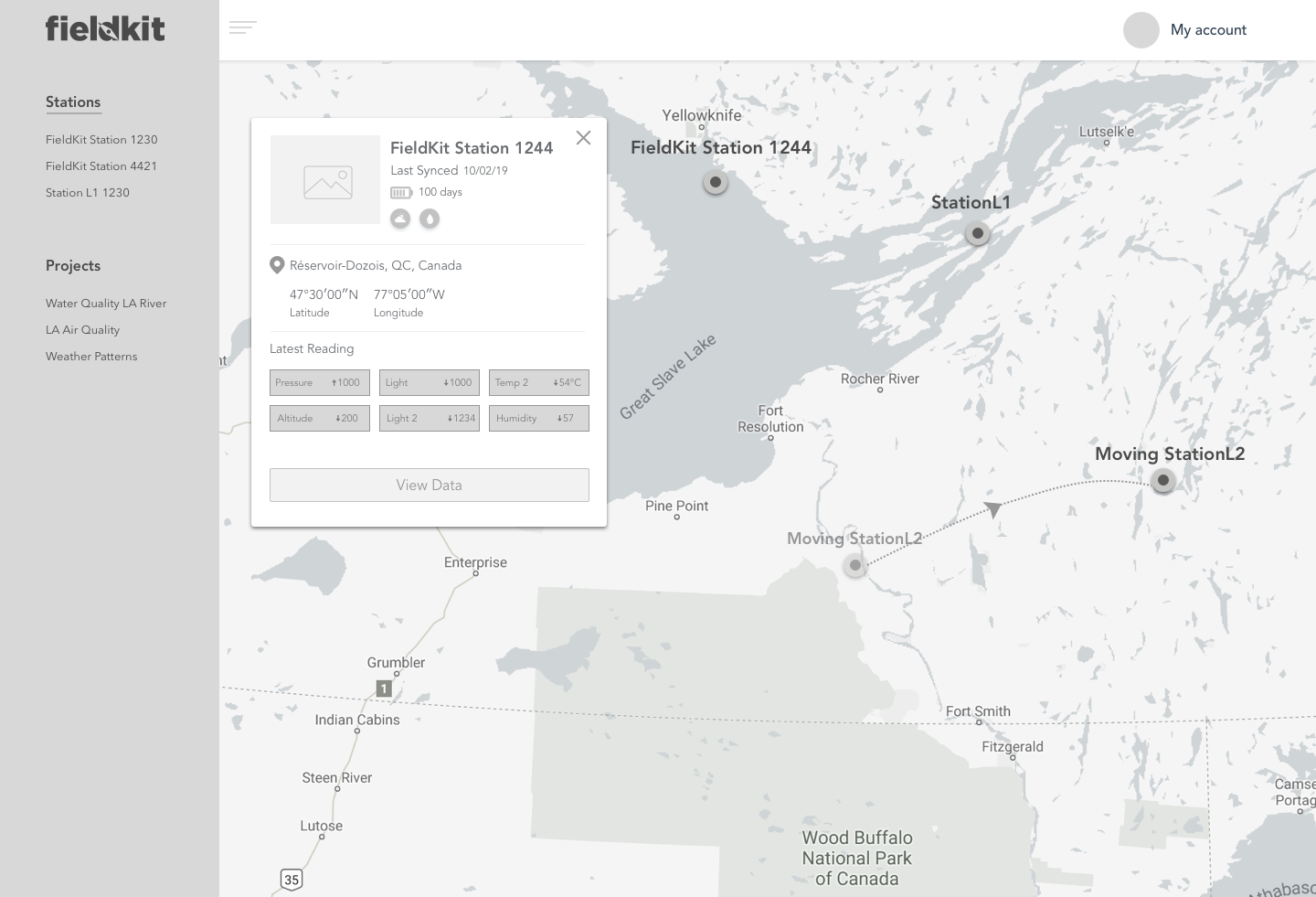
As completely apparent through the diversity of work here on Hackaday.io, the incredible explosion in accessible technology and manufacturing has created considerable opportunity to rapidly build and prototype new tools across industries. With FieldKit, we are working to bring this innovation into the field of scientifically-relevant environmental sensing. The current marketplace for these tools is polarized, with one side being made up of high-end and very expensive scientific sensing equipment and the other side being made up of microcontroller-based systems that use cheap and scientifically-meaningless sensors. Both of those product areas have a useful place with certain customers, but there was an entire segment of the market that was being left out. We found that there is a large gap in the industry where a modular platform could be designed that met the needs of science but aimed for the costs of consumer and hobbyist devices. Our goal became the following:

Our Solution
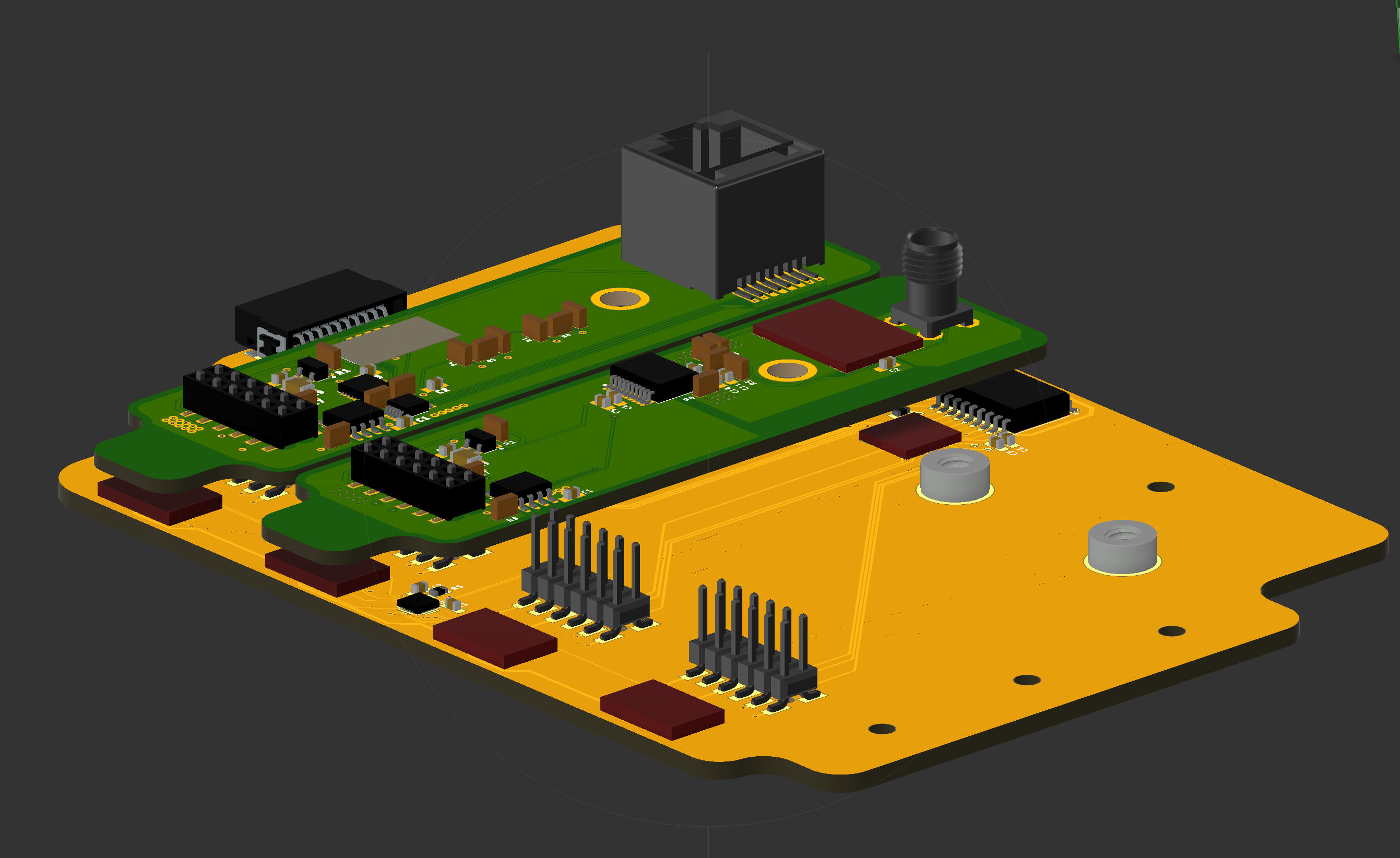
As we started designing FieldKit, we thought deeply about what it was that we wanted to create. We used our past expertise in designing conservation technology for the field with partners like the National Geographic Society and the Wildlife Conservation Society. We conducted rigorous prototype testing in the field in places like Botswana’s Okavango Delta and the Amazon Rainforest. We performed extensive user testing and expert interviews to better understand the needs of the community. We attended conferences and read academic papers that focused on environmental sensing technologies and its necessary metadata and data visualization needs. We tested some of the existing tools and tried to identify what was missing. Through that process, we discovered that there was a much bigger demand for these types of tools than we first expected. Up until that point, we mainly worked with field scientists and (in a much smaller capacity) STEM educators.

But as we ran through a rigorous user-centered design process, we started to understand that the needs were much bigger than that. There was a large community of passionate citizen scientists that were looking for more accessible scientific tools. We encountered a dedicated group of people working on environmental justice that wanted to have calibrated and verified tools to help document environmental decline. We heard from small municipalities that were...
Read more »





















 qquuiinn
qquuiinn
 Trey German
Trey German
 Dimitar Tomov
Dimitar Tomov
Love the project... Join elite, cost-free Telegram groups for crypto signals in 2023.
https://medium.com/coinmonks/top-10-free-crypto-signal-telegram-groups-for-2023-688c19014b1a
Top 10 Free Crypto Signal Telegram Groups for 2023
Free Crypto Signals
Crypto Telegram Groups
Crypto Pump and Dump Groups
Crypto Signal Telegram
Telegram Crypto Groups
Trading Signals Telegram
Best Crypto Signals Telegram