 Dan Schneider
Dan SchneiderAdvancements in independence for people who are blind began cropping up shortly after World War I, due to the prevalence of war related injuries and through necessity as city streets began filling with automobiles. In 1928, Morris Frank introduced the first Seeing Eye dog. The ubiquitous "White Cane" was introduced in 1930 by the Lyons Club, and in 1944, Richard Hoover introduced the Hoover Method using a long cane.
Then there was nothing. There have not been any significant improvements to the independence or mobility of people who are blind or visually impaired since the second world war.
Several notable individuals have demonstrated the use of echolocation to navigate new environments, and in some cases even ride a bicycle. These case studies have illustrated how adaptable the human mind is to new kinds of inputs, and how well humans can perceive their environments with only minimal feedback. With 3D sensing and robotic vision systems growing by leaps and bounds one can't help but wonder, what could humans accomplish with more information?
Thus the goal of SNAP is simple, if not overdue: create a highly detailed acoustic picture of the environment, and let humans do what they do best. Adapt, and impress.
The success of SNAP relies heavily on our innate ability to locate objects in 3D space. This ability, called "Sound Localization", is achieved through binaural hearing. Much like binocular vision, which grants us depth perception, binaural hearing lets us compare incoming sound as it is heard by each ear to triangulate the origin. For more details on how this works, see Binaural Hearing and Sound Localization in the project logs.
SNAP translates spacial data to an audio signal, and uses sound localization to make it seem as though the sounds originate at a location in space corresponding to real world objects. Position in the sagittal axis is indicated by variations in wave form or pitch, while distance is indicated by varying volume or frequency, with higher pitch being closer. For sighted individuals, this will sound like all of the surrounding objects are producing white noise. For non-sighted individuals, it will paint an acoustic landscape, allowing them to see the world around them using their ears.
At this time, SNAP exists as both a simulation and a hardware prototype. The simulation lets users navigate a virtual environment using binaural feedback as described above. The goal is to collect data from large groups of people which will be used to fine tune the system to improve usability and ensure that we provide the most intuitive acoustic feedback possible.
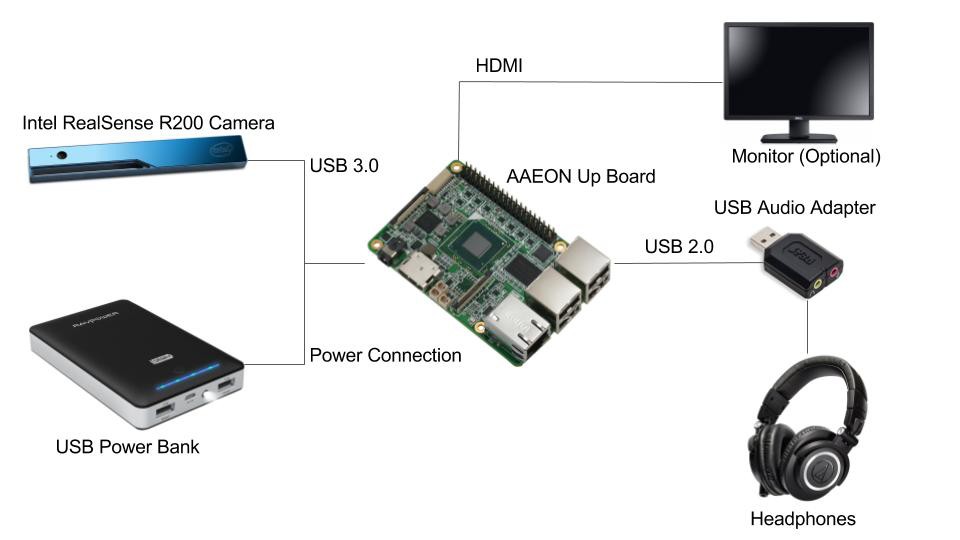
Our hardware has been helpful in discovering the limitations and strengths of acoustic perception, but it is far from ready for release. We are using an Intel RealSense R200 camera to provide a depth map which is then translated in to audio feedback. Eventually we will take what we have learned and invest in our own hardware, with a target cost of $500 or less per unit.
Third-Party Licenses and Restrictions:
Special Thanks To:
Colin Pate
Matthew Daniel
Eric Marsh
John Snevily
Marshall Taylor
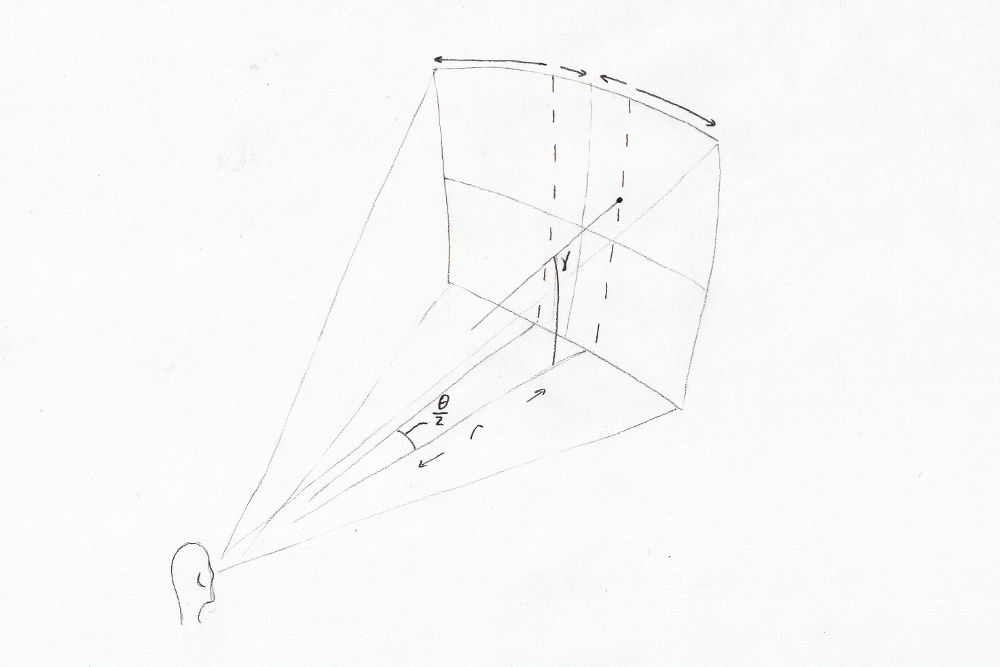

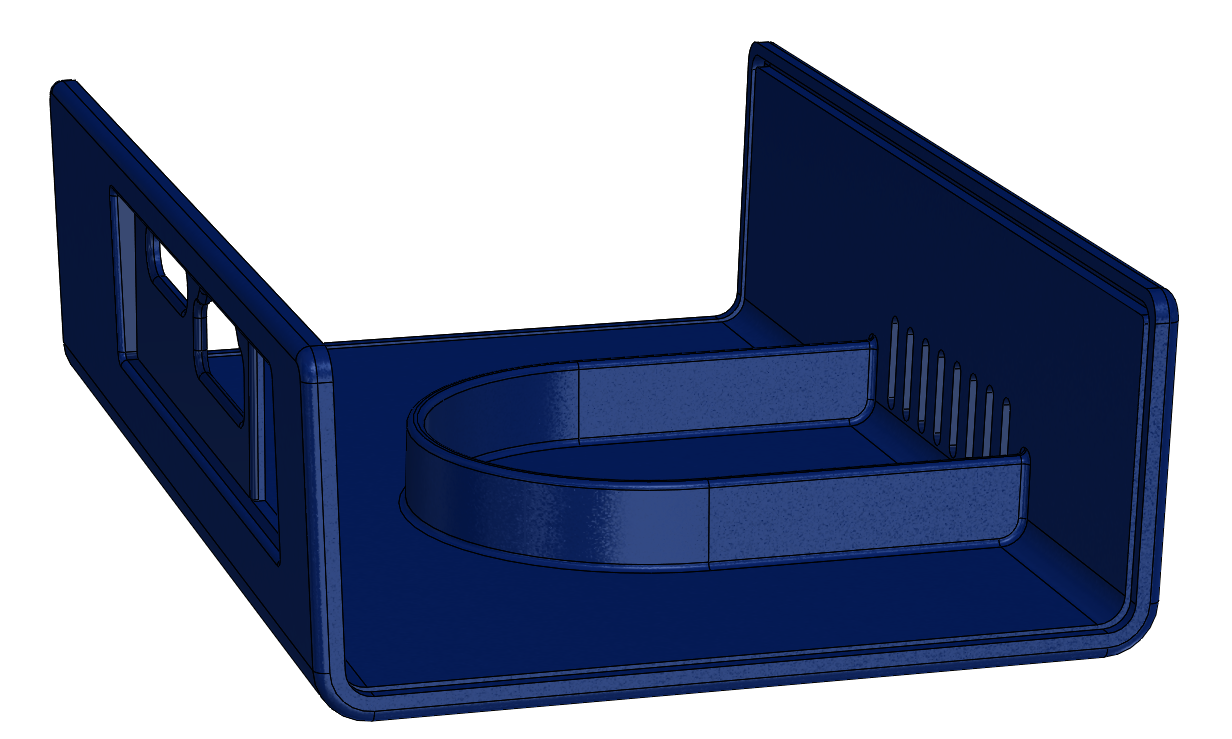

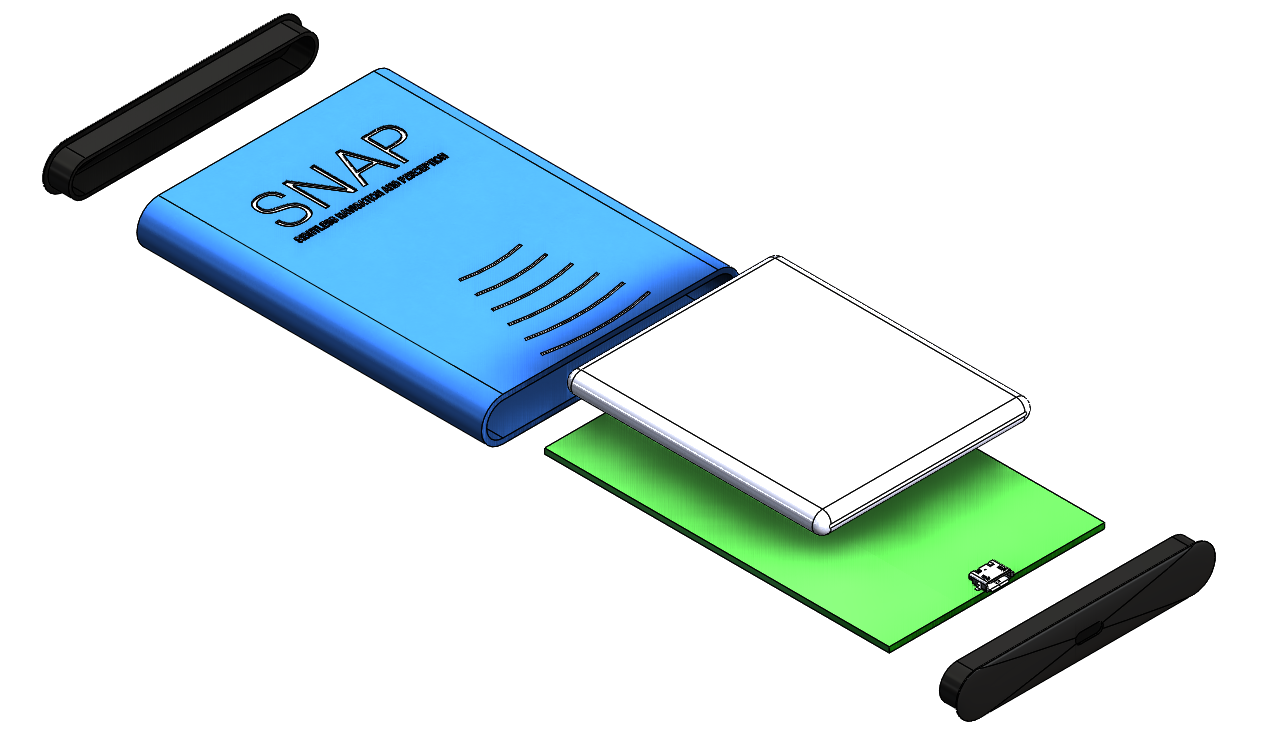
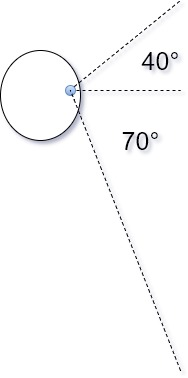
 Some considerations for a headset like this:
Some considerations for a headset like this:











 platis.solutions
platis.solutions

 Mark Mullin
Mark Mullin
Hey @Dan Schneider so I'm surprised I didn't see this until now... but anyways I LOVE this idea!
So we're working on a platform that might be interesting to you if you're still pursuing this. It's #Luxonis DepthAI and it allows depth vision and object detection so you can get real-time 3D position of objects of interest (in addition to the raw depth data, which could be useful here as well).
We'd be more than happy to send you one when they're ready if that's of interest to you.
Best,
Brandon