 ErwinM
ErwinMComputers have always fascinated me. I programmed in various languages when I was younger for fun. At work, people come to me with computer related problems and issues (alas). It was sometime last year, that one of my colleagues asked me in a casual way 'what is a kernel anyway'. I did my best to give him a (partly made up) explanation. The fact was, I didn't fully know the answer myself (I think he saw through it).
So when I got home, I started reading up on kernels. Still being interested in programming, soon after I decided I would program one, just for the heck of it. I started on one (learning c in the process), using the BOCHS simulater and learned about paging and context switching. But this site is not about that project.
As I googled terms such as stack frame and trap handler I hit Bill Buzbees website (homebrewcpu.com). This guy didn't write an OS, he designed a whole CPU! This was one (or several!) levels deeper down the rabbit hole. I found it very interesting, but couldn't conceive of doing anything similar. I kept reading up on CPU designs and the history of computers.
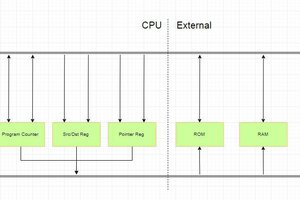
This led me to the book 'The elements of computing systems (Nisan & Schocken)'. As soon as I read what the book was about I ordered it online. Then, because I couldn't wait, found a pdf version and got started right away (I still received the 'legal' copy several days later). This brilliant book guided me to building, and more importantly, understanding a very simple CPU. I could now see how simple 1's and 0's got combined into more and more complex building blocks until you had a working CPU. As I worked through the chapters a voice in my mind started saying: 'now you could build that cpu, a real one'.
The final piece of the puzzle fell in place when I revisited Bill Buzbees website and read that he had plans to build another CPU. But instead of building it out of actual hardware components (coolest way by far), this time he would use an FPGA. I had never heard of FPGAs. But once I read up, I realized that if I used an FPGA, building a CPU might just be within the realm of the possible for me.
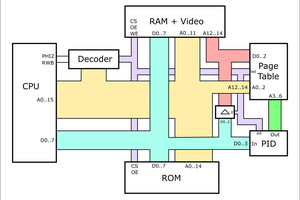
Thus started DME CPU.







 Erik Piehl
Erik Piehl
 aaron
aaron
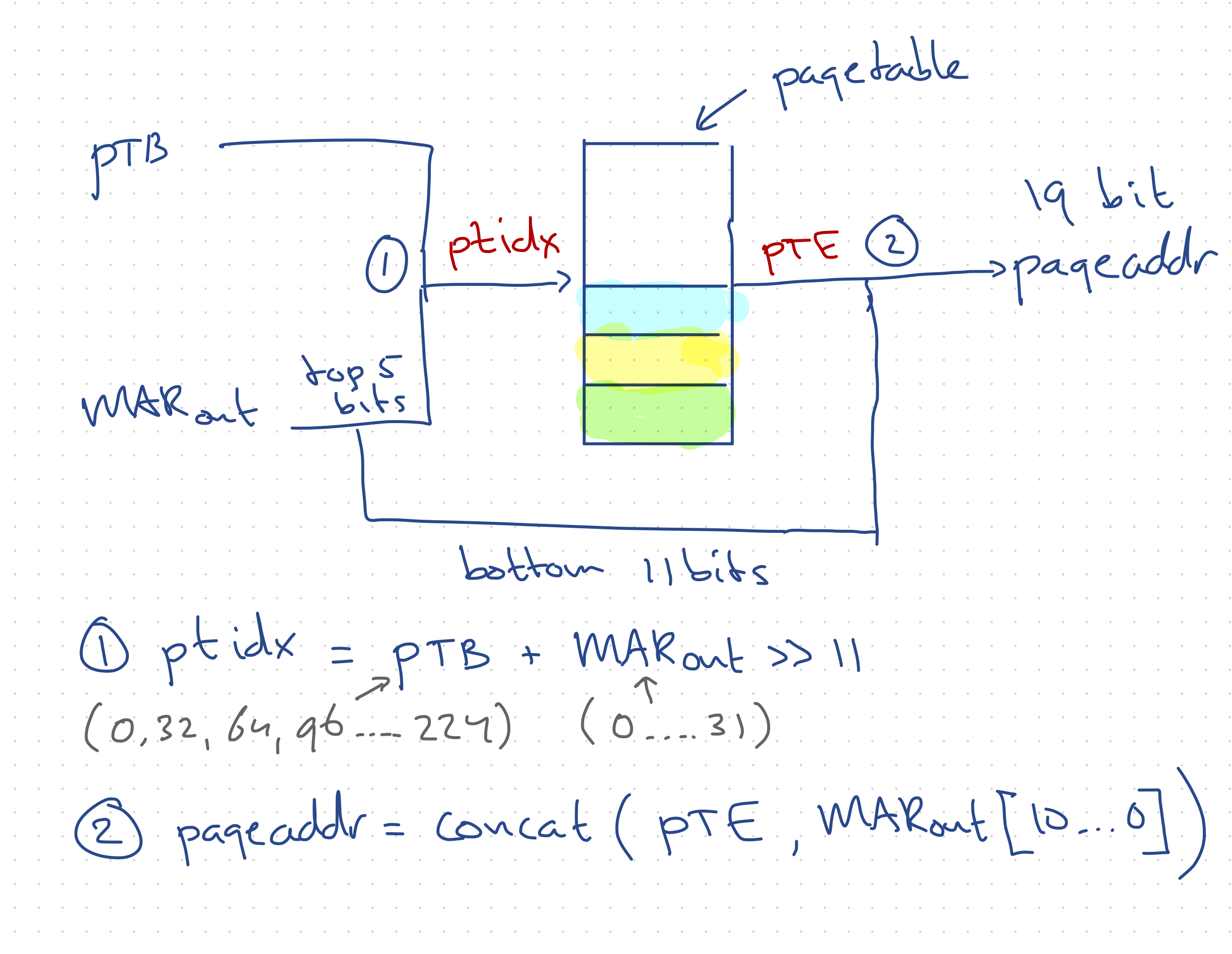
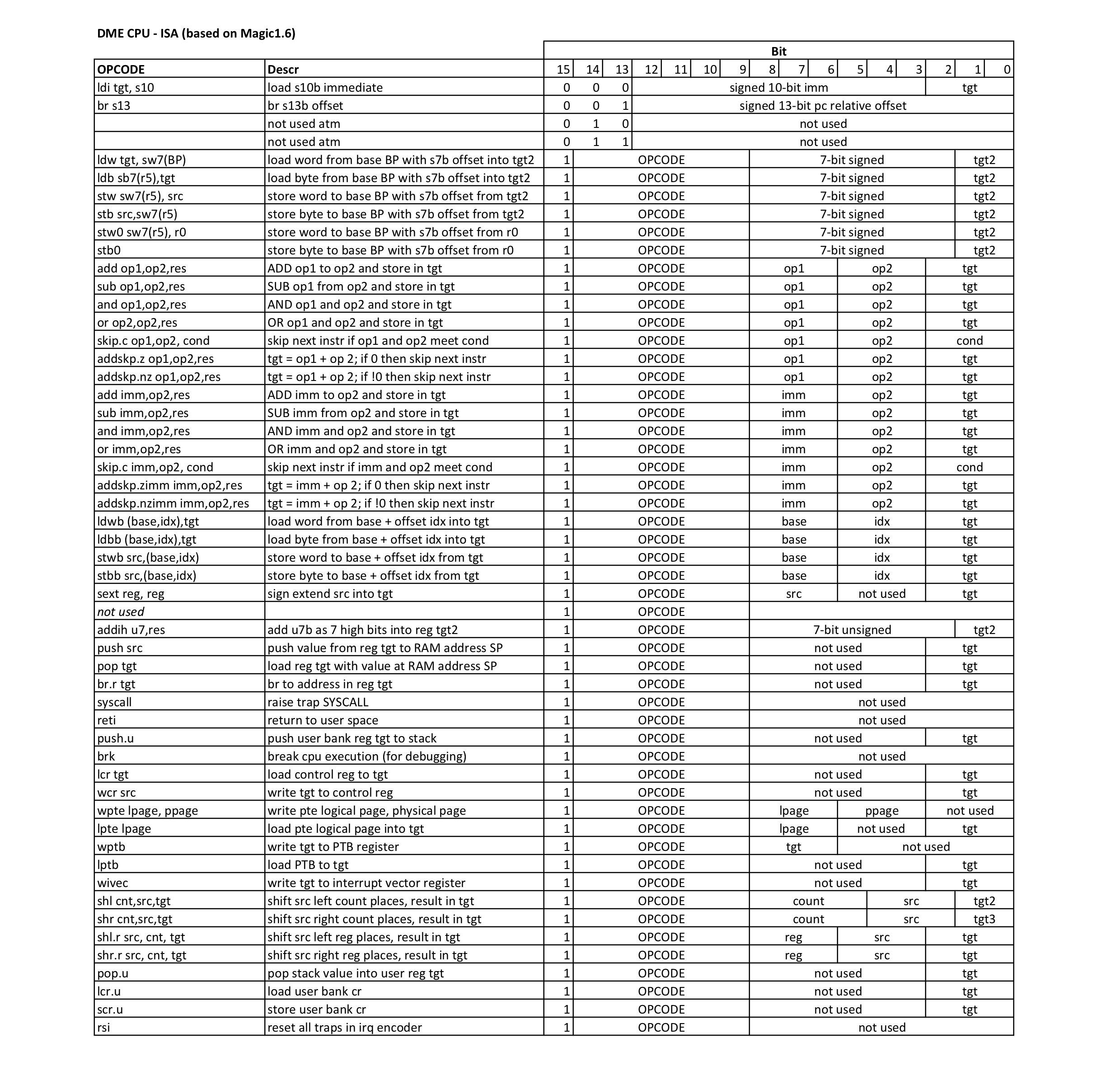
How did you implement paging? I found what I think is the code that does it in your cpu.v file (lines 296 to 334)? Could you give an overview of how the block of code accomplishes paging? Thanks for your time.
https://github.com/ErwinM/playground/blob/f0479f418f7a90c9aa1e85626ace54984fc94aee/cpu.v#L296