 Samuel A. Falvo II
Samuel A. Falvo IIFrom the main project website:
- No back doors. No hardware locks or encryption. Open hardware means you can completely understand the hardware.
- No memberships in expensive special interest groups or trade organizations required to contribute peripherals.
- No fear of bricking your computer trying to install the OS of your choice. Bootstrap process is fully disclosed.
- Designed to empower and encourage the owner to learn about and even tweak the software and the hardware for their own benefit.
- Built on 64-bit RISC-V-compatible processor technology.
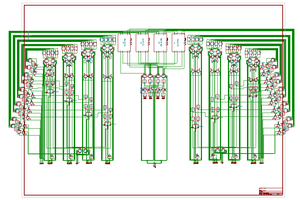
More precisely, the Kestrel-3, my third generation design, aims to be a computer just about on par with an Atari ST or Amiga 1200 computer in terms of overall performance and capability, but comparable to a Commodore 64 in terms of getting things to work.



 Noah Wood
Noah Wood
 Matt Stock
Matt Stock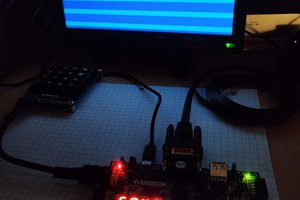
 Mad Ned
Mad Ned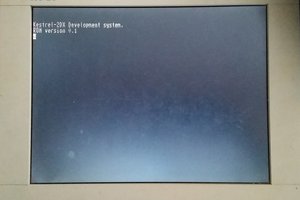
Hello,
Hackaday's blog recently posted an interesting article.
https://hackaday.com/2020/01/24/new-part-day-led-driver-is-fpga-dev-board-in-disguise/
It looks like a cheap fpga board with Gigabit Ethernet, and lots of io ports. Would it be an interesting target for Kestrel-3? It only has SDRAM on it; is that still a problem for you?
I love your work