Yann Guidon / YGDES
Yann Guidon / YGDES-
SRB : Smooth Register Backup (it was nice)
04/05/2024 at 19:27 • 0 commentsFC0 had a great feature, one of its defining mechanisms, which was invented to make its 64 registers easier to manage during thread/context switching.
Each register has a hidden "dirty" flag, all the flags are set when the switch starts, then each time one register is accessed by the new program, it gets swapped with the saved version (if the flag is set). This provides a progressive replacement, which does not saturate the memory bus as much as a bulk save.
FC1 has 64 registers, too, but with 4 D-cache blocks, 2 ports each, so a broadcast instruction can send 8 registers to memory in one cycle. Saving the 56 scalar registers takes 7 instructions, 7 cycles. Massive parallelism makes SRB and its state machine moot, at least for the full-featured, full-width version.The goal is to keep the frequency high, hence the register set must be kept small and simple. So far it's 16 registers with 3R1W ports, replicated 4 times. Using a dual-banked register set doubles the size and reduces the clock frequency. This would be interesting for a multithreaded version, with 2 or 4 simultaneous threads to flood the EUs with useful operations to perform, the lower clock freq would be compensated by a better efficiency/reuse of the units/lower latency. But an idle register set is out of question: use the caches.
And the save/restore mechanism could freeze a number of cache lines on each D-cache block for a faster sequence.
-
Register spill
04/05/2024 at 14:18 • 0 commentsIn earlier logs, I was confident and convinced that the control stack should not be used to store general registers, for many reasons, such as :
- The control stack has 2 fields and only one would be used, leading to waste,
- Only one access (read/write, push/pop) would be possible per cycle (at first),
- Scheduling the write would be complicated, since several cycles might be required to read the register, thus delaying the effective operation...
But then I looked deeper at the IPC/IPE/IPR instructions and I'm reconsidering and adapting my previous position: yes there is a good case to save/restore a limited amount of registers on the control stack, and the scheduling issue is not an actual problem in this case.
The key is that the register spill on the control stack is only permitted for limited types of operations. The user code must still provide its own register storage space to save/restore the registers, which would be faster anyway (since FC1 has 8 read/write ports, it would take 6 cycles).
IPC has a few convoluted things to do, though it can be reduced to a jump where the 16 LSB come from the instruction's immediate field, and others (the new MID, the target module) from a register (<<16). The MSB are set such that the new address points to the "trampoline" address space. IPC writes a pair of values on the control stack: the frame pointer and the address of the IPC instruction itself. Then the processor goes into the "IPC_call" state, loads the new cache line and must check that the target instruction is IPE.
IPE is where more magic happens. If the target is not the expected opcode, it traps (nice, some registers are already saved), otherwise IPE is executed and pushes a new pair of values on the control stack: the Module ID and some metadata (such as general capabilities).
Then the target code must be able to check metadata from the caller: somehow the processor must write data to a given register, which needs more scratch space to setup a new environment. This can easily be solved by an ABI so the target registers are known to be overwriteable, but the control stack is progressively used for more and more functions like exception handling, traps, and more: the ABI can not be always enforced and the called code should not overwrite the state of the caller (or exceptions might fail to recover).
A scratch register area (like Itanium) is possible but moves more complexity to the SW and opens the gates of race conditions. So the stack itself is the best place, as it provides flexible, local, on-demand space. Traps can be nested without microcode or compromises.
So here comes the new class of instructions : SPILL. It writes a register to the stack (along with its number) and optionally writes metadata from the caller's state (such as TID, MID, metadata, it might evolve). So we get the SPILL imm, reg instruction that pushes the register on the stack while also overwriting it with the requested data. SPILL 0, R1 will save R1 and overwrite it with 0, but other numbers will write a specific/useful/relevant value (probably up to 255 possible info).
Why not combine this with the SR read instruction ? Well, the access rights, timing and datapath might be different. SPILL will focus only on a few context-specific information (a subset of the SR that will not trap) so a trampoline can filter requests hassle-free, almost immediately.
Once all the metadata are checked, the code can jump out of the trampoline area and into the module.
Then before IPR, a corresponding number of UNSPILL instructions must pop the registers and restore them from the stack. If IPR is executed before, the spilled values are skipped from the stack and lost.
IPR will restore the module ID and capabilities, but another cycle is required to restore the instruction pointer and the frame pointer. And it gets a bit complex and quirky because several cycles are needed. The first step is to enable/select the proper addressing space, while the second step loads the caller's original IPC instruction. This could take "a while" because a page miss could occur... Then when the instruction is loaded, the processor knows which register was used as a frame pointer, which can finally be restored.
Important note: the IPC instruction is executed twice !
- First during call: push a pair of data and get the target address,
- Last at the end of return: the IPC opcode is re-checked, and the frame pointer is restored by reading the instruction again.
So depending on the state of execution, call or return, the instruction behaves differently. This also double-checks that the return has not been tampered with.
Furthermore, execution of SPILL and UNSPILL can be limited to the trampoline area.
...
And now that I think of it, the stack layout and the instructions could be modified, such that the return is faster, more convenient.
- IPC handles the frame pointer and the capabilities
- IPE/IPR handles the Module ID and the instruction pointer
This way, the IP is available at the same time as the MID for a faster return, in case the target is still in the instruction cache.
-
Read-as-Zero
04/02/2024 at 05:00 • 0 commentsThere are two cases where it is beneficial to flush or clear data without overhead : registers and data memory.
Register set protection
Registers would need to be flushed when calling an unsafe/unvetted module. In this case, it's a per-register attribute that can be set, for each globule, to mark the 4×16 registers as "trap on read" to prevent leaks without writing each register individually. The mark can be removed by writing a new value to the register. This is also a nice safety feature during debugging : the trap can be hooked to help trace a bug for example.
Memory initialisation
A whole cache line (256 bits ?) and even a whole page could be marked as "RAZ" to speed up initialisation. All the bytes get marked as "dirty" and "cleared", and the whole line gets written back to main memory during a flush/replacement. It is particularly handy for initialising a stack frame during a function call (or flushing it upon return).
-
Exceptions
04/02/2024 at 03:48 • 0 commentsThe "everything is a module" mantra makes many things easier.
One example is exceptions : when a handler is enabled and configured, almost any exception can be transformed into an IPC opcode to a given module (could be #1) with the entry point hardwired as the exception number << 16. That's 2048 entries with fast execution. Since IPC already saves some essential info on the control stack and the trampoline area acts as a table, there is very little extra HW to add.
Furthermore, since the trampoline zone is configured per thread, the exception handler can be swapped for a given thread, during debugging for example. Or a custom page table miss handler can be provided. This adds even more flexibility and allows novel extensions.
-
Access rights and capabilities
04/02/2024 at 02:43 • 0 commentsAs mentioned before, FC1 is built around a microkernel-like/actor organisation where there is no kernel, driver or user program, only modules.
So how does a module do its job ? Easy answer : its code must have certain rights.
And should the rights be tied to a module or a thread ? Both, in a way.
A "naked" thread (for example your basic "hello world" program) can still perform many functions by having no right by itself, but it calls modules that are endowed with specific rights and vetted by the OS. In the example, the naked thread calls a print function located in a different module, which can access the input/output operation itself, without leaking the "right" back to the caller. It's a sort of delegation.
A debugging program needs extra access rights, which should be preserved through calls to different modules.
But then the processor needs a way to vet each operation, either a specific opcode or access to a specific configuration register.
The processor knows the TID and MID (Thread IDentification number and Module IDentification number) which provide an index into an access right table, which is read again after each thread swap and/or IPC/IPR instruction. This is quite heavy and best done in software, for obvious speed and scalability reasons.
More pragmatically there are two simpler methods:
- The thread has a hidden "capabilities" word with a limited number of "rights" that are set by the OS during initialisation and ORed with the capabilities word of the module being executed. This limit in size permits only general/generic rights to be set, such as access to the stack, access to the code space...
- More specific rights are handled at the Special Register level, and tied to either a given module or thread : a single bit (MSB) selects whether the field is a TID or MID. This is preferred for scalability (there can be any number of these access right registers) and this tightens the security model, where usually only one thread or module has access to a given resource, limiting the chances of race conditions and abuse.
One exception : Thread #0 has all the rights since it initialises the system and manages all the other modules. It can then choose to endow a given thread with the required rights after some software filtering.
This dual system is flexible, scalable, and granularity can be adjusted.
- Usually a resource (for example exception table or page tables) is created at the HW level and one module (like page mapper ?) is assigned to manage it. Every module must be reentrant and enforce serialisation (through semaphores) so a "driver" is one module that safeguards one (or more) resource.
- If the resource is accessed by more than one thread at a time (a debugger ?) then the associated capabilities (access stack and/or code ?) are moved to the per-thread attributes. But this is less related to low-level HW access, which is guarded by Thread #0.
Both of these methods are easily implemented in HW without microcode or sophisticated circuits. In other words it's "RISC-friendly".
-
Pointers and conditions
04/02/2024 at 01:41 • 0 commentsThe project is about more than developing a processor : it reconsiders the whole programming model.
This had already started with the YASEP, following all the concerns we had found with FC0. FC1 is the testbed for the POSEVEN programming model and I try to anticipate the requirements and consequences.
POSEVEN follows several of the #PDP - Processor Design Principles, in particular the principle that every resource of a given thread should be accessed by a single pointer, but it does not follow the "flat model" that Linux or Windows use. Historically, it could look similar to some old IBM mainframes.
The reason is to avoid "segments" at all costs since they are a false good idea that make life miserable in the end, because it's not RISC at all. But "canonical RISC" itself has its downsides. I'm exploring that with the definition of POSEVEN and I have come up with several guiding principles.
The pointer's MSB is the private (1) / public (0) flag.
Threads can send pointers to other threads or blocks of code, but there is a need to protect "private data", just like in classic object oriented programming. The public addressing space is shared and accessed by every thread as a common pool, following rules enforced by paged memory protection. See later. The private space can only be accessed by the thread and contains all the necessary states.
The code and data spaces are strictly separated: this is a Harvard architecture.
Yet there must be a single pointer format to access all of it so the 2nd MSB means data (0) or code (1). No "normal" thread can access the code section as data, to prevent self-modifying code, exploration or alteration. This prevents introspection along with gadget-oriented exploits. Only a certain capability/right can write or read the code section during setup, to protect the integrity of the system, and this is not performed through typical data access to prevent hardware race conditions.
...
Stop for a moment. There are 4 combinations now:
- Public data : a pool of space where threads can store/send/receive blocs of data that don't fit in the registers.
- Private data : the internal state of the thread
- Public code : wait, what ?
- Private code : what the thread executes.
The list is not yet finished but it's already a bit weird. What is "public code" ? It's a space where the processor maps trampolines/entry points to other software modules. Oh, I should have introduced that earlier.
A thread executes code provided and vetted by the operating system. There is no notion of program, driver, kernel : only modules. Every code is provided by a module and each module is mapped to a code space. Invocation of a module requires loading the module, mapping it to the appropriate space, fixing addresses etc. then the thread jumps (with a specific instruction : IPC) to specific addresses in the trampoline area, where the called module "filters" the request. This trampoline area is shared and accessible through the public space, though page mapping (specific to each thread) can make each module visible, invisible, or even redirect one module call to another module.
The IPC opcode provides a direct 16-bit offset into the trampoline to avoid indirect access and reduce the hardware complexity of invoking external code. This requires support from the OS but the implementation is fast and simple. This provides 64Ki instructions to jump to, and the jump must land on an IPE instruction, which provides extra information from the caller to the callee, such as thread id or eventual capabilities. To return from the callee, the code uses the IPR instruction.As a consequence: a page for code has a granularity of 64Ki*4=262144 bytes.
There must also be a space that contains all the constants, in a read-only space that is shared by all the threads that execute the given module. This is not a candidate for the "public code" space because
- The code space is addressed with instruction granularity
- The data space is addressed with byte granularity.
Module constants may be mapped to the shared/public space or a s
The control stack is a third separate addressing space.
Yet another space is required for the control stack : is it neither code or data because the granularity is 2 words (either 2×32 bits or 2×64 bits).
This space can not be directly accessed : the control stack is a separate hardware/system and special instructions are required to read or write to it, if permitted by the thread's capabilities.
The thread can create its own software data stack to provide space for local variables : this is normally located in the private data space.
Normally, the control stack pointer is not accessible by the thread so there is never a dereference to a stack pointer. Thus there is no need to allocate an addressing space visible to the thread, however it must be mapped by the paging system.
_________
To support these features and others, the CPU must provide means to test a pointer. A certain class of condition codes is introduced to test the 4 MSB and 4 LSB of a register, because it can contain a pointer with metadata. The conditions
LSB0 (odd/even address, 16-bit aligned) LSB1 (32-bit aligned) LSB2 (64-bitaligned) LSB3 (128-bitaligned) MSB0 (private/public) MSB1 (code/data) MSB2 MSB3
are provided in the instruction set, they are easily implemented with a MUX and/or the "shadow" bits of the register set. A thread can easily verify that a pointer sent by another thread is valid and extract its properties (like the type of Aligned Strings).
-
Tagged Control Stack
08/08/2023 at 03:25 • 0 commentsTagged registers (see 14. Tagged registers) might not be the best idea ever. OK. But my latest musings about the stacks (#A stack.) and the support from various languages made me realise that a different view is necessary.
The usual C stack is a merged Data + Return + frame stack with many problems. FORTH (among a few others) uses a split system with Data separated from Return. And some languages implement their own data stacks for large variables that must be accessed by the caller.
There are also other things to consider : scopes.
Scopes can be a (set of local) variable name(s) or an error handler (try/catch) : they have their place on the stack because they need to be rewound in inverse order. I doubt it's a good idea to create a separate stack for error handlers, they belong to the "return stack" IMHO, otherwise how do you know where to reset the stack pointer ?
So I have just had this really weird idea : tag items on the return stack with a type.
For example we would have the usual call/return type for function calls, as well as the handler type for nested functions. A "canary" type would also help detect an error, for example. But imagine that the MSBs of the pointer (for example, could also be LSB so normal return goes to aligned words...) that is pushed on the stack flags an error handler.
- When a "normal" return instruction is decoded, the CPU keeps popping the return stack until a normal return pointer if found.
- When an "error" instruction is decoded, the CPU keeps popping the return stack until a handler pointer is found, thus skipping the normal returns and short-circuiting normal progress.
There are languages that would be happy with such a HW-based support, and I have no clue how to hack C to perform this trick. But this is a reasonable, useful, safe set of features that can be implemented in hardware, even at the risk of having the return instruction potentially taking more than one cycle to complete.
...
So the CPU must support two sets of instructions to share the return stack (which is separate and HW-handled) :
- The call/return pair, for usual function calls
- the handler/error pair for error handling.
- For/Loop could also be handled this way ! (in fact look at the FORTH idioms that use the return stack for more inspiration)
"error" acts like a "return" as seen before but the "handler" instruction is not a call, instead it gives an address to be pushed on the return stack, so the instruction format remains the same, and it does not affect the pipeline's flow.
Of course the compiler must also ensure that context for the error can be reached, the data stack is not affected by these instructions so extra care is required for the frame. But that's not something that hardware must try to optimise.
What do you think ?
Another use of the scope is to automatically free resources that have been allocated. Ideally room is allocated on the stack, but open handles or complex stuff must also be popped off from some sort of something. So maybe a copy of the data stack pointer can also be stored, just like the "push bp" idiom on x86 function prologs, but automatic here.
........................
A "canary" type might not be necessary if there is a stack limit register.
However another required type is the IPC : Inter Process Call, which must remember the caller's address, caller's thread ID and potentially some other metadata/masks/flags...
........................
20230908 : I'm trying to make a census of the required codes. 3 bits should be OK.
000 is invalid/reserved.
001 is for catch/error handling. It is missing a "frame pointer" to recover local data though.
010 is for normal call/return
011 is used by for/loop.
100, 101 and 110 are for IPC/IPR (110 is the return address, as saved by CALL, 101 would be the ID of the calling thread and 100 could be a bitmask of the "masked" registers to prevent data leaks, or could be credentials...)
111 could be used for "chaining" when/if blocks are moved from/to main memory, some DMA would be required to maintain a linked list or remember the position, with some granularity. That would be critical to speed up swapping a context during a switch.
Let's see if this works...
........................
Thank you FORTHers ! https://forth-standard.org/standard/exception
-
Another cautionary tale... from Apple
06/04/2023 at 00:35 • 0 commentshttps://thechipletter.substack.com/p/the-first-apple-silicon-the-aquarius-7cb
It appears that Apple between 1986 and 1989 had a project so secret that I only hear about it now. The description of the architecture sounds very familiar :
Scorpius is a tightly-coupled multiprocessor CPU with efficient support for fine-grained parallelism; the architecture was developed to take advantage of the inter-connectivity of single-chip VLSI implementations. Scorpius is intended to be the processing element of a high-performance personal computer system constructed with a minimal number of components. A Scorpius CPU comprises four independent processing units (IPUs) which share access to separate instruction and data caches, a Memory Management Unit, and a Memory/Bus Interface.
IPUs have a small register-oriented instruction set in which all data access to memory Is done by register load and store instructions. (Register and word size is 32 bits.) Each PU has 16 general-purpose registers — a total of 64 for the CPU — and 7 local registers. Local registers include product, remainder, prefix, and various state saving registers. In addition, the four PUs share 8 global registers. Including interrupt, event counter, and global status registers.
SIMD (Single Instruction stream, Multiple Data streams). This mode corresponds to the usual View of parallel processing: each PU executes the same operation on different data streams.
...
I thought FC1 was original, hahaha.
OTOH it's interesting to see some sort of architectural convergence.
The Scorpius never delivered, due to complexity and compiler issues.
In the end, I know well that memory latency is what kills general-purpose performance and OOO of some kind becomes necessary. It's interesting though to see how close one can get to OOO-like performance without all the implied overhead.
...
Update :
-
Tagged registers
06/16/2021 at 23:26 • 0 commentsBEWARE !
That log might make you roll your eyeballs so much that you"ll see yourself cringing but it might also "solve" an old problem, in the sense that "solving" in engineerspeak means "moving the problem somewhere else". Hopefully it doesn't come back later to haunt you even more from its new residence.
Tagged registers were not present as such in FC0 but it contained "shadow" values, such as the zero flag. The LSB and MSB values are directly available in the register set (or a shadow copy somewhere else), so they could be used for conditional instructions. The Zero flag can be recomputed any time the register is written, either after a computation or context switch. This shadow mechanism is simple, cheap, non intrusive... Another register attribute bit would have contained the carry flag, but it was not considered "good" and FC0 preferred 2R2W instructions instead. It was still "fair game" though.
Now I'm thinking of something potentially much weirder than that, and I can already hear some of your sarcasm, of the kind "Why don't you go full iAPX32 while you're at it ?". I'll simply answer : "Because that's not the purpose", despite some temptations that are quickly swatted by the teachings of Computer Development History.
So let's consider our "Tagged Registers". To be honest, FC1 already has some "shadow flags" for some registers to help reduce checking bounds all the time, for example, when a pointer is stored, like when copying a valid address register to a common register : this would also propagate its TLB status as well, to prevent excessive TLB lookups and save some energy and time. This helps speed up jumps or passing parameters through function calls, for example. This again, this is "non intrusive" and hidden from the ISA, a mere convenience. If the shadow flag is invalid, you lost a few cycles and that's all.
But the ISA faces a growth crisis. The 2R1W instruction format already saves a little room by dropping 2 bits for one source register address, but that's still 6+4+6=16 bits and the opcode can only have 16 bits, of which 3 are eaten by the "size field". The basic decoding table for FC0 was:
000 scalar byte 001 scalar half-word 010 scalar word 011 scalar double word 100 SIMD byte 101 SIMD half-word 110 SIMD word 111 SIMD double word
Soon it appeared that this approach was still too limiting because you always need to handle something that won't fit these orthogonal yet arbitrary types. For example, some people will desire 128-bit integers, or 256 bits. DSP people love fixed point formats. Float formats abound and some "IA" (neural networks) algos want small numbers, while some crypto nerds wish for 512 bits. Whenever we define a size, it will be too large for some and too small for others.
Furthermore, most of the time, you will use only 2 or 3 types, which would reduce the use(fulness) of one bit. Wasting one opcode bit is baaaaaad.... One solution that was considered was to use a lookup table, which meant that you needed opcodes to read and set it, one by one... And since you can't count on people to agree, many of your function calls and returns would have to save that damned "Size LUT". What sounded simple and cheap seemed to implant its madness all over the code "just to be sure". And you would have to count on the LUT format to evolve !
Now, the "solution" I propose here might not be better, but it looks like a more serious alternative. You will still need dedicated opcodes, you will still need some hidden state that must be saved and restored upon all traps, but you will save a few opcode bits and the save-restore madness is gone ! So what is this so-called solution ? Add tags to each register to store the individual data type. This type could even be NULL and trigger a trap when this register is read as an operand.
The tag can be in machine-dependent format and is used by computational opcodes, that will obey the common-sense rules, such as: if you add two operands with a different type tag, trap, else store the result as the same type. Some opcodes could even change the type or inquire it.
The type will contain:
- the scalar/SIMD/vector attribute,
- integer/fixed point/floating point/whatever attribute,
- the granularity (how many bits per element)
- the overall size of the data (?)
- if the register contains a valid value
They are set by :
- load constant opcodes (explicit)
- load from memory (explicit)
- Type conversion opcodes (explicit, modify the register's content, for example float to integer)
- Type casting opcodes (explicit, doesn't touch the register's contents)
- computations/operations (implicit)
They are read by :
- computations/operations
- type read opcodes (introspection)
- trap register backup mechanism
The good :
- The code will be more flexible, more scalable
- vectoring code would be easy, and the scalar version would still work/execute.
- You don't need a separate FP or vector register set (though this could be done in practice, and you might limit the allowed types for certain registers, such as addresses)
- One computation opcode for MANY cases ! Change the register's size and the code remains the same.
- Not too intrusive when dealing with casts and conversions, if you have proper coding hygiene, unlike the LUT idea.
- Better type safety, maybe better security (even though each new feature adds complexity, bugs, misunderstandings and potential flaws).
The bad :
- Now the opcode table must specify which types it accepts, when/why it traps
- Should the opcodes trap on any type mismatch or autopromote/autocast types à la JavaScript ?
- Yes, that's more trap sources/reasons. Who wants more traps ? not me.
- That's also more opcodes to explicitly handle.
- You have to handle a type NULL ! and never mind the "whatever" needed for storing in the tagged format.
- This adds LATENCY ! This is the part that bugs me the most. You don't know at instruction fetch time if the operation is integer or FP, you need to read the register set and check the respective operand types before you can reserve or allocate an execution unit (though the instruction words could be "shadow tagged" in the cache to help loops). This wouldn't be a huge drawback with OOO though.
The overall :
It shouldn't be such a crazy undertaking for mundane code, because in C for example, the source code explicitly declares all types in advance and it would be redundant (hence space-wasting) to repeat the size all the time in the opcodes. The compiler already tracks the register widths and handles explicit type conversions. With hardware size tags, things will be a bit more funky but this will also help save other opcodes for SIMD or vectors operations, because you don't need to create a separate opcode that adds a scalar to each element of a vector (for example).
Of course, overall, the architecture moves further away from its squarely RISC roots but FC1 is also meant to be a good general-purpose number cruncher that could handle a wide variety of workload types (that are not well handled already by the #YASEP and the #YGREC8). Keeping the type separate from the opcode leaves many doors open without the risk of saturating the opcode table. You could add LNS ("Logarithmic Number System"), complex or quaternions, matrices or whatever, and the same old ADD opcode would still work. The work would be directed to the appropriate execution unit.
Another interesting effect, by saving opcodes (both from the 3 bits saved and the deduplication for each type) is that not only it has more opcodes to enjoy but also more bits for the register addresses ! If 3 bits are saved then I can bump the register set's size to 4×32 ! This would use "only" 7+5+7=19 bits :-) And there would still be 13 bits available for 2R1W operations.
.
.
.
.
PS: This thought process was rekindled by http://lists.libre-soc.org/pipermail/libre-soc-dev/2021-June/003142.html ...
-
FC1 : the memo
12/26/2020 at 00:46 • 0 commentsHere is a summary of the design so far.
FC1 or F-CPU core #1 is the successor of FC0 which was designed more than 20 years ago. You can have a look at the original F-CPU manual for an overview of the original concept and history. FC1 is a more mature version that drops the ideas that failed and introduces new ones, the FC1 instruction set is inspired but incompatible with FC0.
So many features have changed/evolved but the founding spirit remains: make a decent application processor with a fresh RISC architecture, avoid complex out-of-order circuits and instead redesign the instruction set around the problems that OOO tries to solve in HW.
FC1 is a 4-ways superscalar processor from the ground up. FC0 would require re-engineering to go superscalar and instead counted on its superpipeline (very short pipeline stages, or "the carpaccio approach") to reach high speed and throughput. The cost was more complexity, longer pipeline stages and maybe lower single-thread performance (reminiscent of the "plague of the P4"). The Low FO4 can quickly hit a logic wall and the intended granularity might have been overly optimistic.
Instead the FC1 is designed as superscalar with very fewer pipeline stages, which is easier to convert to 2-ways or 1-way issue, than the reverse. Code that is correctly compiled and scheduled will run equally well on the 3 possible implementations, though 4-ways is the most natural choice. 2 and 1 way would be interesting for gates-limited versions, such as FPGA.
Just like FC0, FC1 is an in-order processor that uses a scoreboard to stall the instructions at the decode stage if hazards are detected. To some, this is ugly and unthinkable in 2020 but the "lean philosophy" attempts to avoid feature creep that will add a considerable burden later.
Instead, the instruction set and architecture are designed to reduce the effects and causes of decode stalls. Precise exceptions, mostly from memory reference faults, are possible by splitting the classic "LOAD" or "STORE" instructions in 2:
- compute the address, TLB lookup and tag the corresponding address register
- access the data and use it as operand for another operation
The access instructions are the one to trap, once the address is known, but only if the address is referenced. This is possible by flagging the corresponding register as "invalid access" for example. This also enables prefetch, to shadow some of the latency from memory.
By the way, FC1 uses explicitly dedicated Address registers and Data registers. This reduces the complexity and overhead caused by FC0's more flexible and general approach, since now only 16 register addresses have to be flagged "invalid/ready" instead of 63.
Just like FC0, FC1 uses 64 registers though as explained above, the register set is not homogeneous, but split into 3 main functions. Just like the #YASEP and the #YGREC8, FC1 uses register-mapped memory:
- 32 "normal" registers (R0 to R31, and R0 is not hardwired to 0)
- A0 to A15 hold data addresses
- D0 to D15 are "windows" to the memory pointed by the respective address register (they can be thought as a port to the L0 memory buffers)
This is a LOT of ports to memory and the question of the relevance is legitimate (particularly since it creates a LOT of aliasing problems) but we'll see later that it also creates interesting opportunities.
If Data/Address pairs can be paired, that makes 8 blocks of dual-port L1 cache memory, a particularly high bandwidth is expected and it should be matched with eventual L2 cache and main memory bandwidth, but this is something that is not directly inside the scope of the design. Let's just say that it's less constrained than most existing designs.
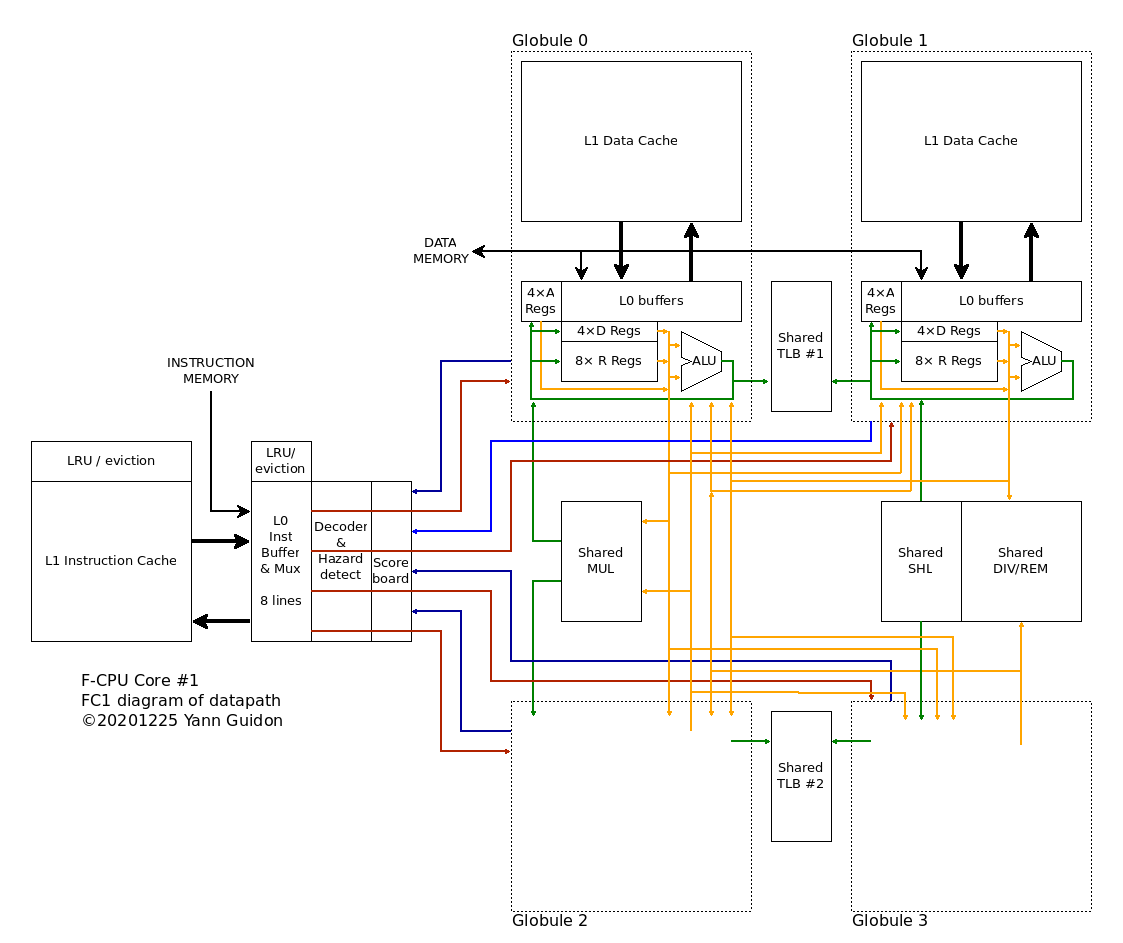
An even more radical aspect of FC1 is that the pipelines are "loosely coupled", and in fact quite decoupled. Each of the 4 pipelines has its own 2R1W register set with 16 addressable registers (8×R, 4×D, 4×A) to keep speed as high as possible. Gone is the humongous register set with 64 registers, 2 write ports and 3 read ports that was a major timing problem. Selecting only 2 operands among 16 is faster and smaller.
![]()
Each pipeline has dedicated registers and the only way to communicate between pipelines is to write the result of an operation to another target pipeline. This of course creates a hazard (and one stall cycle) but it keeps the decoder & Xbar complexity low.
The diagram above also shows that each "Globule", or pipeline+cache block, has 1 output port (wrongly tied to the source register selector) and selects input data from one of four sources : either the shared execution unit(s) or one of the 3 other globules. Two shared TLB manage the aliases, check the data that go to Address registers, while keeping cache eviction reasonable (if you manage your pointer well).
Look ma', no OOO !
The "loosely coupled" approach helps when dealing with code that would benefit from OOO but can be detected at compile time, with "sub-threads" that can be allocated to given pipelines to complete a sequence while the other pipeline(s) start a new sequence. A virtual FIFO (through the L0 instruction cache's multiple instruction pointers) lets a pipeline, or two, or three, stall during L1 cache misses, while the remaining pipeline(s) still proceed in the program's logic. While loads are big headaches (and can be managed through the A registers by early address computations), stores don't slow the program logic as long as no aliasing occurs.
Another breakthrough that is possible with a split register set is that all the pesky instructions that need more than 3 register addresses and don't fit in the clean 2R1W scenario are now handled by "paired instructions".
A pair of pipelines can now handle addition with carry, full-precision multiplies, or long-shifting with almost no effort. The same instruction is duplicated BUT the 2nd instruction specifies a destination in another pipeline (which will stall to accept the new result). This is both trap-safe (the pair of instruction can be split into 2 and be functionally equivalent despite the break of the pair at decode time) and a good use of the available resources.
The example below shows such a case of paired instructions:
; here is a pair of instructions that will be decoded and executed in parallel IMULL R01, R2, R03 ; feed back the result in the pipeline IMULH R01, R2, R13 ; send extra result in another pipelineNote that the register names are ... in octal. This is not to emulate Cray's philosophy but to ease coding: the first digit will encode the pipeline's number.
Another note on instruction encoding: both operands of an instruction are located in the same pipeline. The result can be sent to another pipeline though. As a result, one needs to encore 6+6+4=16 bits, 2 bits less than FC0 due to the explicit partitioning of the register sets. Decoding is also greatly simplified/smaller.
For paired instructions, the encoding is even smaller because some bits are implicit. The result can't be sent to another globule. A single instruction could also be used, that will be expanded by the decoder, sending the result to the opposite globule at an implicit address. The extra 3 bits can encode more options for the opcode.