 MakerVisioneer
MakerVisioneer2017 HackadayPrizeFinal Video
GitHub: https://github.com/MakerVisioneer/prototype
Google Drive: https://drive.google.com/drive/folders/0B3wmJbFj6cTCTGMzemFlTmdGbnc?usp=sharing
The problem
Those of us who have never struggled with a vision impairment beyond a need for corrective lens may take for granted the ability to see obstacles and navigate crosswalks. These everyday activities can be challenging and intimidating for the visually impaired. Guide dogs are one option to provide assistance. However, access, cost, maintenance and/or allergies may make ownership impractical. 'Guiding Eyes for the Blind' estimates that “only about 2 percent of all people who are blind and visually impaired work with guide dogs.” (“Mobility” https://nfb.org/blindness-statistics)
Assistive canes have their own limitations. While useful to detect low-level obstacles and walls, a cane cannot detect head-to-chest level obstacles (i.e., tree branches). Assistive canes cannot identify obstacles, or detect a walk signal.
There are wearable devices in or near market to address some of these issues, but their costs are in the range of $2000.
How Visioneer works
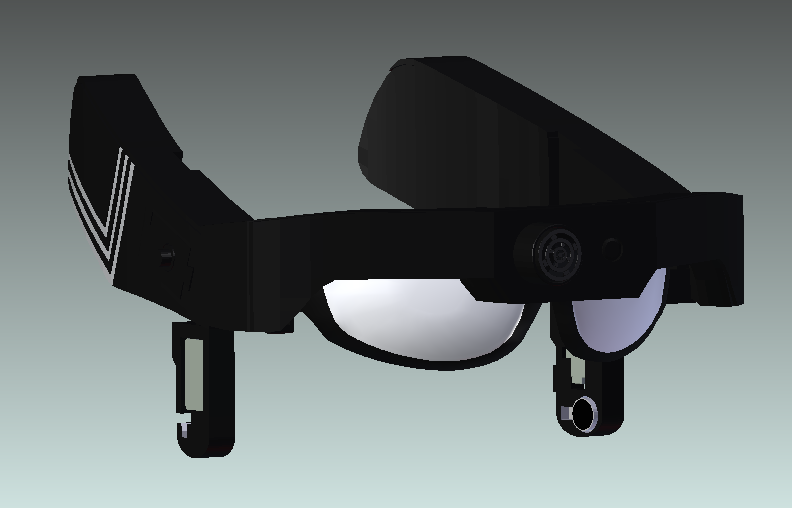
Visioneer, appearing as a set of sunglasses, can
- alert the wearer to obstacles,
- notify the wearer of an intersection button to trigger the walk signal,
- recognize the walk signal, and
- provide vibration feedback to keep the wearer on a straight path while crossing the street.
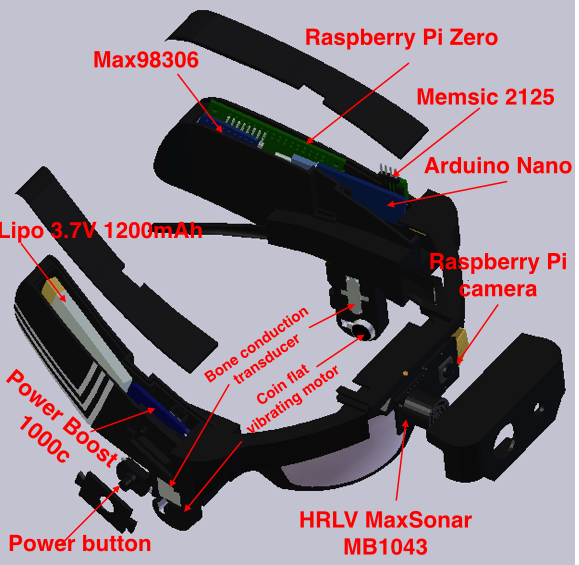
Visioneer performs these functions using a camera, sonar, and a combination of OpenCV and a local neural net on a Raspberry Pi. Feedback is provided via a bone conductor and vibration sensors. These methods provide the necessary information, without interfering with the wearer's ability to hear normally. The use of bone conductor provides a novel way for blind navigation devices unlike other conventional navigation devices. According to an article in Blind.tech, unlike regular headphones, when crossing the road, bone conductors help prevent the information loss from the surrounding environment. When they are combined with a smartphone, giving access to important sources of real-time information like: navigation services, the status of public transport lines, the weather, news and music, just to name a few.
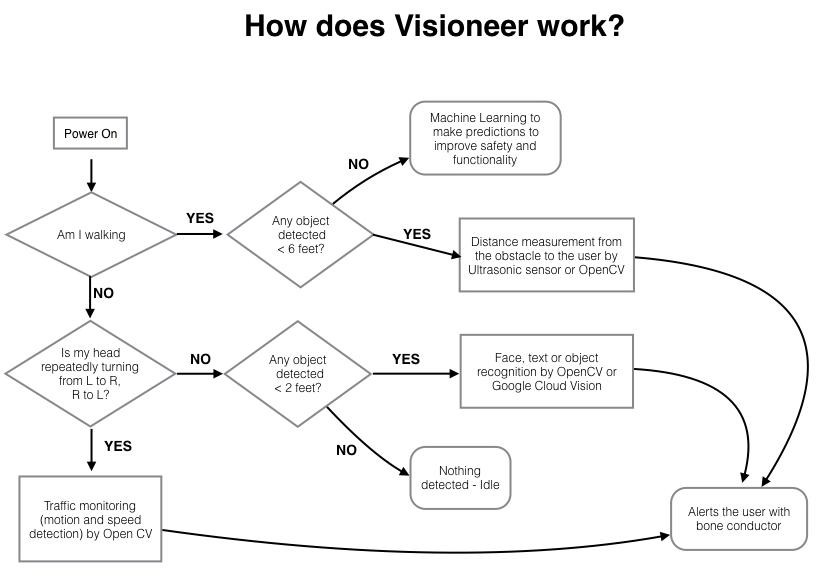
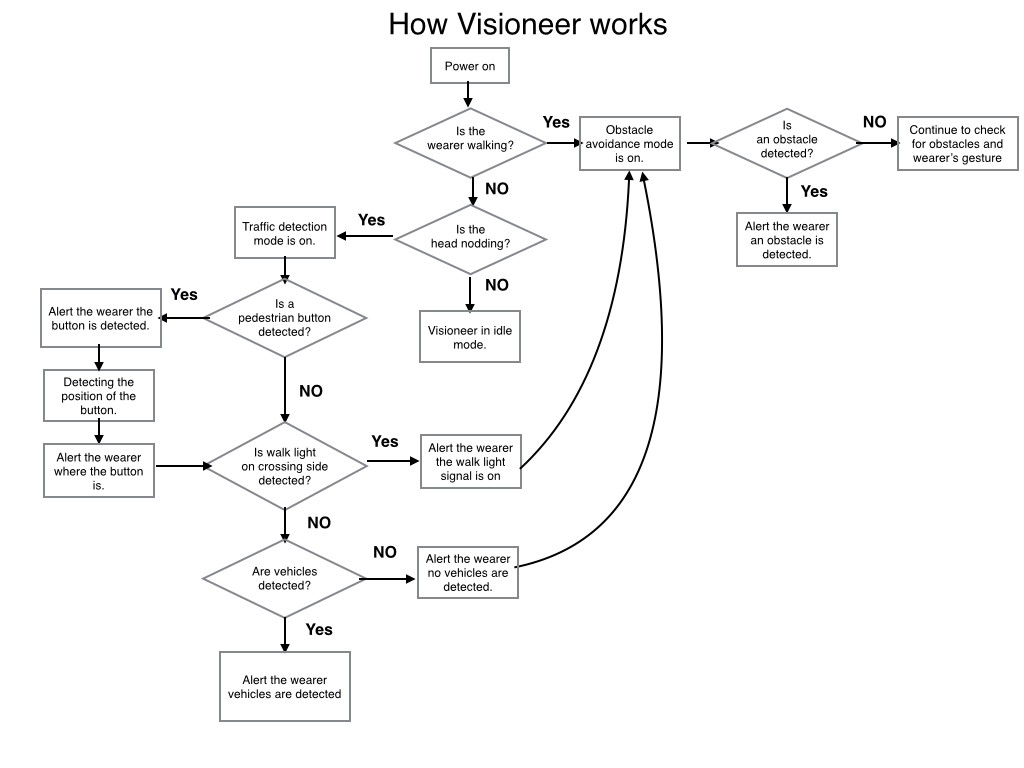
Usage Flow Diagram (V1.0 - see logs for updated flowchart)
To illustrate how Visioneer works, we drew the flowchart shown below. The key here is to first determine whether the user is walking or stationary. This makes a difference in how the user interacts with their surroundings and decision making. When the user is walking, Visioneer's obstacle avoidance ability will come into play. When the user is stationary, that signifies to Visioneer that the user either is trying to identify something at a near distance or waiting to cross the street. The easiest way to determine the user's situation would be to use speech recognition but considering its unreliability and potential social awkwardness, we decided to go with other options that include the combined use of software and hardware components.
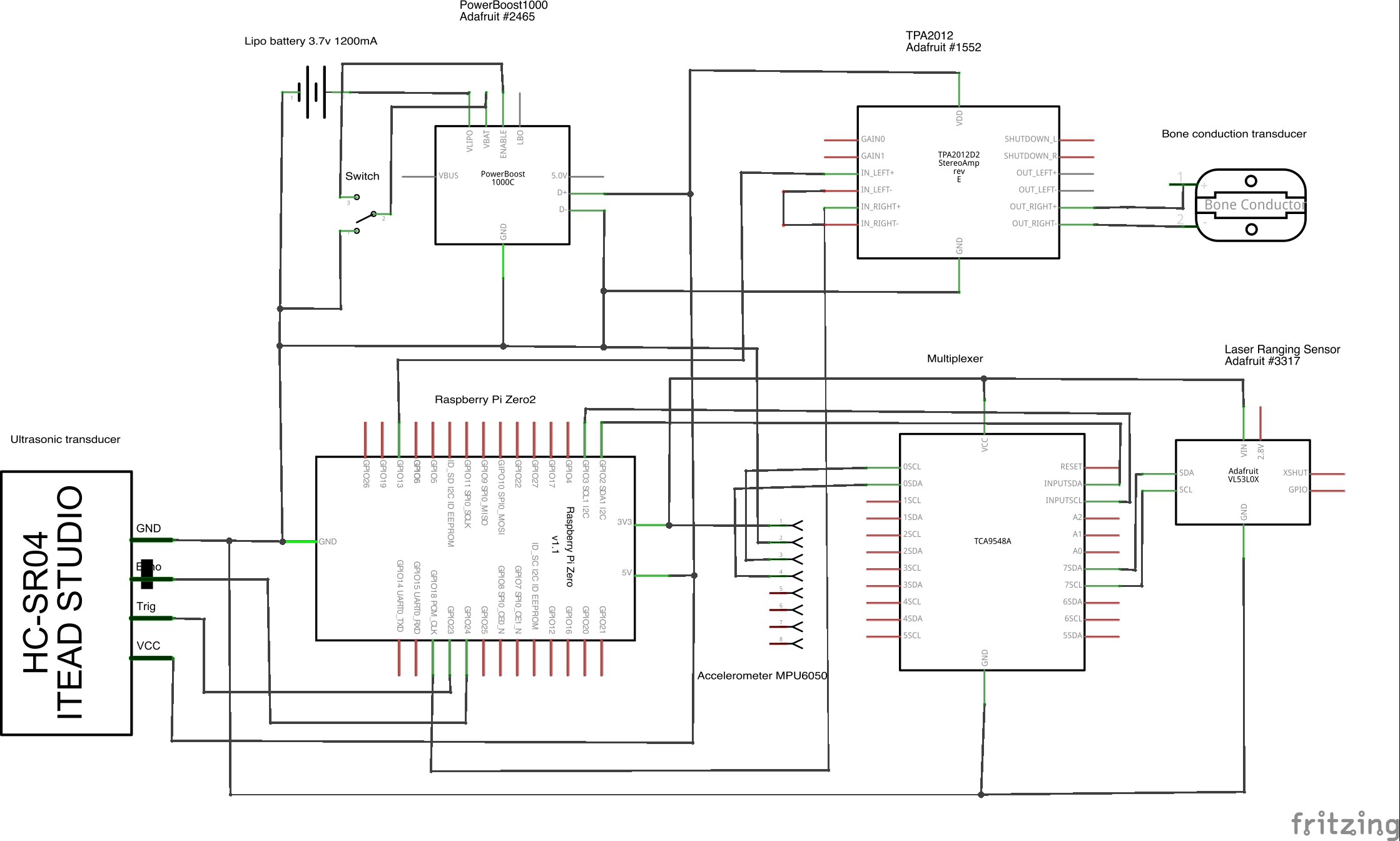
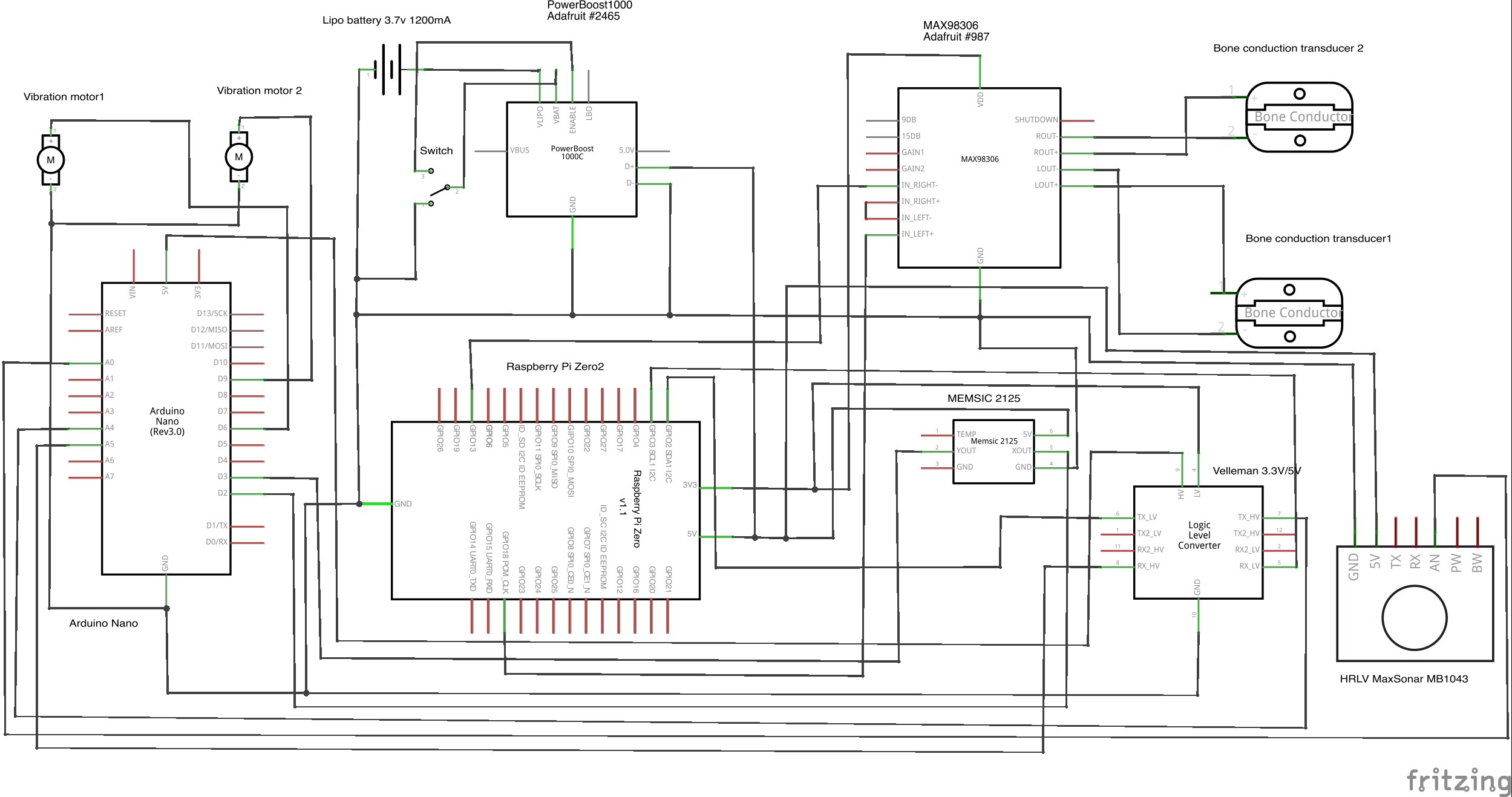
Schematic (First Draft) (V1.0 - see logs for updated schematic)
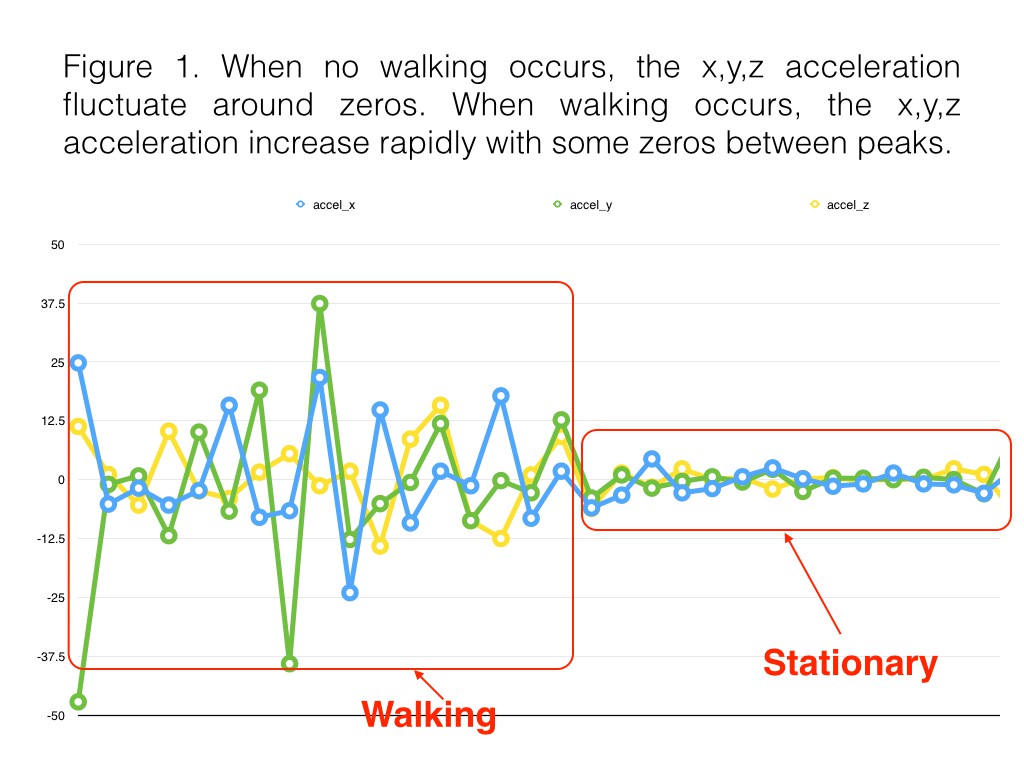
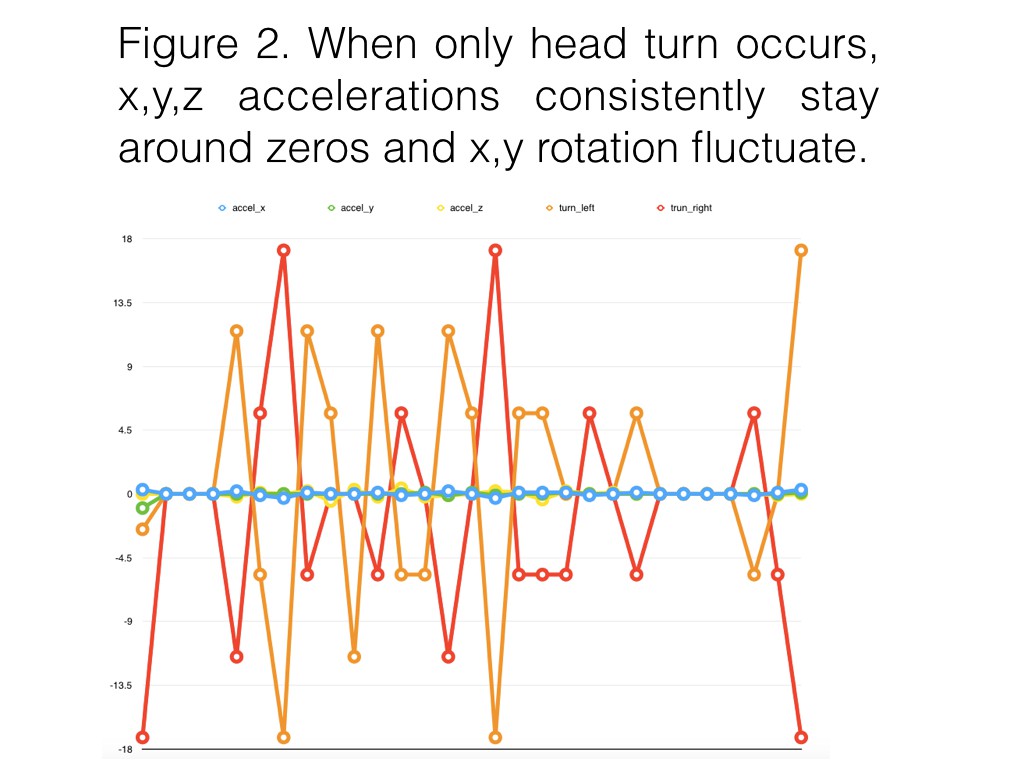
Based on the usage flow diagram, we decided to use an accelerometer to determine if the user is walking or stationary. We use OpenCV to perform obstacle avoidance. To determine if the user wants to identify something at a close distance, we use lidar. If the user is stationary and isn’t close to any objects, OpenCV and a local neural net will identify surroundings to determine if the user is looking at traffic or other objects. Everything will operate on a Raspberry Pi Zero.









 Anand Uthaman
Anand Uthaman
 Myrijam
Myrijam
I've tinkered a bit with OpenCV and the Raspberry Zero. Check out this example code that efficiently captures frames from RaspiCam: https://gist.github.com/CarlosGS/b8462a8a1cb69f55d8356cbb0f3a4d63#gistcomment-2108157 You could probably get a decent frame-rate by reducing frame size and processing only the luminosity channel. Let me know if I can be of any help! And best of luck with the HaD prize finals!!